

Commit
·
8e99b2b
verified
·
0
Parent(s):
Duplicate from PixArt-alpha/PixArt-Sigma-XL-2-1024-MS
Browse filesCo-authored-by: Chen <[email protected]>
- .gitattributes +36 -0
- README.md +131 -0
- asset/4K_image.jpg +3 -0
- asset/logo-sigma.png +0 -0
- asset/model.png +0 -0
- model_index.json +24 -0
- scheduler/scheduler_config.json +24 -0
- text_encoder/config.json +31 -0
- text_encoder/model-00001-of-00002.safetensors +3 -0
- text_encoder/model-00002-of-00002.safetensors +3 -0
- text_encoder/model.safetensors.index.json +226 -0
- tokenizer/special_tokens_map.json +107 -0
- tokenizer/spiece.model +3 -0
- tokenizer/tokenizer_config.json +112 -0
- transformer/config.json +29 -0
- transformer/diffusion_pytorch_model.safetensors +3 -0
- vae/config.json +32 -0
- vae/diffusion_pytorch_model.safetensors +3 -0
.gitattributes
ADDED
|
@@ -0,0 +1,36 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
*.7z filter=lfs diff=lfs merge=lfs -text
|
| 2 |
+
*.arrow filter=lfs diff=lfs merge=lfs -text
|
| 3 |
+
*.bin filter=lfs diff=lfs merge=lfs -text
|
| 4 |
+
*.bz2 filter=lfs diff=lfs merge=lfs -text
|
| 5 |
+
*.ckpt filter=lfs diff=lfs merge=lfs -text
|
| 6 |
+
*.ftz filter=lfs diff=lfs merge=lfs -text
|
| 7 |
+
*.gz filter=lfs diff=lfs merge=lfs -text
|
| 8 |
+
*.h5 filter=lfs diff=lfs merge=lfs -text
|
| 9 |
+
*.joblib filter=lfs diff=lfs merge=lfs -text
|
| 10 |
+
*.lfs.* filter=lfs diff=lfs merge=lfs -text
|
| 11 |
+
*.mlmodel filter=lfs diff=lfs merge=lfs -text
|
| 12 |
+
*.model filter=lfs diff=lfs merge=lfs -text
|
| 13 |
+
*.msgpack filter=lfs diff=lfs merge=lfs -text
|
| 14 |
+
*.npy filter=lfs diff=lfs merge=lfs -text
|
| 15 |
+
*.npz filter=lfs diff=lfs merge=lfs -text
|
| 16 |
+
*.onnx filter=lfs diff=lfs merge=lfs -text
|
| 17 |
+
*.ot filter=lfs diff=lfs merge=lfs -text
|
| 18 |
+
*.parquet filter=lfs diff=lfs merge=lfs -text
|
| 19 |
+
*.pb filter=lfs diff=lfs merge=lfs -text
|
| 20 |
+
*.pickle filter=lfs diff=lfs merge=lfs -text
|
| 21 |
+
*.pkl filter=lfs diff=lfs merge=lfs -text
|
| 22 |
+
*.pt filter=lfs diff=lfs merge=lfs -text
|
| 23 |
+
*.pth filter=lfs diff=lfs merge=lfs -text
|
| 24 |
+
*.rar filter=lfs diff=lfs merge=lfs -text
|
| 25 |
+
*.safetensors filter=lfs diff=lfs merge=lfs -text
|
| 26 |
+
saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
| 27 |
+
*.tar.* filter=lfs diff=lfs merge=lfs -text
|
| 28 |
+
*.tar filter=lfs diff=lfs merge=lfs -text
|
| 29 |
+
*.tflite filter=lfs diff=lfs merge=lfs -text
|
| 30 |
+
*.tgz filter=lfs diff=lfs merge=lfs -text
|
| 31 |
+
*.wasm filter=lfs diff=lfs merge=lfs -text
|
| 32 |
+
*.xz filter=lfs diff=lfs merge=lfs -text
|
| 33 |
+
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
+
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
+
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
asset/4K_image.jpg filter=lfs diff=lfs merge=lfs -text
|
README.md
ADDED
|
@@ -0,0 +1,131 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
license: openrail++
|
| 3 |
+
tags:
|
| 4 |
+
- text-to-image
|
| 5 |
+
- PixArt-Σ
|
| 6 |
+
---
|
| 7 |
+
|
| 8 |
+
<p align="center">
|
| 9 |
+
<img src="asset/logo-sigma.png" height=120>
|
| 10 |
+
</p>
|
| 11 |
+
|
| 12 |
+
<div style="display:flex;justify-content: center">
|
| 13 |
+
<a href="https://huggingface.co/spaces/PixArt-alpha/PixArt-Sigma"><img src="https://img.shields.io/static/v1?label=Demo&message=Huggingface&color=yellow"></a>  
|
| 14 |
+
<a href="https://pixart-alpha.github.io/PixArt-sigma-project/"><img src="https://img.shields.io/static/v1?label=Project%20Page&message=Github&color=blue&logo=github-pages"></a>  
|
| 15 |
+
<a href="https://arxiv.org/abs/2403.04692"><img src="https://img.shields.io/static/v1?label=Paper&message=Arxiv&color=red&logo=arxiv"></a>  
|
| 16 |
+
<a href="https://discord.gg/rde6eaE5Ta"><img src="https://img.shields.io/static/v1?label=Discuss&message=Discord&color=purple&logo=discord"></a>  
|
| 17 |
+
</div>
|
| 18 |
+
|
| 19 |
+
# 🐱 PixArt-Σ Model Card
|
| 20 |
+

|
| 21 |
+
|
| 22 |
+
## Model
|
| 23 |
+

|
| 24 |
+
|
| 25 |
+
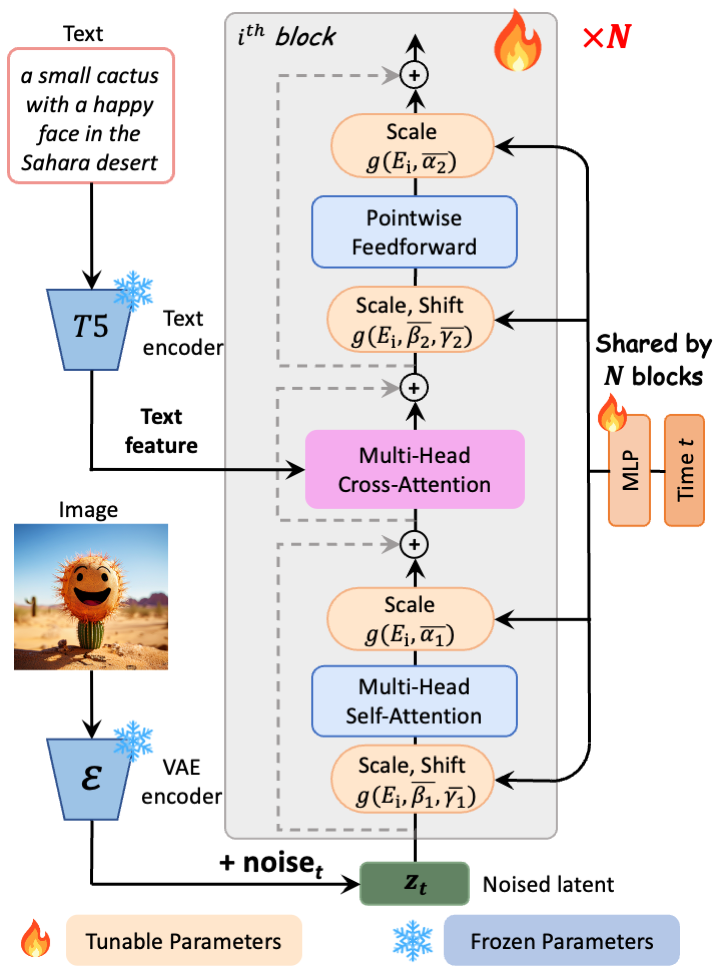
[PixArt-Σ](https://arxiv.org/abs/2403.04692) consists of pure transformer blocks for latent diffusion:
|
| 26 |
+
It can directly generate 1024px, 2K and 4K images from text prompts within a single sampling process.
|
| 27 |
+
|
| 28 |
+
Source code is available at https://github.com/PixArt-alpha/PixArt-sigma.
|
| 29 |
+
|
| 30 |
+
### Model Description
|
| 31 |
+
|
| 32 |
+
- **Developed by:** PixArt-Σ
|
| 33 |
+
- **Model type:** Diffusion-Transformer-based text-to-image generative model
|
| 34 |
+
- **License:** [CreativeML Open RAIL++-M License](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/LICENSE.md)
|
| 35 |
+
- **Model Description:** This is a model that can be used to generate and modify images based on text prompts.
|
| 36 |
+
It is a [Transformer Latent Diffusion Model](https://arxiv.org/abs/2310.00426) that uses one fixed, pretrained text encoders ([T5](
|
| 37 |
+
https://huggingface.co/DeepFloyd/t5-v1_1-xxl))
|
| 38 |
+
and one latent feature encoder ([VAE](https://arxiv.org/abs/2112.10752)).
|
| 39 |
+
- **Resources for more information:** Check out our [GitHub Repository](https://github.com/PixArt-alpha/PixArt-sigma) and the [PixArt-Σ report on arXiv](https://arxiv.org/abs/2403.04692).
|
| 40 |
+
|
| 41 |
+
### Model Sources
|
| 42 |
+
|
| 43 |
+
For research purposes, we recommend our `generative-models` Github repository (https://github.com/PixArt-alpha/PixArt-sigma),
|
| 44 |
+
which is more suitable for both training and inference and for which most advanced diffusion sampler like [SA-Solver](https://arxiv.org/abs/2309.05019) will be added over time.
|
| 45 |
+
[Hugging Face](https://huggingface.co/spaces/PixArt-alpha/PixArt-Sigma) provides free PixArt-Σ inference.
|
| 46 |
+
- **Repository:** https://github.com/PixArt-alpha/PixArt-sigma
|
| 47 |
+
- **Demo:** https://huggingface.co/spaces/PixArt-alpha/PixArt-Sigma
|
| 48 |
+
|
| 49 |
+
### 🧨 Diffusers
|
| 50 |
+
> [!IMPORTANT]
|
| 51 |
+
> Make sure to upgrade diffusers to >= 0.28.0:
|
| 52 |
+
> ```bash
|
| 53 |
+
> pip install -U diffusers --upgrade
|
| 54 |
+
> ```
|
| 55 |
+
> In addition make sure to install `transformers`, `safetensors`, `sentencepiece`, and `accelerate`:
|
| 56 |
+
> ```
|
| 57 |
+
> pip install transformers accelerate safetensors sentencepiece
|
| 58 |
+
> ```
|
| 59 |
+
> For `diffusers<0.28.0`, check this [script](https://github.com/PixArt-alpha/PixArt-sigma#2-integration-in-diffusers) for help.
|
| 60 |
+
|
| 61 |
+
To just use the base model, you can run:
|
| 62 |
+
|
| 63 |
+
```python
|
| 64 |
+
import torch
|
| 65 |
+
from diffusers import Transformer2DModel, PixArtSigmaPipeline
|
| 66 |
+
|
| 67 |
+
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
|
| 68 |
+
weight_dtype = torch.float16
|
| 69 |
+
|
| 70 |
+
pipe = PixArtSigmaPipeline.from_pretrained(
|
| 71 |
+
"PixArt-alpha/PixArt-Sigma-XL-2-1024-MS",
|
| 72 |
+
torch_dtype=weight_dtype,
|
| 73 |
+
use_safetensors=True,
|
| 74 |
+
)
|
| 75 |
+
pipe.to(device)
|
| 76 |
+
|
| 77 |
+
# Enable memory optimizations.
|
| 78 |
+
# pipe.enable_model_cpu_offload()
|
| 79 |
+
|
| 80 |
+
prompt = "A small cactus with a happy face in the Sahara desert."
|
| 81 |
+
image = pipe(prompt).images[0]
|
| 82 |
+
image.save("./catcus.png")
|
| 83 |
+
```
|
| 84 |
+
|
| 85 |
+
When using `torch >= 2.0`, you can improve the inference speed by 20-30% with torch.compile. Simple wrap the unet with torch compile before running the pipeline:
|
| 86 |
+
```py
|
| 87 |
+
pipe.transformer = torch.compile(pipe.transformer, mode="reduce-overhead", fullgraph=True)
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
If you are limited by GPU VRAM, you can enable *cpu offloading* by calling `pipe.enable_model_cpu_offload`
|
| 91 |
+
instead of `.to("cuda")`:
|
| 92 |
+
|
| 93 |
+
```diff
|
| 94 |
+
- pipe.to("cuda")
|
| 95 |
+
+ pipe.enable_model_cpu_offload()
|
| 96 |
+
```
|
| 97 |
+
|
| 98 |
+
For more information on how to use PixArt-Σ with `diffusers`, please have a look at [the PixArt-Σ Docs](https://huggingface.co/docs/diffusers/main/en/api/pipelines/pixart_sigma.md).
|
| 99 |
+
|
| 100 |
+
## Uses
|
| 101 |
+
|
| 102 |
+
### Direct Use
|
| 103 |
+
|
| 104 |
+
The model is intended for research purposes only. Possible research areas and tasks include
|
| 105 |
+
|
| 106 |
+
- Generation of artworks and use in design and other artistic processes.
|
| 107 |
+
- Applications in educational or creative tools.
|
| 108 |
+
- Research on generative models.
|
| 109 |
+
- Safe deployment of models which have the potential to generate harmful content.
|
| 110 |
+
|
| 111 |
+
- Probing and understanding the limitations and biases of generative models.
|
| 112 |
+
|
| 113 |
+
Excluded uses are described below.
|
| 114 |
+
|
| 115 |
+
### Out-of-Scope Use
|
| 116 |
+
|
| 117 |
+
The model was not trained to be factual or true representations of people or events, and therefore using the model to generate such content is out-of-scope for the abilities of this model.
|
| 118 |
+
|
| 119 |
+
## Limitations and Bias
|
| 120 |
+
|
| 121 |
+
### Limitations
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
- The model does not achieve perfect photorealism
|
| 125 |
+
- The model cannot render legible text
|
| 126 |
+
- The model struggles with more difficult tasks which involve compositionality, such as rendering an image corresponding to “A red cube on top of a blue sphere”
|
| 127 |
+
- fingers, .etc in general may not be generated properly.
|
| 128 |
+
- The autoencoding part of the model is lossy.
|
| 129 |
+
|
| 130 |
+
### Bias
|
| 131 |
+
While the capabilities of image generation models are impressive, they can also reinforce or exacerbate social biases.
|
asset/4K_image.jpg
ADDED

|
Git LFS Details
|
asset/logo-sigma.png
ADDED
|
|
asset/model.png
ADDED
|
model_index.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "PixArtSigmaPipeline",
|
| 3 |
+
"_diffusers_version": "0.28.0.dev0",
|
| 4 |
+
"scheduler": [
|
| 5 |
+
"diffusers",
|
| 6 |
+
"DPMSolverMultistepScheduler"
|
| 7 |
+
],
|
| 8 |
+
"text_encoder": [
|
| 9 |
+
"transformers",
|
| 10 |
+
"T5EncoderModel"
|
| 11 |
+
],
|
| 12 |
+
"tokenizer": [
|
| 13 |
+
"transformers",
|
| 14 |
+
"T5Tokenizer"
|
| 15 |
+
],
|
| 16 |
+
"transformer": [
|
| 17 |
+
"diffusers",
|
| 18 |
+
"Transformer2DModel"
|
| 19 |
+
],
|
| 20 |
+
"vae": [
|
| 21 |
+
"diffusers",
|
| 22 |
+
"AutoencoderKL"
|
| 23 |
+
]
|
| 24 |
+
}
|
scheduler/scheduler_config.json
ADDED
|
@@ -0,0 +1,24 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "DPMSolverMultistepScheduler",
|
| 3 |
+
"_diffusers_version": "0.22.0.dev0",
|
| 4 |
+
"algorithm_type": "dpmsolver++",
|
| 5 |
+
"beta_end": 0.02,
|
| 6 |
+
"beta_schedule": "linear",
|
| 7 |
+
"beta_start": 0.0001,
|
| 8 |
+
"dynamic_thresholding_ratio": 0.995,
|
| 9 |
+
"euler_at_final": false,
|
| 10 |
+
"lambda_min_clipped": -Infinity,
|
| 11 |
+
"lower_order_final": true,
|
| 12 |
+
"num_train_timesteps": 1000,
|
| 13 |
+
"prediction_type": "epsilon",
|
| 14 |
+
"sample_max_value": 1.0,
|
| 15 |
+
"solver_order": 2,
|
| 16 |
+
"solver_type": "midpoint",
|
| 17 |
+
"steps_offset": 0,
|
| 18 |
+
"thresholding": false,
|
| 19 |
+
"timestep_spacing": "linspace",
|
| 20 |
+
"trained_betas": null,
|
| 21 |
+
"use_karras_sigmas": false,
|
| 22 |
+
"use_lu_lambdas": false,
|
| 23 |
+
"variance_type": null
|
| 24 |
+
}
|
text_encoder/config.json
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_name_or_path": "data/t5_ckpts",
|
| 3 |
+
"architectures": [
|
| 4 |
+
"T5EncoderModel"
|
| 5 |
+
],
|
| 6 |
+
"d_ff": 10240,
|
| 7 |
+
"d_kv": 64,
|
| 8 |
+
"d_model": 4096,
|
| 9 |
+
"decoder_start_token_id": 0,
|
| 10 |
+
"dense_act_fn": "gelu_new",
|
| 11 |
+
"dropout_rate": 0.1,
|
| 12 |
+
"eos_token_id": 1,
|
| 13 |
+
"feed_forward_proj": "gated-gelu",
|
| 14 |
+
"initializer_factor": 1.0,
|
| 15 |
+
"is_encoder_decoder": true,
|
| 16 |
+
"is_gated_act": true,
|
| 17 |
+
"layer_norm_epsilon": 1e-06,
|
| 18 |
+
"model_type": "t5",
|
| 19 |
+
"num_decoder_layers": 24,
|
| 20 |
+
"num_heads": 64,
|
| 21 |
+
"num_layers": 24,
|
| 22 |
+
"output_past": true,
|
| 23 |
+
"pad_token_id": 0,
|
| 24 |
+
"relative_attention_max_distance": 128,
|
| 25 |
+
"relative_attention_num_buckets": 32,
|
| 26 |
+
"tie_word_embeddings": false,
|
| 27 |
+
"torch_dtype": "float32",
|
| 28 |
+
"transformers_version": "4.30.0",
|
| 29 |
+
"use_cache": true,
|
| 30 |
+
"vocab_size": 32128
|
| 31 |
+
}
|
text_encoder/model-00001-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:eb529f693f4b17773a24e787fcba29486d5e1700dadcc20bb91e4c8b00212d08
|
| 3 |
+
size 9989150328
|
text_encoder/model-00002-of-00002.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:58f33f4acba7a5502b6b3e4cb7863f8fd503d5012016428099bb460c98e2fe77
|
| 3 |
+
size 9060119392
|
text_encoder/model.safetensors.index.json
ADDED
|
@@ -0,0 +1,226 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"metadata": {
|
| 3 |
+
"total_size": 19049242624
|
| 4 |
+
},
|
| 5 |
+
"weight_map": {
|
| 6 |
+
"encoder.block.0.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 7 |
+
"encoder.block.0.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 8 |
+
"encoder.block.0.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 9 |
+
"encoder.block.0.layer.0.SelfAttention.relative_attention_bias.weight": "model-00001-of-00002.safetensors",
|
| 10 |
+
"encoder.block.0.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 11 |
+
"encoder.block.0.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 12 |
+
"encoder.block.0.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 13 |
+
"encoder.block.0.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 14 |
+
"encoder.block.0.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 15 |
+
"encoder.block.0.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 16 |
+
"encoder.block.1.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 17 |
+
"encoder.block.1.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 18 |
+
"encoder.block.1.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 19 |
+
"encoder.block.1.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 20 |
+
"encoder.block.1.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 21 |
+
"encoder.block.1.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 22 |
+
"encoder.block.1.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 23 |
+
"encoder.block.1.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 24 |
+
"encoder.block.1.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 25 |
+
"encoder.block.10.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 26 |
+
"encoder.block.10.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 27 |
+
"encoder.block.10.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 28 |
+
"encoder.block.10.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 29 |
+
"encoder.block.10.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 30 |
+
"encoder.block.10.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 31 |
+
"encoder.block.10.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 32 |
+
"encoder.block.10.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 33 |
+
"encoder.block.10.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 34 |
+
"encoder.block.11.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 35 |
+
"encoder.block.11.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 36 |
+
"encoder.block.11.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 37 |
+
"encoder.block.11.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 38 |
+
"encoder.block.11.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 39 |
+
"encoder.block.11.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 40 |
+
"encoder.block.11.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 41 |
+
"encoder.block.11.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 42 |
+
"encoder.block.11.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 43 |
+
"encoder.block.12.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 44 |
+
"encoder.block.12.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 45 |
+
"encoder.block.12.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 46 |
+
"encoder.block.12.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 47 |
+
"encoder.block.12.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 48 |
+
"encoder.block.12.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 49 |
+
"encoder.block.12.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 50 |
+
"encoder.block.12.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 51 |
+
"encoder.block.12.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 52 |
+
"encoder.block.13.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 53 |
+
"encoder.block.13.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 54 |
+
"encoder.block.13.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 55 |
+
"encoder.block.13.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 56 |
+
"encoder.block.13.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 57 |
+
"encoder.block.13.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 58 |
+
"encoder.block.13.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 59 |
+
"encoder.block.13.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 60 |
+
"encoder.block.13.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 61 |
+
"encoder.block.14.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 62 |
+
"encoder.block.14.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 63 |
+
"encoder.block.14.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 64 |
+
"encoder.block.14.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 65 |
+
"encoder.block.14.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 66 |
+
"encoder.block.14.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 67 |
+
"encoder.block.14.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 68 |
+
"encoder.block.14.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 69 |
+
"encoder.block.14.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 70 |
+
"encoder.block.15.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 71 |
+
"encoder.block.15.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 72 |
+
"encoder.block.15.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 73 |
+
"encoder.block.15.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 74 |
+
"encoder.block.15.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 75 |
+
"encoder.block.15.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 76 |
+
"encoder.block.15.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 77 |
+
"encoder.block.15.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 78 |
+
"encoder.block.15.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 79 |
+
"encoder.block.16.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 80 |
+
"encoder.block.16.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 81 |
+
"encoder.block.16.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 82 |
+
"encoder.block.16.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 83 |
+
"encoder.block.16.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 84 |
+
"encoder.block.16.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 85 |
+
"encoder.block.16.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 86 |
+
"encoder.block.16.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 87 |
+
"encoder.block.16.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 88 |
+
"encoder.block.17.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 89 |
+
"encoder.block.17.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 90 |
+
"encoder.block.17.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 91 |
+
"encoder.block.17.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 92 |
+
"encoder.block.17.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 93 |
+
"encoder.block.17.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 94 |
+
"encoder.block.17.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 95 |
+
"encoder.block.17.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 96 |
+
"encoder.block.17.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 97 |
+
"encoder.block.18.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 98 |
+
"encoder.block.18.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 99 |
+
"encoder.block.18.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 100 |
+
"encoder.block.18.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 101 |
+
"encoder.block.18.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 102 |
+
"encoder.block.18.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 103 |
+
"encoder.block.18.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 104 |
+
"encoder.block.18.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 105 |
+
"encoder.block.18.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 106 |
+
"encoder.block.19.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 107 |
+
"encoder.block.19.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 108 |
+
"encoder.block.19.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 109 |
+
"encoder.block.19.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 110 |
+
"encoder.block.19.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 111 |
+
"encoder.block.19.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 112 |
+
"encoder.block.19.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 113 |
+
"encoder.block.19.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 114 |
+
"encoder.block.19.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 115 |
+
"encoder.block.2.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 116 |
+
"encoder.block.2.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 117 |
+
"encoder.block.2.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 118 |
+
"encoder.block.2.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 119 |
+
"encoder.block.2.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 120 |
+
"encoder.block.2.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 121 |
+
"encoder.block.2.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 122 |
+
"encoder.block.2.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 123 |
+
"encoder.block.2.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 124 |
+
"encoder.block.20.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 125 |
+
"encoder.block.20.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 126 |
+
"encoder.block.20.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 127 |
+
"encoder.block.20.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 128 |
+
"encoder.block.20.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 129 |
+
"encoder.block.20.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 130 |
+
"encoder.block.20.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 131 |
+
"encoder.block.20.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 132 |
+
"encoder.block.20.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 133 |
+
"encoder.block.21.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 134 |
+
"encoder.block.21.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 135 |
+
"encoder.block.21.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 136 |
+
"encoder.block.21.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 137 |
+
"encoder.block.21.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 138 |
+
"encoder.block.21.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 139 |
+
"encoder.block.21.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 140 |
+
"encoder.block.21.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 141 |
+
"encoder.block.21.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 142 |
+
"encoder.block.22.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 143 |
+
"encoder.block.22.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 144 |
+
"encoder.block.22.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 145 |
+
"encoder.block.22.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 146 |
+
"encoder.block.22.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 147 |
+
"encoder.block.22.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 148 |
+
"encoder.block.22.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 149 |
+
"encoder.block.22.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 150 |
+
"encoder.block.22.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 151 |
+
"encoder.block.23.layer.0.SelfAttention.k.weight": "model-00002-of-00002.safetensors",
|
| 152 |
+
"encoder.block.23.layer.0.SelfAttention.o.weight": "model-00002-of-00002.safetensors",
|
| 153 |
+
"encoder.block.23.layer.0.SelfAttention.q.weight": "model-00002-of-00002.safetensors",
|
| 154 |
+
"encoder.block.23.layer.0.SelfAttention.v.weight": "model-00002-of-00002.safetensors",
|
| 155 |
+
"encoder.block.23.layer.0.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 156 |
+
"encoder.block.23.layer.1.DenseReluDense.wi_0.weight": "model-00002-of-00002.safetensors",
|
| 157 |
+
"encoder.block.23.layer.1.DenseReluDense.wi_1.weight": "model-00002-of-00002.safetensors",
|
| 158 |
+
"encoder.block.23.layer.1.DenseReluDense.wo.weight": "model-00002-of-00002.safetensors",
|
| 159 |
+
"encoder.block.23.layer.1.layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 160 |
+
"encoder.block.3.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 161 |
+
"encoder.block.3.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 162 |
+
"encoder.block.3.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 163 |
+
"encoder.block.3.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 164 |
+
"encoder.block.3.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 165 |
+
"encoder.block.3.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 166 |
+
"encoder.block.3.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 167 |
+
"encoder.block.3.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 168 |
+
"encoder.block.3.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 169 |
+
"encoder.block.4.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 170 |
+
"encoder.block.4.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 171 |
+
"encoder.block.4.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 172 |
+
"encoder.block.4.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 173 |
+
"encoder.block.4.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 174 |
+
"encoder.block.4.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 175 |
+
"encoder.block.4.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 176 |
+
"encoder.block.4.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 177 |
+
"encoder.block.4.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 178 |
+
"encoder.block.5.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 179 |
+
"encoder.block.5.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 180 |
+
"encoder.block.5.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 181 |
+
"encoder.block.5.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 182 |
+
"encoder.block.5.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 183 |
+
"encoder.block.5.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 184 |
+
"encoder.block.5.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 185 |
+
"encoder.block.5.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 186 |
+
"encoder.block.5.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 187 |
+
"encoder.block.6.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 188 |
+
"encoder.block.6.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 189 |
+
"encoder.block.6.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 190 |
+
"encoder.block.6.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 191 |
+
"encoder.block.6.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 192 |
+
"encoder.block.6.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 193 |
+
"encoder.block.6.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 194 |
+
"encoder.block.6.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 195 |
+
"encoder.block.6.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 196 |
+
"encoder.block.7.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 197 |
+
"encoder.block.7.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 198 |
+
"encoder.block.7.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 199 |
+
"encoder.block.7.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 200 |
+
"encoder.block.7.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 201 |
+
"encoder.block.7.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 202 |
+
"encoder.block.7.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 203 |
+
"encoder.block.7.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 204 |
+
"encoder.block.7.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 205 |
+
"encoder.block.8.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 206 |
+
"encoder.block.8.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 207 |
+
"encoder.block.8.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 208 |
+
"encoder.block.8.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 209 |
+
"encoder.block.8.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 210 |
+
"encoder.block.8.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 211 |
+
"encoder.block.8.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 212 |
+
"encoder.block.8.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 213 |
+
"encoder.block.8.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 214 |
+
"encoder.block.9.layer.0.SelfAttention.k.weight": "model-00001-of-00002.safetensors",
|
| 215 |
+
"encoder.block.9.layer.0.SelfAttention.o.weight": "model-00001-of-00002.safetensors",
|
| 216 |
+
"encoder.block.9.layer.0.SelfAttention.q.weight": "model-00001-of-00002.safetensors",
|
| 217 |
+
"encoder.block.9.layer.0.SelfAttention.v.weight": "model-00001-of-00002.safetensors",
|
| 218 |
+
"encoder.block.9.layer.0.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 219 |
+
"encoder.block.9.layer.1.DenseReluDense.wi_0.weight": "model-00001-of-00002.safetensors",
|
| 220 |
+
"encoder.block.9.layer.1.DenseReluDense.wi_1.weight": "model-00001-of-00002.safetensors",
|
| 221 |
+
"encoder.block.9.layer.1.DenseReluDense.wo.weight": "model-00001-of-00002.safetensors",
|
| 222 |
+
"encoder.block.9.layer.1.layer_norm.weight": "model-00001-of-00002.safetensors",
|
| 223 |
+
"encoder.final_layer_norm.weight": "model-00002-of-00002.safetensors",
|
| 224 |
+
"shared.weight": "model-00001-of-00002.safetensors"
|
| 225 |
+
}
|
| 226 |
+
}
|
tokenizer/special_tokens_map.json
ADDED
|
@@ -0,0 +1,107 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<extra_id_0>",
|
| 4 |
+
"<extra_id_1>",
|
| 5 |
+
"<extra_id_2>",
|
| 6 |
+
"<extra_id_3>",
|
| 7 |
+
"<extra_id_4>",
|
| 8 |
+
"<extra_id_5>",
|
| 9 |
+
"<extra_id_6>",
|
| 10 |
+
"<extra_id_7>",
|
| 11 |
+
"<extra_id_8>",
|
| 12 |
+
"<extra_id_9>",
|
| 13 |
+
"<extra_id_10>",
|
| 14 |
+
"<extra_id_11>",
|
| 15 |
+
"<extra_id_12>",
|
| 16 |
+
"<extra_id_13>",
|
| 17 |
+
"<extra_id_14>",
|
| 18 |
+
"<extra_id_15>",
|
| 19 |
+
"<extra_id_16>",
|
| 20 |
+
"<extra_id_17>",
|
| 21 |
+
"<extra_id_18>",
|
| 22 |
+
"<extra_id_19>",
|
| 23 |
+
"<extra_id_20>",
|
| 24 |
+
"<extra_id_21>",
|
| 25 |
+
"<extra_id_22>",
|
| 26 |
+
"<extra_id_23>",
|
| 27 |
+
"<extra_id_24>",
|
| 28 |
+
"<extra_id_25>",
|
| 29 |
+
"<extra_id_26>",
|
| 30 |
+
"<extra_id_27>",
|
| 31 |
+
"<extra_id_28>",
|
| 32 |
+
"<extra_id_29>",
|
| 33 |
+
"<extra_id_30>",
|
| 34 |
+
"<extra_id_31>",
|
| 35 |
+
"<extra_id_32>",
|
| 36 |
+
"<extra_id_33>",
|
| 37 |
+
"<extra_id_34>",
|
| 38 |
+
"<extra_id_35>",
|
| 39 |
+
"<extra_id_36>",
|
| 40 |
+
"<extra_id_37>",
|
| 41 |
+
"<extra_id_38>",
|
| 42 |
+
"<extra_id_39>",
|
| 43 |
+
"<extra_id_40>",
|
| 44 |
+
"<extra_id_41>",
|
| 45 |
+
"<extra_id_42>",
|
| 46 |
+
"<extra_id_43>",
|
| 47 |
+
"<extra_id_44>",
|
| 48 |
+
"<extra_id_45>",
|
| 49 |
+
"<extra_id_46>",
|
| 50 |
+
"<extra_id_47>",
|
| 51 |
+
"<extra_id_48>",
|
| 52 |
+
"<extra_id_49>",
|
| 53 |
+
"<extra_id_50>",
|
| 54 |
+
"<extra_id_51>",
|
| 55 |
+
"<extra_id_52>",
|
| 56 |
+
"<extra_id_53>",
|
| 57 |
+
"<extra_id_54>",
|
| 58 |
+
"<extra_id_55>",
|
| 59 |
+
"<extra_id_56>",
|
| 60 |
+
"<extra_id_57>",
|
| 61 |
+
"<extra_id_58>",
|
| 62 |
+
"<extra_id_59>",
|
| 63 |
+
"<extra_id_60>",
|
| 64 |
+
"<extra_id_61>",
|
| 65 |
+
"<extra_id_62>",
|
| 66 |
+
"<extra_id_63>",
|
| 67 |
+
"<extra_id_64>",
|
| 68 |
+
"<extra_id_65>",
|
| 69 |
+
"<extra_id_66>",
|
| 70 |
+
"<extra_id_67>",
|
| 71 |
+
"<extra_id_68>",
|
| 72 |
+
"<extra_id_69>",
|
| 73 |
+
"<extra_id_70>",
|
| 74 |
+
"<extra_id_71>",
|
| 75 |
+
"<extra_id_72>",
|
| 76 |
+
"<extra_id_73>",
|
| 77 |
+
"<extra_id_74>",
|
| 78 |
+
"<extra_id_75>",
|
| 79 |
+
"<extra_id_76>",
|
| 80 |
+
"<extra_id_77>",
|
| 81 |
+
"<extra_id_78>",
|
| 82 |
+
"<extra_id_79>",
|
| 83 |
+
"<extra_id_80>",
|
| 84 |
+
"<extra_id_81>",
|
| 85 |
+
"<extra_id_82>",
|
| 86 |
+
"<extra_id_83>",
|
| 87 |
+
"<extra_id_84>",
|
| 88 |
+
"<extra_id_85>",
|
| 89 |
+
"<extra_id_86>",
|
| 90 |
+
"<extra_id_87>",
|
| 91 |
+
"<extra_id_88>",
|
| 92 |
+
"<extra_id_89>",
|
| 93 |
+
"<extra_id_90>",
|
| 94 |
+
"<extra_id_91>",
|
| 95 |
+
"<extra_id_92>",
|
| 96 |
+
"<extra_id_93>",
|
| 97 |
+
"<extra_id_94>",
|
| 98 |
+
"<extra_id_95>",
|
| 99 |
+
"<extra_id_96>",
|
| 100 |
+
"<extra_id_97>",
|
| 101 |
+
"<extra_id_98>",
|
| 102 |
+
"<extra_id_99>"
|
| 103 |
+
],
|
| 104 |
+
"eos_token": "</s>",
|
| 105 |
+
"pad_token": "<pad>",
|
| 106 |
+
"unk_token": "<unk>"
|
| 107 |
+
}
|
tokenizer/spiece.model
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:d60acb128cf7b7f2536e8f38a5b18a05535c9e14c7a355904270e15b0945ea86
|
| 3 |
+
size 791656
|
tokenizer/tokenizer_config.json
ADDED
|
@@ -0,0 +1,112 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"additional_special_tokens": [
|
| 3 |
+
"<extra_id_0>",
|
| 4 |
+
"<extra_id_1>",
|
| 5 |
+
"<extra_id_2>",
|
| 6 |
+
"<extra_id_3>",
|
| 7 |
+
"<extra_id_4>",
|
| 8 |
+
"<extra_id_5>",
|
| 9 |
+
"<extra_id_6>",
|
| 10 |
+
"<extra_id_7>",
|
| 11 |
+
"<extra_id_8>",
|
| 12 |
+
"<extra_id_9>",
|
| 13 |
+
"<extra_id_10>",
|
| 14 |
+
"<extra_id_11>",
|
| 15 |
+
"<extra_id_12>",
|
| 16 |
+
"<extra_id_13>",
|
| 17 |
+
"<extra_id_14>",
|
| 18 |
+
"<extra_id_15>",
|
| 19 |
+
"<extra_id_16>",
|
| 20 |
+
"<extra_id_17>",
|
| 21 |
+
"<extra_id_18>",
|
| 22 |
+
"<extra_id_19>",
|
| 23 |
+
"<extra_id_20>",
|
| 24 |
+
"<extra_id_21>",
|
| 25 |
+
"<extra_id_22>",
|
| 26 |
+
"<extra_id_23>",
|
| 27 |
+
"<extra_id_24>",
|
| 28 |
+
"<extra_id_25>",
|
| 29 |
+
"<extra_id_26>",
|
| 30 |
+
"<extra_id_27>",
|
| 31 |
+
"<extra_id_28>",
|
| 32 |
+
"<extra_id_29>",
|
| 33 |
+
"<extra_id_30>",
|
| 34 |
+
"<extra_id_31>",
|
| 35 |
+
"<extra_id_32>",
|
| 36 |
+
"<extra_id_33>",
|
| 37 |
+
"<extra_id_34>",
|
| 38 |
+
"<extra_id_35>",
|
| 39 |
+
"<extra_id_36>",
|
| 40 |
+
"<extra_id_37>",
|
| 41 |
+
"<extra_id_38>",
|
| 42 |
+
"<extra_id_39>",
|
| 43 |
+
"<extra_id_40>",
|
| 44 |
+
"<extra_id_41>",
|
| 45 |
+
"<extra_id_42>",
|
| 46 |
+
"<extra_id_43>",
|
| 47 |
+
"<extra_id_44>",
|
| 48 |
+
"<extra_id_45>",
|
| 49 |
+
"<extra_id_46>",
|
| 50 |
+
"<extra_id_47>",
|
| 51 |
+
"<extra_id_48>",
|
| 52 |
+
"<extra_id_49>",
|
| 53 |
+
"<extra_id_50>",
|
| 54 |
+
"<extra_id_51>",
|
| 55 |
+
"<extra_id_52>",
|
| 56 |
+
"<extra_id_53>",
|
| 57 |
+
"<extra_id_54>",
|
| 58 |
+
"<extra_id_55>",
|
| 59 |
+
"<extra_id_56>",
|
| 60 |
+
"<extra_id_57>",
|
| 61 |
+
"<extra_id_58>",
|
| 62 |
+
"<extra_id_59>",
|
| 63 |
+
"<extra_id_60>",
|
| 64 |
+
"<extra_id_61>",
|
| 65 |
+
"<extra_id_62>",
|
| 66 |
+
"<extra_id_63>",
|
| 67 |
+
"<extra_id_64>",
|
| 68 |
+
"<extra_id_65>",
|
| 69 |
+
"<extra_id_66>",
|
| 70 |
+
"<extra_id_67>",
|
| 71 |
+
"<extra_id_68>",
|
| 72 |
+
"<extra_id_69>",
|
| 73 |
+
"<extra_id_70>",
|
| 74 |
+
"<extra_id_71>",
|
| 75 |
+
"<extra_id_72>",
|
| 76 |
+
"<extra_id_73>",
|
| 77 |
+
"<extra_id_74>",
|
| 78 |
+
"<extra_id_75>",
|
| 79 |
+
"<extra_id_76>",
|
| 80 |
+
"<extra_id_77>",
|
| 81 |
+
"<extra_id_78>",
|
| 82 |
+
"<extra_id_79>",
|
| 83 |
+
"<extra_id_80>",
|
| 84 |
+
"<extra_id_81>",
|
| 85 |
+
"<extra_id_82>",
|
| 86 |
+
"<extra_id_83>",
|
| 87 |
+
"<extra_id_84>",
|
| 88 |
+
"<extra_id_85>",
|
| 89 |
+
"<extra_id_86>",
|
| 90 |
+
"<extra_id_87>",
|
| 91 |
+
"<extra_id_88>",
|
| 92 |
+
"<extra_id_89>",
|
| 93 |
+
"<extra_id_90>",
|
| 94 |
+
"<extra_id_91>",
|
| 95 |
+
"<extra_id_92>",
|
| 96 |
+
"<extra_id_93>",
|
| 97 |
+
"<extra_id_94>",
|
| 98 |
+
"<extra_id_95>",
|
| 99 |
+
"<extra_id_96>",
|
| 100 |
+
"<extra_id_97>",
|
| 101 |
+
"<extra_id_98>",
|
| 102 |
+
"<extra_id_99>"
|
| 103 |
+
],
|
| 104 |
+
"clean_up_tokenization_spaces": true,
|
| 105 |
+
"eos_token": "</s>",
|
| 106 |
+
"extra_ids": 100,
|
| 107 |
+
"model_max_length": 512,
|
| 108 |
+
"pad_token": "<pad>",
|
| 109 |
+
"sp_model_kwargs": {},
|
| 110 |
+
"tokenizer_class": "T5Tokenizer",
|
| 111 |
+
"unk_token": "<unk>"
|
| 112 |
+
}
|
transformer/config.json
ADDED
|
@@ -0,0 +1,29 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "Transformer2DModel",
|
| 3 |
+
"_diffusers_version": "0.28.0.dev0",
|
| 4 |
+
"activation_fn": "gelu-approximate",
|
| 5 |
+
"attention_bias": true,
|
| 6 |
+
"attention_head_dim": 72,
|
| 7 |
+
"attention_type": "default",
|
| 8 |
+
"caption_channels": 4096,
|
| 9 |
+
"cross_attention_dim": 1152,
|
| 10 |
+
"double_self_attention": false,
|
| 11 |
+
"dropout": 0.0,
|
| 12 |
+
"in_channels": 4,
|
| 13 |
+
"interpolation_scale": 2,
|
| 14 |
+
"norm_elementwise_affine": false,
|
| 15 |
+
"norm_eps": 1e-06,
|
| 16 |
+
"norm_num_groups": 32,
|
| 17 |
+
"norm_type": "ada_norm_single",
|
| 18 |
+
"num_attention_heads": 16,
|
| 19 |
+
"num_embeds_ada_norm": 1000,
|
| 20 |
+
"num_layers": 28,
|
| 21 |
+
"num_vector_embeds": null,
|
| 22 |
+
"only_cross_attention": false,
|
| 23 |
+
"out_channels": 8,
|
| 24 |
+
"patch_size": 2,
|
| 25 |
+
"sample_size": 128,
|
| 26 |
+
"upcast_attention": false,
|
| 27 |
+
"use_additional_conditions": false,
|
| 28 |
+
"use_linear_projection": false
|
| 29 |
+
}
|
transformer/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2fa4dee9229c02b03163f57bdb8e80c7a5ee364b7161796abe9c05e8dd13f239
|
| 3 |
+
size 2443492488
|
vae/config.json
ADDED
|
@@ -0,0 +1,32 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{
|
| 2 |
+
"_class_name": "AutoencoderKL",
|
| 3 |
+
"_diffusers_version": "0.18.0.dev0",
|
| 4 |
+
"_name_or_path": ".",
|
| 5 |
+
"act_fn": "silu",
|
| 6 |
+
"block_out_channels": [
|
| 7 |
+
128,
|
| 8 |
+
256,
|
| 9 |
+
512,
|
| 10 |
+
512
|
| 11 |
+
],
|
| 12 |
+
"down_block_types": [
|
| 13 |
+
"DownEncoderBlock2D",
|
| 14 |
+
"DownEncoderBlock2D",
|
| 15 |
+
"DownEncoderBlock2D",
|
| 16 |
+
"DownEncoderBlock2D"
|
| 17 |
+
],
|
| 18 |
+
"in_channels": 3,
|
| 19 |
+
"latent_channels": 4,
|
| 20 |
+
"layers_per_block": 2,
|
| 21 |
+
"norm_num_groups": 32,
|
| 22 |
+
"out_channels": 3,
|
| 23 |
+
"sample_size": 512,
|
| 24 |
+
"scaling_factor": 0.13025,
|
| 25 |
+
"up_block_types": [
|
| 26 |
+
"UpDecoderBlock2D",
|
| 27 |
+
"UpDecoderBlock2D",
|
| 28 |
+
"UpDecoderBlock2D",
|
| 29 |
+
"UpDecoderBlock2D"
|
| 30 |
+
],
|
| 31 |
+
"force_upcast": false
|
| 32 |
+
}
|
vae/diffusion_pytorch_model.safetensors
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:1b909373b28f2137098b0fd9dbc6f97f8410854f31f84ddc9fa04b077b0ace2c
|
| 3 |
+
size 334643238
|