
Kandinsky 5.0 T2I Lite SFT – Diffusers
Kandinsky 5.0 is a family of diffusion models for video and image generation.
Kandinsky 5.0 Image Lite is a lightweight text-to-image (T2I) generation model with 6B parameters.
The model introduces several key innovations:
- Latent diffusion pipeline with Flow Matching for improved training stability
- Diffusion Transformer (DiT) as the main generative backbone with cross-attention to text embeddings
- Dual text encoding using Qwen2.5-VL and CLIP for comprehensive text understanding
- Flux VAE for efficient image encoding and decoding
The original codebase can be found at kandinskylab/Kandinsky-5.
Available Models
Kandinsky 5.0 Image Lite:
| model_id | Description | Use Cases |
|---|---|---|
| kandinskylab/Kandinsky-5.0-T2I-Lite-sft-Diffusers | 6B supervised fine-tuned text-to-image model | Highest generation quality |
| kandinskylab/Kandinsky-5.0-I2I-Lite-sft-Diffusers | 6B supervised fine-tuned image-to-image editing model | Highest generation quality |
| kandinskylab/Kandinsky-5.0-T2I-Lite-pretrain-Diffusers | 6B base pretrained text-to-image model | Research and fine-tuning |
| kandinskylab/Kandinsky-5.0-I2I-Lite-pretrain-Diffusers | 6B base pretrained image-to-image editing model | Research and fine-tuning |
Examples

|

|

|

|

|

|

|

|

|
Kandinsky5T2IPipeline Usage Example
import torch
from diffusers import Kandinsky5T2IPipeline
# Load the pipeline
model_id = "kandinskylab/Kandinsky-5.0-T2I-Lite-sft-Diffusers"
pipe = Kandinsky5T2IPipeline.from_pretrained(model_id)
_ = pipe.to(device="cuda", dtype=torch.bfloat16)
# Generate image
prompt = "A fluffy, expressive cat wearing a bright red hat with a soft, slightly textured fabric. The hat should look cozy and well-fitted on the cat’s head. On the front of the hat, add clean, bold white text that reads “SWEET”, clearly visible and neatly centered. Ensure the overall lighting highlights the hat’s color and the cat’s fur details."
output = pipe(
prompt=prompt,
negative_prompt="",
height=1024,
width=1024,
num_inference_steps=50,
guidance_scale=3.5,
).image[0]
Results
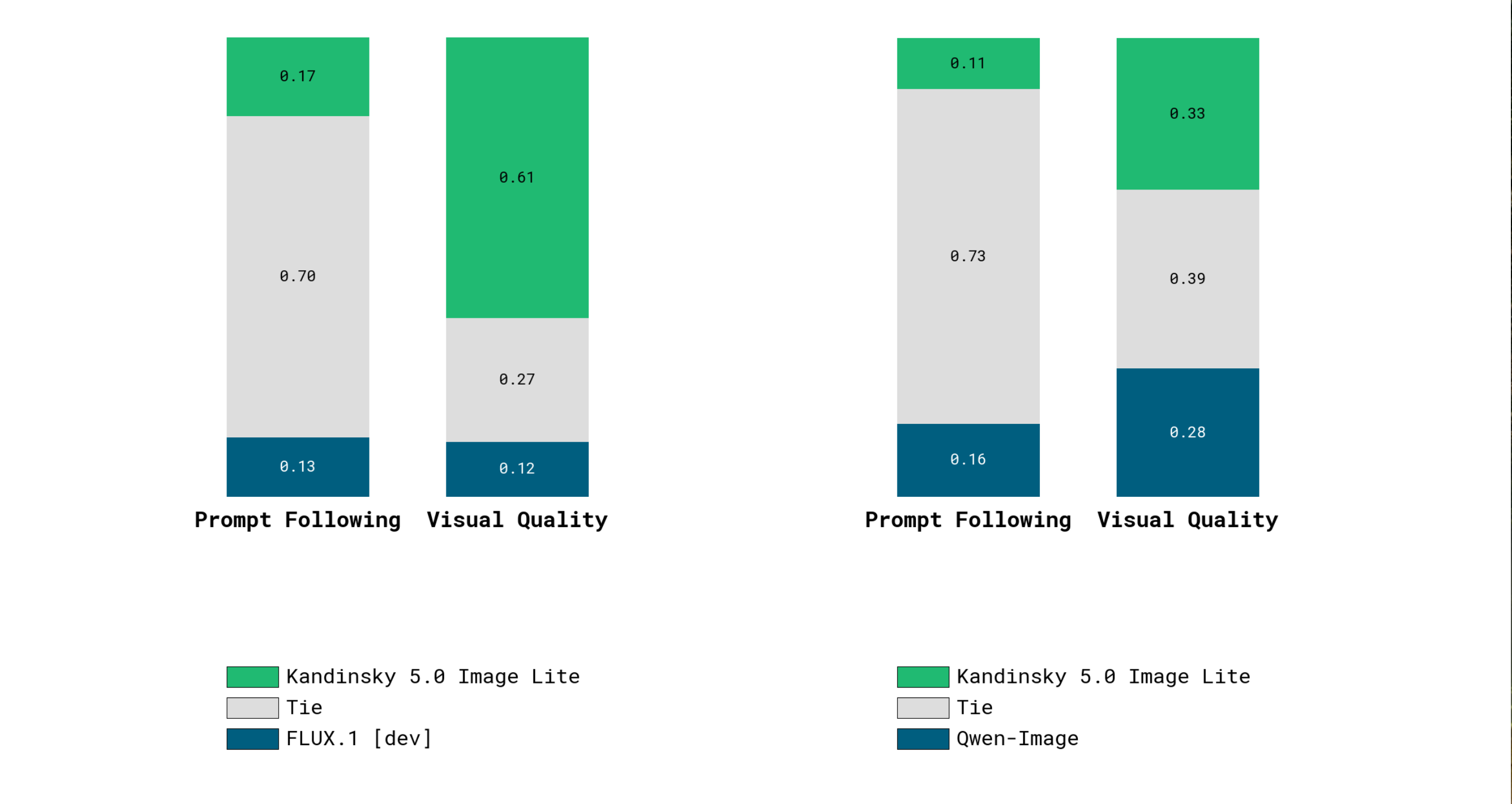
|

|
| Side-by-side evaluation of T2I on PartiPrompts with extended prompts | Side-by-side evaluation of I2I on the Flux Kontext benchmark with extended prompts |
Citation
@misc{kandinsky2025,
author = {Alexander Belykh and Alexander Varlamov and Alexey Letunovskiy and Anastasia Aliaskina and Anastasia Maltseva and Anastasiia Kargapoltseva and Andrey Shutkin and Anna Averchenkova and Anna Dmitrienko and Bulat Akhmatov and Denis Dimitrov and Denis Koposov and Denis Parkhomenko and Dmitrii and Ilya Vasiliev and Ivan Kirillov and Julia Agafonova and Kirill Chernyshev and Kormilitsyn Semen and Lev Novitskiy and Maria Kovaleva and Mikhail Mamaev and Mikhailov and Nikita Kiselev and Nikita Osterov and Nikolai Gerasimenko and Nikolai Vaulin and Olga Kim and Olga Vdovchenko and Polina Gavrilova and Polina Mikhailova and Tatiana Nikulina and Viacheslav Vasilev and Vladimir Arkhipkin and Vladimir Korviakov and Vladimir Polovnikov and Yury Kolabushin},
title = {Kandinsky 5.0: A family of diffusion models for Video & Image generation},
howpublished = {\url{https://github.com/kandinskylab/Kandinsky-5}},
year = 2025
}
- Downloads last month
- 93