
Upload folder using huggingface_hub
Browse filesThis view is limited to 50 files because it contains too many changes.
See raw diff
- .github/scripts/assert_score.py +61 -0
- .github/workflows/lint.yml +23 -0
- .github/workflows/pr-run-test.yml +47 -0
- .gitignore +201 -0
- .pre-commit-config.yaml +31 -0
- EMMA/README.md +159 -0
- EMMA/__init__.py +0 -0
- EMMA/assets/EMMA.jpg +3 -0
- EMMA/assets/emma-small.jpg +3 -0
- EMMA/configs/gpt.yaml +20 -0
- EMMA/data_utils.py +60 -0
- EMMA/do_full_eval.py +0 -0
- EMMA/evaluation/calculate_acc.py +130 -0
- EMMA/evaluation/evaluate.py +200 -0
- EMMA/evaluation/utils.py +108 -0
- EMMA/generate_response.py +194 -0
- EMMA/models/__init__.py +0 -0
- EMMA/models/claude.py +81 -0
- EMMA/models/gpt.py +103 -0
- EMMA/models/internvl.py +172 -0
- EMMA/models/llava.py +82 -0
- EMMA/models/qwen.py +212 -0
- EMMA/scripts/evaluation_fast.sh +4 -0
- EMMA/scripts/evaluation_llm.sh +7 -0
- EMMA/scripts/run_closesource.sh +47 -0
- EMMA/scripts/run_opensource.sh +46 -0
- LICENSE +203 -0
- README.md +149 -0
- assets/LOGO.svg +24 -0
- do_eval.py +144 -0
- do_eval.sh +17 -0
- do_eval_emma.py +222 -0
- do_eval_temp.py +196 -0
- docs/en/.readthedocs.yaml +17 -0
- docs/en/ConfigSystem.md +67 -0
- docs/en/Contributors.md +21 -0
- docs/en/Development.md +145 -0
- docs/en/EvalByLMDeploy.md +27 -0
- docs/en/Makefile +20 -0
- docs/en/Quickstart.md +212 -0
- docs/en/_static/css/readthedocs.css +63 -0
- docs/en/_static/image/logo.svg +24 -0
- docs/en/_static/image/logo_icon.svg +31 -0
- docs/en/_static/js/custom.js +10 -0
- docs/en/_templates/404.html +18 -0
- docs/en/_templates/autosummary/class.rst +13 -0
- docs/en/_templates/callable.rst +14 -0
- docs/en/conf.py +234 -0
- docs/en/docutils.conf +2 -0
- docs/en/index.rst +41 -0
.github/scripts/assert_score.py
ADDED
|
@@ -0,0 +1,61 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import ast
|
| 3 |
+
import json
|
| 4 |
+
import os
|
| 5 |
+
|
| 6 |
+
import pandas as pd
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def validate_scores(dataset_list, assert_score, model_name):
|
| 10 |
+
for dataset in dataset_list:
|
| 11 |
+
base_score = assert_score[dataset][model_name]
|
| 12 |
+
if dataset == "OCRBench_MINI":
|
| 13 |
+
score_file = os.path.join("outputs", f"{model_name}/{model_name}_{dataset}_score.json")
|
| 14 |
+
cur_score = 0
|
| 15 |
+
with open(score_file, "r") as f:
|
| 16 |
+
total_score = json.load(f)
|
| 17 |
+
cur_score = total_score["Final Score Norm"]
|
| 18 |
+
assert (
|
| 19 |
+
abs(cur_score - float(base_score)) <= 0.01
|
| 20 |
+
), f"{dataset} on {model_name}: cur_score is {cur_score}, base_score is {base_score}"
|
| 21 |
+
else:
|
| 22 |
+
score_file = os.path.join("outputs", f"{model_name}/{model_name}_{dataset}_acc.csv")
|
| 23 |
+
df = pd.read_csv(score_file)
|
| 24 |
+
cur_score = df["Overall"].iloc[0]
|
| 25 |
+
if dataset == "MMBench_V11_MINI":
|
| 26 |
+
cur_score = df.loc[df["split"] == "dev", "Overall"].values
|
| 27 |
+
assert (
|
| 28 |
+
abs(cur_score - float(base_score)) <= 0.01
|
| 29 |
+
), f"{dataset} on {model_name}: cur_score is {cur_score}, base_score is {base_score}"
|
| 30 |
+
print(f"cur_score is {cur_score}, base_score is {base_score}")
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
def parse_arguments():
|
| 34 |
+
parser = argparse.ArgumentParser(description="Validate model scores against csv/json data")
|
| 35 |
+
|
| 36 |
+
parser.add_argument("--dataset", type=str, required=True, help="Space-separated list of datasets")
|
| 37 |
+
|
| 38 |
+
parser.add_argument(
|
| 39 |
+
"--base_score", type=str, required=True, help="Dictionary string in format {dataset:{model:score}}"
|
| 40 |
+
)
|
| 41 |
+
|
| 42 |
+
parser.add_argument("--model-name", type=str, required=True, help="Name of the model to validate")
|
| 43 |
+
|
| 44 |
+
return parser.parse_args()
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
def main():
|
| 48 |
+
args = parse_arguments()
|
| 49 |
+
|
| 50 |
+
try:
|
| 51 |
+
dataset_list = args.dataset.split()
|
| 52 |
+
base_score = ast.literal_eval(args.base_score)
|
| 53 |
+
except Exception as e:
|
| 54 |
+
print(f"Parameter parsing error: {str(e)}")
|
| 55 |
+
return
|
| 56 |
+
|
| 57 |
+
validate_scores(dataset_list, base_score, args.model_name)
|
| 58 |
+
|
| 59 |
+
|
| 60 |
+
if __name__ == "__main__":
|
| 61 |
+
main()
|
.github/workflows/lint.yml
ADDED
|
@@ -0,0 +1,23 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: lint
|
| 2 |
+
|
| 3 |
+
on: [push, pull_request]
|
| 4 |
+
|
| 5 |
+
concurrency:
|
| 6 |
+
group: ${{ github.workflow }}-${{ github.ref }}
|
| 7 |
+
cancel-in-progress: true
|
| 8 |
+
|
| 9 |
+
jobs:
|
| 10 |
+
lint:
|
| 11 |
+
runs-on: ubuntu-latest
|
| 12 |
+
steps:
|
| 13 |
+
- uses: actions/checkout@v2
|
| 14 |
+
- name: Set up Python 3.10
|
| 15 |
+
uses: actions/setup-python@v2
|
| 16 |
+
with:
|
| 17 |
+
python-version: 3.10.15
|
| 18 |
+
- name: Install pre-commit hook
|
| 19 |
+
run: |
|
| 20 |
+
pip install pre-commit
|
| 21 |
+
pre-commit install
|
| 22 |
+
- name: Linting
|
| 23 |
+
run: pre-commit run --all-files
|
.github/workflows/pr-run-test.yml
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
name: pr_run_test
|
| 2 |
+
|
| 3 |
+
on:
|
| 4 |
+
pull_request:
|
| 5 |
+
branches:
|
| 6 |
+
- "main"
|
| 7 |
+
paths-ignore:
|
| 8 |
+
- "docs/**"
|
| 9 |
+
- "**.md"
|
| 10 |
+
|
| 11 |
+
concurrency:
|
| 12 |
+
group: ${{ github.workflow }}-${{ github.event.pull_request.number || github.ref }}
|
| 13 |
+
cancel-in-progress: true
|
| 14 |
+
|
| 15 |
+
env:
|
| 16 |
+
BASE_SCORE: '{"MMBench_V11_MINI":{"Qwen2-VL-7B-Instruct":0.8727272727272727,"InternVL2_5-8B":0.8727272727272727,"llava_onevision_qwen2_7b_si":0.8363636363636363},"MMStar_MINI":{"Qwen2-VL-7B-Instruct":0.6266666666666667,"InternVL2_5-8B":0.6333333333333333,"llava_onevision_qwen2_7b_si":0.49333333333333335},"AI2D_MINI":{"Qwen2-VL-7B-Instruct":0.7854251012145749,"InternVL2_5-8B":0.8421052631578947,"llava_onevision_qwen2_7b_si":0.8178137651821862},"OCRBench_MINI":{"Qwen2-VL-7B-Instruct":16.6,"InternVL2_5-8B":16.4,"llava_onevision_qwen2_7b_si":12.9}}'
|
| 17 |
+
|
| 18 |
+
jobs:
|
| 19 |
+
vlm_test:
|
| 20 |
+
if: ${{!cancelled()}}
|
| 21 |
+
runs-on: [linux-a100]
|
| 22 |
+
strategy:
|
| 23 |
+
fail-fast: false
|
| 24 |
+
matrix:
|
| 25 |
+
model: [Qwen/Qwen2-VL-7B-Instruct,OpenGVLab/InternVL2_5-8B,lmms-lab/llava-onevision-qwen2-7b-si]
|
| 26 |
+
dataset: ["MMBench_V11_MINI MMStar_MINI AI2D_MINI","OCRBench_MINI"]
|
| 27 |
+
container:
|
| 28 |
+
image: kkscilife/vlmevalkit_2:a100
|
| 29 |
+
options: "--gpus=all --ipc=host -e https_proxy=$https_proxy -e http_proxy=$http_proxy --pull never"
|
| 30 |
+
volumes:
|
| 31 |
+
- /mnt/187:/mnt/187
|
| 32 |
+
steps:
|
| 33 |
+
- name: clone_repo
|
| 34 |
+
uses: actions/checkout@v3
|
| 35 |
+
- name: evaluation_model
|
| 36 |
+
run: |
|
| 37 |
+
pip install -e .
|
| 38 |
+
pre_model=$(echo ${{matrix.model}} | awk -F'/' '{print $1}')
|
| 39 |
+
ln -s /mnt/187/$pre_model .
|
| 40 |
+
if [ "${{matrix.model}}" = "lmms-lab/llava-onevision-qwen2-7b-si" ];then
|
| 41 |
+
model_name="llava_onevision_qwen2_7b_si"
|
| 42 |
+
else
|
| 43 |
+
model_name=$(echo ${{matrix.model}} | awk -F'/' '{print $2}')
|
| 44 |
+
fi
|
| 45 |
+
nvidia-smi
|
| 46 |
+
python run.py --data ${{matrix.dataset}} --model $model_name
|
| 47 |
+
python .github/scripts/assert_score.py --dataset "${{matrix.dataset}}" --base_score $BASE_SCORE --model-name $model_name
|
.gitignore
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
outputs/
|
| 2 |
+
public_eval/
|
| 3 |
+
*.xlsx
|
| 4 |
+
*.pkl
|
| 5 |
+
*.csv
|
| 6 |
+
.idea/
|
| 7 |
+
|
| 8 |
+
# Byte-compiled / optimized / DLL files
|
| 9 |
+
__pycache__/
|
| 10 |
+
*.py[cod]
|
| 11 |
+
*$py.class
|
| 12 |
+
|
| 13 |
+
# C extensions
|
| 14 |
+
*.so
|
| 15 |
+
|
| 16 |
+
# Distribution / packaging
|
| 17 |
+
.Python
|
| 18 |
+
build/
|
| 19 |
+
develop-eggs/
|
| 20 |
+
dist/
|
| 21 |
+
downloads/
|
| 22 |
+
eggs/
|
| 23 |
+
.eggs/
|
| 24 |
+
lib/
|
| 25 |
+
lib64/
|
| 26 |
+
parts/
|
| 27 |
+
sdist/
|
| 28 |
+
var/
|
| 29 |
+
wheels/
|
| 30 |
+
share/python-wheels/
|
| 31 |
+
*.egg-info/
|
| 32 |
+
.installed.cfg
|
| 33 |
+
*.egg
|
| 34 |
+
MANIFEST
|
| 35 |
+
.vscode/
|
| 36 |
+
.gradio/
|
| 37 |
+
|
| 38 |
+
# PyInstaller
|
| 39 |
+
# Usually these files are written by a python script from a template
|
| 40 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 41 |
+
*.manifest
|
| 42 |
+
*.spec
|
| 43 |
+
|
| 44 |
+
# Installer logs
|
| 45 |
+
pip-log.txt
|
| 46 |
+
pip-delete-this-directory.txt
|
| 47 |
+
|
| 48 |
+
# Unit test / coverage reports
|
| 49 |
+
htmlcov/
|
| 50 |
+
.tox/
|
| 51 |
+
.nox/
|
| 52 |
+
.coverage
|
| 53 |
+
.coverage.*
|
| 54 |
+
.cache
|
| 55 |
+
nosetests.xml
|
| 56 |
+
coverage.xml
|
| 57 |
+
*.cover
|
| 58 |
+
*.py,cover
|
| 59 |
+
.hypothesis/
|
| 60 |
+
.pytest_cache/
|
| 61 |
+
cover/
|
| 62 |
+
|
| 63 |
+
# Translations
|
| 64 |
+
*.mo
|
| 65 |
+
*.pot
|
| 66 |
+
|
| 67 |
+
# Django stuff:
|
| 68 |
+
*.log
|
| 69 |
+
local_settings.py
|
| 70 |
+
db.sqlite3
|
| 71 |
+
db.sqlite3-journal
|
| 72 |
+
|
| 73 |
+
# Flask stuff:
|
| 74 |
+
instance/
|
| 75 |
+
.webassets-cache
|
| 76 |
+
|
| 77 |
+
# Scrapy stuff:
|
| 78 |
+
.scrapy
|
| 79 |
+
|
| 80 |
+
# Sphinx documentation
|
| 81 |
+
docs/_build/
|
| 82 |
+
|
| 83 |
+
# PyBuilder
|
| 84 |
+
.pybuilder/
|
| 85 |
+
target/
|
| 86 |
+
|
| 87 |
+
# Jupyter Notebook
|
| 88 |
+
.ipynb_checkpoints
|
| 89 |
+
|
| 90 |
+
# IPython
|
| 91 |
+
profile_default/
|
| 92 |
+
ipython_config.py
|
| 93 |
+
|
| 94 |
+
# pyenv
|
| 95 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 96 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 97 |
+
# .python-version
|
| 98 |
+
|
| 99 |
+
# pipenv
|
| 100 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 101 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 102 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 103 |
+
# install all needed dependencies.
|
| 104 |
+
#Pipfile.lock
|
| 105 |
+
|
| 106 |
+
# poetry
|
| 107 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 108 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 109 |
+
# commonly ignored for libraries.
|
| 110 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 111 |
+
#poetry.lock
|
| 112 |
+
|
| 113 |
+
# pdm
|
| 114 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 115 |
+
#pdm.lock
|
| 116 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 117 |
+
# in version control.
|
| 118 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 119 |
+
.pdm.toml
|
| 120 |
+
|
| 121 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 122 |
+
__pypackages__/
|
| 123 |
+
|
| 124 |
+
# Celery stuff
|
| 125 |
+
celerybeat-schedule
|
| 126 |
+
celerybeat.pid
|
| 127 |
+
|
| 128 |
+
# SageMath parsed files
|
| 129 |
+
*.sage.py
|
| 130 |
+
|
| 131 |
+
# Environments
|
| 132 |
+
.env
|
| 133 |
+
.venv
|
| 134 |
+
env/
|
| 135 |
+
venv/
|
| 136 |
+
ENV/
|
| 137 |
+
env.bak/
|
| 138 |
+
venv.bak/
|
| 139 |
+
|
| 140 |
+
# Spyder project settings
|
| 141 |
+
.spyderproject
|
| 142 |
+
.spyproject
|
| 143 |
+
|
| 144 |
+
# Rope project settings
|
| 145 |
+
.ropeproject
|
| 146 |
+
|
| 147 |
+
# mkdocs documentation
|
| 148 |
+
/site
|
| 149 |
+
|
| 150 |
+
# mypy
|
| 151 |
+
.mypy_cache/
|
| 152 |
+
.dmypy.json
|
| 153 |
+
dmypy.json
|
| 154 |
+
|
| 155 |
+
# Pyre type checker
|
| 156 |
+
.pyre/
|
| 157 |
+
|
| 158 |
+
# pytype static type analyzer
|
| 159 |
+
.pytype/
|
| 160 |
+
|
| 161 |
+
# Cython debug symbols
|
| 162 |
+
cython_debug/
|
| 163 |
+
|
| 164 |
+
# Images
|
| 165 |
+
images/
|
| 166 |
+
|
| 167 |
+
scripts/*ttf
|
| 168 |
+
.history
|
| 169 |
+
cache_dir/*
|
| 170 |
+
|
| 171 |
+
# Evaluation Outputs
|
| 172 |
+
outputs/*
|
| 173 |
+
demo.ipynb
|
| 174 |
+
*json
|
| 175 |
+
.vscode
|
| 176 |
+
*.swp
|
| 177 |
+
GPT4o_MINI/
|
| 178 |
+
|
| 179 |
+
2weiyun*
|
| 180 |
+
script.py
|
| 181 |
+
Gemini*
|
| 182 |
+
Claude3-5V*
|
| 183 |
+
GLM4V*
|
| 184 |
+
GPT4o*
|
| 185 |
+
GPT4V*
|
| 186 |
+
mmmu_debug
|
| 187 |
+
bailingMM
|
| 188 |
+
BailingMM*
|
| 189 |
+
SenseChat*
|
| 190 |
+
Step*
|
| 191 |
+
DoubaoVL
|
| 192 |
+
arch
|
| 193 |
+
BlueLM*
|
| 194 |
+
mmb_*
|
| 195 |
+
Reka*
|
| 196 |
+
Taiyi
|
| 197 |
+
TeleMM
|
| 198 |
+
apple.jpg
|
| 199 |
+
assets/LOGO.png
|
| 200 |
+
api_list.txt
|
| 201 |
+
vlmeval/gemini_tmp.py
|
.pre-commit-config.yaml
ADDED
|
@@ -0,0 +1,31 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
exclude: |
|
| 2 |
+
(?x)^(
|
| 3 |
+
scripts/|
|
| 4 |
+
assets/|
|
| 5 |
+
vlmeval/config.py |
|
| 6 |
+
vlmeval/dataset/utils/wemath.py |
|
| 7 |
+
)
|
| 8 |
+
repos:
|
| 9 |
+
- repo: https://github.com/PyCQA/flake8
|
| 10 |
+
rev: 6.1.0
|
| 11 |
+
hooks:
|
| 12 |
+
- id: flake8
|
| 13 |
+
args: ["--max-line-length=120", "--ignore=F401,F403,F405,E402,E722,E741,W503,E231,E702"]
|
| 14 |
+
exclude: ^configs/
|
| 15 |
+
- repo: https://github.com/pre-commit/mirrors-yapf
|
| 16 |
+
rev: v0.30.0
|
| 17 |
+
hooks:
|
| 18 |
+
- id: yapf
|
| 19 |
+
args: ["--style={column_limit=120}"]
|
| 20 |
+
- repo: https://github.com/pre-commit/pre-commit-hooks
|
| 21 |
+
rev: v3.1.0
|
| 22 |
+
hooks:
|
| 23 |
+
- id: trailing-whitespace
|
| 24 |
+
- id: check-yaml
|
| 25 |
+
- id: end-of-file-fixer
|
| 26 |
+
- id: requirements-txt-fixer
|
| 27 |
+
- id: check-merge-conflict
|
| 28 |
+
- id: fix-encoding-pragma
|
| 29 |
+
args: ["--remove"]
|
| 30 |
+
- id: mixed-line-ending
|
| 31 |
+
args: ["--fix=lf"]
|
EMMA/README.md
ADDED
|
@@ -0,0 +1,159 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
<p align="center">
|
| 2 |
+
<img src="assets/emma-small.jpg" width="30%"> <br>
|
| 3 |
+
</p>
|
| 4 |
+
|
| 5 |
+
# EMMA: An Enhanced MultiModal ReAsoning Benchmark
|
| 6 |
+
|
| 7 |
+
🌟 This is the official repository for the paper "[Can MLLMs Reason in Multimodality? EMMA: An Enhanced MultiModal ReAsoning Benchmark](https://www.arxiv.org/abs/2501.05444)", which contains generation and evaluation code for the **EMMA** benchmark.
|
| 8 |
+
|
| 9 |
+
[[🌐 Homepage](https://emma-benchmark.github.io/)] [[🤗EMMA](https://huggingface.co/datasets/luckychao/EMMA)] [[🤗EMMA-mini](https://huggingface.co/datasets/luckychao/EMMA-mini)] [[📖 ArXiv Paper](https://www.arxiv.org/abs/2501.05444)]
|
| 10 |
+
|
| 11 |
+
## 💥 News
|
| 12 |
+
- **[2025.1.23]** 🔍 We've updated the leaderboard with the results of the [QVQ-72B-Preview](https://huggingface.co/Qwen/QVQ-72B-Preview) model included.
|
| 13 |
+
- **[2025.1.10]** Our dataset is now accessible at [Huggingface Datasets](https://huggingface.co/datasets/luckychao/EMMA).
|
| 14 |
+
- **[2025.1.10]** Our paper is now accessible at https://arxiv.org/abs/2501.05444.
|
| 15 |
+
|
| 16 |
+
## 👀 About EMMA
|
| 17 |
+
|
| 18 |
+
The ability to organically reason **over** and **with** both text and images is a pillar of human intelligence, yet the ability of Multimodal Large Language Models (MLLMs) to perform such multimodal reasoning remains under-explored.
|
| 19 |
+
We introduce **EMMA (Enhanced MultiModal reAsoning)**, a benchmark targeting organic multimodal reasoning across mathematics, physics, chemistry, and coding.
|
| 20 |
+
EMMA tasks demand advanced cross-modal reasoning that cannot be solved by thinking separately in each modality, offering an enhanced test suite for MLLMs' reasoning capabilities.
|
| 21 |
+
|
| 22 |
+
EMMA is composed of 2,788 problems, of which 1,796 are newly constructed, across four domains. Within each subject, we further provide fine-grained labels for each question based on the specific skills it measures.
|
| 23 |
+
|
| 24 |
+
<p align="center">
|
| 25 |
+
<img src="assets/EMMA.jpg" width="90%"> <br>
|
| 26 |
+
<b>Overview of EMMA.</b>
|
| 27 |
+
</p>
|
| 28 |
+
|
| 29 |
+
Our evaluation of state-of-the-art MLLMs on EMMA reveals significant limitations in handling complex multimodal and multi-step reasoning tasks, with even advanced techniques like Chain-of-Thought prompting and test-time compute scaling underperforming.
|
| 30 |
+
These findings underscore the need for improved multimodal architectures and training paradigms to close the gap between human and model reasoning in multimodality.
|
| 31 |
+
|
| 32 |
+
## 🏆 Leaderboard
|
| 33 |
+
|
| 34 |
+
The leaderboard is available [here](https://emma-benchmark.github.io/#leaderboard).
|
| 35 |
+
|
| 36 |
+
## 📖 Dataset Usage
|
| 37 |
+
|
| 38 |
+
### Data Downloading
|
| 39 |
+
|
| 40 |
+
To create a more balanced subset of EMMA, we randomly sample 400 questions (100 per subject) from the benchmark and get EMMA-mini[🤗](https://huggingface.co/datasets/luckychao/EMMA-mini).
|
| 41 |
+
|
| 42 |
+
You can download both two datasets by the following command (Taking downloading math data as an example):
|
| 43 |
+
|
| 44 |
+
```python
|
| 45 |
+
from datasets import load_dataset
|
| 46 |
+
|
| 47 |
+
dataset = load_dataset("luckychao/EMMA", "Math", split="test")
|
| 48 |
+
```
|
| 49 |
+
|
| 50 |
+
```python
|
| 51 |
+
from datasets import load_dataset
|
| 52 |
+
|
| 53 |
+
dataset = load_dataset("luckychao/EMMA-mini", "Math", split="test")
|
| 54 |
+
```
|
| 55 |
+
|
| 56 |
+
### Data Format
|
| 57 |
+
|
| 58 |
+
The dataset is provided in jsonl format and contains the following attributes:
|
| 59 |
+
|
| 60 |
+
```
|
| 61 |
+
{
|
| 62 |
+
"pid": [string] Problem ID, e.g., “math_1”,
|
| 63 |
+
"question": [string] The question text,
|
| 64 |
+
"options": [list] Choice options for multiple-choice problems. For free-form problems, this could be a 'none' value,
|
| 65 |
+
"answer": [string] The correct answer for the problem,
|
| 66 |
+
"image_1": [image] ,
|
| 67 |
+
"image_2": [image] ,
|
| 68 |
+
"image_3": [image] ,
|
| 69 |
+
"image_4": [image] ,
|
| 70 |
+
"image_5": [image] ,
|
| 71 |
+
"solution": [string] The detailed thinking steps required to solve the problem,
|
| 72 |
+
"subject": [string] The subject of data, e.g., “Math”, “Physics”...,
|
| 73 |
+
"task": [string] The task of the problem, e.g., “Code Choose Vis”,
|
| 74 |
+
"category": [string] The category of the problem, e.g., “2D Transformation”,
|
| 75 |
+
"source": [string] The original source dataset of the data, e.g., “math-vista”. For handmade data, this could be “Newly annotated” ,
|
| 76 |
+
"type": [string] Types of questions, e.g., “Multiple Choice”, “Open-ended”,
|
| 77 |
+
"context": [string] Background knowledge required for the question. For problems without context, this could be a 'none' value,
|
| 78 |
+
}
|
| 79 |
+
```
|
| 80 |
+
|
| 81 |
+
## 📈 Evaluation
|
| 82 |
+
|
| 83 |
+
### Responses Generation
|
| 84 |
+
Our repository supports the evaluation of open source models such as Qwen2-VL, InternVL, LLaVA, and closed source models such as GPT, Gemini, Claude, etc.
|
| 85 |
+
You can generate responses of these models by using the following commands:
|
| 86 |
+
|
| 87 |
+
Open-source Model:
|
| 88 |
+
```
|
| 89 |
+
python generate_response.py \
|
| 90 |
+
--split 'test' \
|
| 91 |
+
--subject 'Math' 'Physics' 'Chemistry' 'Coding' \
|
| 92 |
+
--strategy 'CoT' \
|
| 93 |
+
--config_path 'configs/gpt.yaml' \
|
| 94 |
+
--model_path 'path_to_your_local_model' \
|
| 95 |
+
--output_path 'path_to_output_file' \
|
| 96 |
+
--max_tokens 4096 \
|
| 97 |
+
--temperature 0.7 \
|
| 98 |
+
--save_every 20
|
| 99 |
+
```
|
| 100 |
+
|
| 101 |
+
Close-source Model:
|
| 102 |
+
|
| 103 |
+
```
|
| 104 |
+
python generate_response.py \
|
| 105 |
+
--dataset_name 'luckychao/EMMA' \
|
| 106 |
+
--split 'test' \
|
| 107 |
+
--subject 'Math' 'Physics' 'Chemistry' 'Coding' \
|
| 108 |
+
--strategy 'CoT' \
|
| 109 |
+
--config_path 'configs/gpt.yaml' \
|
| 110 |
+
--model 'remote-model-name' \
|
| 111 |
+
--api_key '' \
|
| 112 |
+
--output_path 'path_to_output_file' \
|
| 113 |
+
--max_tokens 4096 \
|
| 114 |
+
--temperature 0 \
|
| 115 |
+
--save_every 20
|
| 116 |
+
```
|
| 117 |
+
|
| 118 |
+
### Answer Evaluation
|
| 119 |
+
|
| 120 |
+
Once all the model outputs have been generated, execute the `evaluate.py` function to extract the short answer text from the detailed response and evaluate the correctness of the answers.
|
| 121 |
+
We offer two evaluation methods: **Fast-eval** and **LLMs-eval**. The fast-eval method employs rule-based extraction for quicker processing, while the LLMs-eval method leverages advanced models like GPT-4o to enhance precision in extraction and evaluation.
|
| 122 |
+
|
| 123 |
+
Fast-extract:
|
| 124 |
+
```
|
| 125 |
+
python evaluate.py \
|
| 126 |
+
--results_dir 'path_to_your_results_dir' \
|
| 127 |
+
--response_label 'response' \
|
| 128 |
+
--save_every 20
|
| 129 |
+
```
|
| 130 |
+
|
| 131 |
+
LLMs-eval:
|
| 132 |
+
```
|
| 133 |
+
python evaluate.py \
|
| 134 |
+
--results_dir 'path_to_your_results_dir' \
|
| 135 |
+
--response_label 'response' \
|
| 136 |
+
--save_every 20 \
|
| 137 |
+
--gpt_eval \
|
| 138 |
+
--api_key '' \
|
| 139 |
+
--model 'chatgpt-4o-latest'
|
| 140 |
+
```
|
| 141 |
+
|
| 142 |
+
### Score Calculation
|
| 143 |
+
|
| 144 |
+
Finally, execute `python evaluation/calculate_acc.py` to calculate the final score based on the evaluation results.
|
| 145 |
+
This step will compute overall accuracy as well as accuracy for each subject, category, and tasks.
|
| 146 |
+
|
| 147 |
+
|
| 148 |
+
## 📝Citation
|
| 149 |
+
|
| 150 |
+
If you find our benchmark useful in your research, please consider citing this BibTex:
|
| 151 |
+
|
| 152 |
+
```
|
| 153 |
+
@article{hao2025can,
|
| 154 |
+
title={Can MLLMs Reason in Multimodality? EMMA: An Enhanced MultiModal ReAsoning Benchmark},
|
| 155 |
+
author={Hao, Yunzhuo and Gu, Jiawei and Wang, Huichen Will and Li, Linjie and Yang, Zhengyuan and Wang, Lijuan and Cheng, Yu},
|
| 156 |
+
journal={arXiv preprint arXiv:2501.05444},
|
| 157 |
+
year={2025}
|
| 158 |
+
}
|
| 159 |
+
```
|
EMMA/__init__.py
ADDED
|
File without changes
|
EMMA/assets/EMMA.jpg
ADDED

|
Git LFS Details
|
EMMA/assets/emma-small.jpg
ADDED

|
Git LFS Details
|
EMMA/configs/gpt.yaml
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Strategy_Instruction:
|
| 2 |
+
CoT: "Please solve the problem step by step."
|
| 3 |
+
Directly: "Please ensure that your output only contains the final answer without any additional content (such as intermediate reasoning steps)."
|
| 4 |
+
TrainCoT: "Output the thinking process in <think> </think> and final answer in <answer> </answer> tags."
|
| 5 |
+
|
| 6 |
+
multi_choice_format:
|
| 7 |
+
"{context}
|
| 8 |
+
|
| 9 |
+
{question}
|
| 10 |
+
|
| 11 |
+
{options}
|
| 12 |
+
|
| 13 |
+
Answer with the option's letter from the given choices and put the letter in one \"\\boxed{{}}\". "
|
| 14 |
+
|
| 15 |
+
open_ended_format:
|
| 16 |
+
"{context}
|
| 17 |
+
|
| 18 |
+
{question}
|
| 19 |
+
|
| 20 |
+
Answer the question using a single word or phrase and put the answer in one \"\\boxed{{}}\". "
|
EMMA/data_utils.py
ADDED
|
@@ -0,0 +1,60 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import yaml
|
| 2 |
+
import json
|
| 3 |
+
|
| 4 |
+
|
| 5 |
+
def load_yaml(file_path):
|
| 6 |
+
with open(file_path, 'r') as stream:
|
| 7 |
+
try:
|
| 8 |
+
yaml_dict = yaml.safe_load(stream)
|
| 9 |
+
return yaml_dict
|
| 10 |
+
except yaml.YAMLError as exc:
|
| 11 |
+
print(exc)
|
| 12 |
+
return None
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
def verify_response(response):
|
| 16 |
+
if isinstance(response, str):
|
| 17 |
+
response = response.strip()
|
| 18 |
+
if response == "" or response is None:
|
| 19 |
+
return False
|
| 20 |
+
if "Response Error" in response:
|
| 21 |
+
return False
|
| 22 |
+
return True
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def build_query(sample, config, strategy):
|
| 26 |
+
"""Build the text query by combining the context, question and options. The <image_n> token is still there"""
|
| 27 |
+
context = sample['context']
|
| 28 |
+
question = sample['question']
|
| 29 |
+
example = ""
|
| 30 |
+
res_dict = {}
|
| 31 |
+
if sample['type'].lower() == 'multiple choice':
|
| 32 |
+
options = sample['options']
|
| 33 |
+
start_chr = 'A'
|
| 34 |
+
for option in options:
|
| 35 |
+
example += f"{start_chr}: {option}\n"
|
| 36 |
+
start_chr = chr(ord(start_chr) + 1)
|
| 37 |
+
empty_prompt_sample_structure = config['multi_choice_format']
|
| 38 |
+
empty_prompt = empty_prompt_sample_structure.format(context=context, question=question, options=example)
|
| 39 |
+
if strategy == 'CoT':
|
| 40 |
+
res_dict['query'] = empty_prompt + config['Strategy_Instruction']['CoT']
|
| 41 |
+
elif strategy == 'TrainCoT':
|
| 42 |
+
res_dict['query'] = "Question: " + empty_prompt + config['Strategy_Instruction']['TrainCoT']
|
| 43 |
+
else:
|
| 44 |
+
res_dict['query'] = empty_prompt + config['Strategy_Instruction']['Directly']
|
| 45 |
+
|
| 46 |
+
res_dict['gt_content'] = options[ord(sample['answer'].upper()) - ord('A')]
|
| 47 |
+
else:
|
| 48 |
+
empty_prompt_sample_structure = config['open_ended_format']
|
| 49 |
+
empty_prompt = empty_prompt_sample_structure.format(context=context, question=question)
|
| 50 |
+
if strategy == 'CoT':
|
| 51 |
+
res_dict['query'] = empty_prompt + config['Strategy_Instruction']['CoT']
|
| 52 |
+
elif strategy == 'TrainCoT':
|
| 53 |
+
res_dict['query'] = "Question: " + empty_prompt + config['Strategy_Instruction']['TrainCoT']
|
| 54 |
+
else:
|
| 55 |
+
res_dict['query'] = empty_prompt + config['Strategy_Instruction']['Directly']
|
| 56 |
+
res_dict['gt_content'] = sample['answer']
|
| 57 |
+
|
| 58 |
+
# append existing key and value in data
|
| 59 |
+
res_dict.update(sample)
|
| 60 |
+
return res_dict
|
EMMA/do_full_eval.py
ADDED
|
File without changes
|
EMMA/evaluation/calculate_acc.py
ADDED
|
@@ -0,0 +1,130 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import logging
|
| 3 |
+
import os
|
| 4 |
+
import json
|
| 5 |
+
from collections import defaultdict
|
| 6 |
+
|
| 7 |
+
|
| 8 |
+
def gen_score(input_file, output_file, logger=logging.getLogger(__name__)):
|
| 9 |
+
with open(input_file, "r") as f:
|
| 10 |
+
data = json.load(f)
|
| 11 |
+
|
| 12 |
+
total_correct = 0
|
| 13 |
+
total_count = 0
|
| 14 |
+
|
| 15 |
+
subject_stats = defaultdict(lambda: {"correct": 0, "total": 0})
|
| 16 |
+
type_stats = defaultdict(lambda: {"correct": 0, "total": 0})
|
| 17 |
+
category_stats = defaultdict(lambda: defaultdict(lambda: {"correct": 0, "total": 0}))
|
| 18 |
+
task_stats = defaultdict(lambda: {"correct": 0, "total": 0})
|
| 19 |
+
|
| 20 |
+
for key, entry in data.items():
|
| 21 |
+
total_count += 1
|
| 22 |
+
is_correct = 1 if entry["true_false"] else 0
|
| 23 |
+
total_correct += is_correct
|
| 24 |
+
|
| 25 |
+
subject = entry["subject"]
|
| 26 |
+
question_type = entry["type"].lower()
|
| 27 |
+
if entry["category"]:
|
| 28 |
+
if subject == "Coding":
|
| 29 |
+
category_list = entry["category"].split(';')
|
| 30 |
+
for category in category_list:
|
| 31 |
+
category = category.strip()
|
| 32 |
+
category_stats[subject][category]["total"] += 1
|
| 33 |
+
category_stats[subject][category]["correct"] += is_correct
|
| 34 |
+
else:
|
| 35 |
+
category = entry["category"]
|
| 36 |
+
category_stats[subject][category]["total"] += 1
|
| 37 |
+
category_stats[subject][category]["correct"] += is_correct
|
| 38 |
+
if entry["task"]:
|
| 39 |
+
task = subject + '_' + entry["task"]
|
| 40 |
+
task_stats[task]["total"] += 1
|
| 41 |
+
task_stats[task]["correct"] += is_correct
|
| 42 |
+
|
| 43 |
+
subject_stats[subject]["total"] += 1
|
| 44 |
+
subject_stats[subject]["correct"] += is_correct
|
| 45 |
+
|
| 46 |
+
type_stats[question_type]["total"] += 1
|
| 47 |
+
type_stats[question_type]["correct"] += is_correct
|
| 48 |
+
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
average_accuracy = total_correct / total_count if total_count > 0 else 0
|
| 52 |
+
logger.info(f"Average accuracy: {average_accuracy}")
|
| 53 |
+
|
| 54 |
+
score = {
|
| 55 |
+
"average": {
|
| 56 |
+
"accuracy": average_accuracy,
|
| 57 |
+
"correct": total_correct,
|
| 58 |
+
"total": total_count
|
| 59 |
+
},
|
| 60 |
+
"subject": {
|
| 61 |
+
subject: {
|
| 62 |
+
"accuracy": stats["correct"] / stats["total"] if stats["total"] > 0 else 0,
|
| 63 |
+
"correct": stats["correct"],
|
| 64 |
+
"total": stats["total"]
|
| 65 |
+
} for subject, stats in subject_stats.items()
|
| 66 |
+
},
|
| 67 |
+
"question_type": {
|
| 68 |
+
question_type: {
|
| 69 |
+
"accuracy": stats["correct"] / stats["total"] if stats["total"] > 0 else 0,
|
| 70 |
+
"correct": stats["correct"],
|
| 71 |
+
"total": stats["total"]
|
| 72 |
+
} for question_type, stats in type_stats.items()
|
| 73 |
+
},
|
| 74 |
+
"category": {
|
| 75 |
+
subject:{
|
| 76 |
+
category: {
|
| 77 |
+
"accuracy": stats["correct"] / stats["total"] if stats["total"] > 0 else 0,
|
| 78 |
+
"correct": stats["correct"],
|
| 79 |
+
"total": stats["total"]
|
| 80 |
+
} for category, stats in categories.items()
|
| 81 |
+
}for subject, categories in category_stats.items()
|
| 82 |
+
},
|
| 83 |
+
"task": {
|
| 84 |
+
task: {
|
| 85 |
+
"accuracy": stats["correct"] / stats["total"] if stats["total"] > 0 else 0,
|
| 86 |
+
"correct": stats["correct"],
|
| 87 |
+
"total": stats["total"]
|
| 88 |
+
} for task, stats in task_stats.items()
|
| 89 |
+
}
|
| 90 |
+
}
|
| 91 |
+
|
| 92 |
+
with open(output_file, "w") as f:
|
| 93 |
+
f.write(json.dumps(score, indent=2))
|
| 94 |
+
|
| 95 |
+
def main():
|
| 96 |
+
parser = argparse.ArgumentParser()
|
| 97 |
+
# output
|
| 98 |
+
parser.add_argument('--results_dir', type=str, default='')
|
| 99 |
+
args = parser.parse_args()
|
| 100 |
+
for root, dirs, files in os.walk(args.results_dir):
|
| 101 |
+
for file in files:
|
| 102 |
+
if file.endswith(".json") and not file.endswith("_result.json"):
|
| 103 |
+
gen_score(os.path.join(root, file), os.path.join(root, file).replace('.json', '_result.json'))
|
| 104 |
+
|
| 105 |
+
|
| 106 |
+
if __name__ == "__main__":
|
| 107 |
+
logging.basicConfig(
|
| 108 |
+
level=os.environ.get("LOGLEVEL", "INFO").upper(),
|
| 109 |
+
format="[%(name)s] %(message)s",
|
| 110 |
+
datefmt="[%X]"
|
| 111 |
+
)
|
| 112 |
+
logger_blocklist = [
|
| 113 |
+
"asyncio",
|
| 114 |
+
"azure",
|
| 115 |
+
"azureml",
|
| 116 |
+
"datasets",
|
| 117 |
+
"httpx",
|
| 118 |
+
"httpcore",
|
| 119 |
+
"filelock",
|
| 120 |
+
"fsspec",
|
| 121 |
+
"msal",
|
| 122 |
+
"msrest",
|
| 123 |
+
"openai",
|
| 124 |
+
"PIL",
|
| 125 |
+
"urllib3",
|
| 126 |
+
]
|
| 127 |
+
for module in logger_blocklist:
|
| 128 |
+
logging.getLogger(module).setLevel(logging.WARNING)
|
| 129 |
+
|
| 130 |
+
main()
|
EMMA/evaluation/evaluate.py
ADDED
|
@@ -0,0 +1,200 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import logging
|
| 4 |
+
import os
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
from .utils import *
|
| 7 |
+
import re
|
| 8 |
+
import time
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
def fast_extract_answer(response) :
|
| 12 |
+
response = response.strip()
|
| 13 |
+
response = process_answer(response)
|
| 14 |
+
# Direct Strategy Multi-Choice
|
| 15 |
+
# A / A: / A.
|
| 16 |
+
for ch in 'ABCDEFGH':
|
| 17 |
+
if response.upper() == ch or response.startswith(f'{ch}:') or response.startswith(f'{ch}.'):
|
| 18 |
+
return ch
|
| 19 |
+
|
| 20 |
+
# Direct Strategy Open-ended
|
| 21 |
+
# 1
|
| 22 |
+
if is_number(response):
|
| 23 |
+
return response
|
| 24 |
+
|
| 25 |
+
# CoT strategy
|
| 26 |
+
if 'boxed{' in response:
|
| 27 |
+
try:
|
| 28 |
+
model_answers = extract_full_boxed_content(response)
|
| 29 |
+
if model_answers:
|
| 30 |
+
# for coding
|
| 31 |
+
# \\boxed{\\text{}}
|
| 32 |
+
try:
|
| 33 |
+
text_content = re.findall(r'\\text{(.*?)}', model_answers[-1])
|
| 34 |
+
if text_content:
|
| 35 |
+
return text_content[-1].strip()
|
| 36 |
+
except Exception:
|
| 37 |
+
pass
|
| 38 |
+
return model_answers[-1].strip()
|
| 39 |
+
except Exception:
|
| 40 |
+
pass
|
| 41 |
+
|
| 42 |
+
# for Coding
|
| 43 |
+
# the correct answer is\n D.
|
| 44 |
+
for flag in ['final answer is', 'correct answer is', 'answer should be', 'answer is', 'answer:']:
|
| 45 |
+
if flag in response.lower():
|
| 46 |
+
try:
|
| 47 |
+
model_answer = response.lower().split(flag)[-1].strip()
|
| 48 |
+
return model_answer.split('\n')[0].split('.')[0]
|
| 49 |
+
except Exception:
|
| 50 |
+
pass
|
| 51 |
+
|
| 52 |
+
return ""
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def create_test_prompt(score_prompt, problem, label):
|
| 56 |
+
score_prompt = score_prompt.strip()
|
| 57 |
+
response = problem[label]
|
| 58 |
+
answer = problem['answer']
|
| 59 |
+
full_prompt = f'{score_prompt}\n' + f'Response: {response}\n' + f'Answer: {answer}\n' + 'Correct_or_not:'
|
| 60 |
+
return full_prompt
|
| 61 |
+
|
| 62 |
+
|
| 63 |
+
def call_gpt(client, model, user_prompt):
|
| 64 |
+
attempt = 0
|
| 65 |
+
while attempt < 5:
|
| 66 |
+
try:
|
| 67 |
+
response = client.chat.completions.create(
|
| 68 |
+
model=model,
|
| 69 |
+
messages=[
|
| 70 |
+
{"role": "user", "content": user_prompt}
|
| 71 |
+
]
|
| 72 |
+
)
|
| 73 |
+
return response.choices[0].message.content.strip()
|
| 74 |
+
except Exception as e:
|
| 75 |
+
logging.error(f"Attempt {attempt + 1} failed: {e}")
|
| 76 |
+
|
| 77 |
+
if 'error' in str(e) and 'message' in str(e):
|
| 78 |
+
error_message = str(e)
|
| 79 |
+
if 'The server had an error processing your request.' in error_message:
|
| 80 |
+
sleep_time = 30
|
| 81 |
+
logging.error(f"Server error, retrying in {sleep_time}s...")
|
| 82 |
+
time.sleep(sleep_time)
|
| 83 |
+
elif 'Please try again in ' in error_message:
|
| 84 |
+
sleep_time = float(error_message.split('Please try again in ')[1].split('s.')[0])
|
| 85 |
+
logging.error(f"Rate limit exceeded, retrying in {sleep_time * 2}s...")
|
| 86 |
+
time.sleep(sleep_time * 2)
|
| 87 |
+
else:
|
| 88 |
+
print("Unknown error, skipping this request.")
|
| 89 |
+
break
|
| 90 |
+
attempt += 1
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def gen_true_false(answer_file, response_label='response', gpt_eval=False, model="", api_key="", rerun=True, save_every=20, logger=logging.getLogger(__name__)):
|
| 94 |
+
logger.info(f"Reading {answer_file}.....")
|
| 95 |
+
label = response_label
|
| 96 |
+
if gpt_eval:
|
| 97 |
+
from openai import OpenAI
|
| 98 |
+
client = OpenAI(api_key=api_key)
|
| 99 |
+
with open(answer_file, "r") as f:
|
| 100 |
+
results = json.load(f)
|
| 101 |
+
full_pids = list(results.keys())
|
| 102 |
+
|
| 103 |
+
skip_pids = []
|
| 104 |
+
# for pid, problem in results.items():
|
| 105 |
+
# flag = problem.get('true_false')
|
| 106 |
+
# if flag is not None:
|
| 107 |
+
# skip_pids.append(problem['pid'])
|
| 108 |
+
|
| 109 |
+
if rerun:
|
| 110 |
+
test_pids = full_pids
|
| 111 |
+
else:
|
| 112 |
+
if len(skip_pids) > 0:
|
| 113 |
+
logger.info(
|
| 114 |
+
f"Found existing results file with {len(skip_pids)} problems with valid responses. Skipping these problems..."
|
| 115 |
+
)
|
| 116 |
+
test_pids = [pid for pid in full_pids if pid not in skip_pids]
|
| 117 |
+
|
| 118 |
+
logger.info(f"Number of test problems to run: {len(test_pids)}")
|
| 119 |
+
|
| 120 |
+
for i, pid in enumerate(tqdm(test_pids)):
|
| 121 |
+
problem = results[pid]
|
| 122 |
+
flag = False
|
| 123 |
+
if label not in problem or not problem[label]:
|
| 124 |
+
results[pid]['extraction'] = None
|
| 125 |
+
results[pid]['true_false'] = False
|
| 126 |
+
continue
|
| 127 |
+
|
| 128 |
+
if gpt_eval:
|
| 129 |
+
user_prompt = create_test_prompt(score_demo_prompt, problem, label)
|
| 130 |
+
flag_cache = call_gpt(client, model, user_prompt)
|
| 131 |
+
results[pid]['gpt_eval'] = flag_cache
|
| 132 |
+
if flag_cache.lower() == 'correct':
|
| 133 |
+
flag = True
|
| 134 |
+
else:
|
| 135 |
+
flag = False
|
| 136 |
+
else:
|
| 137 |
+
model_answer = fast_extract_answer(problem[label])
|
| 138 |
+
results[pid]['extraction'] = model_answer
|
| 139 |
+
if is_equal(model_answer, results[pid]['answer']) or is_equal(model_answer, results[pid]['gt_content']):
|
| 140 |
+
flag = True
|
| 141 |
+
|
| 142 |
+
results[pid]['true_false'] = flag
|
| 143 |
+
|
| 144 |
+
if (i % save_every == 0 and i > 0) or i == len(test_pids) - 1:
|
| 145 |
+
with open(answer_file, "w") as f:
|
| 146 |
+
f.write(json.dumps(results, indent=2))
|
| 147 |
+
logger.info(f"Saved results to {answer_file}")
|
| 148 |
+
|
| 149 |
+
with open(answer_file, "w") as f:
|
| 150 |
+
f.write(json.dumps(results, indent=2))
|
| 151 |
+
logger.info(f"Saved results to {answer_file}")
|
| 152 |
+
|
| 153 |
+
|
| 154 |
+
def main():
|
| 155 |
+
parser = argparse.ArgumentParser()
|
| 156 |
+
|
| 157 |
+
parser.add_argument('--results_dir', type=str, default='')
|
| 158 |
+
parser.add_argument('--response_label', type=str, default='response', help='response label for the input file')
|
| 159 |
+
parser.add_argument('--rerun', action='store_true', help='rerun the answer extraction')
|
| 160 |
+
parser.add_argument('--save_every', type=int, default=10, help='save every n problems')
|
| 161 |
+
|
| 162 |
+
parser.add_argument('--gpt_eval', action='store_true', help='use gpt to evaluate')
|
| 163 |
+
parser.add_argument('--api_key', type=str, default="")
|
| 164 |
+
parser.add_argument('--model', type=str, default="chatgpt-4o-latest")
|
| 165 |
+
|
| 166 |
+
args = parser.parse_args()
|
| 167 |
+
|
| 168 |
+
logging.info("Starting to extract answers.......")
|
| 169 |
+
|
| 170 |
+
for root, dirs, files in os.walk(args.results_dir):
|
| 171 |
+
for file in files:
|
| 172 |
+
if file.endswith(".json") and not file.endswith("_result.json"):
|
| 173 |
+
gen_true_false(os.path.join(root, file), args)
|
| 174 |
+
|
| 175 |
+
|
| 176 |
+
if __name__ == "__main__":
|
| 177 |
+
logging.basicConfig(
|
| 178 |
+
level=os.environ.get("LOGLEVEL", "INFO").upper(),
|
| 179 |
+
format="[%(name)s] %(message)s",
|
| 180 |
+
datefmt="[%X]"
|
| 181 |
+
)
|
| 182 |
+
logger_blocklist = [
|
| 183 |
+
"asyncio",
|
| 184 |
+
"azure",
|
| 185 |
+
"azureml",
|
| 186 |
+
"datasets",
|
| 187 |
+
"httpx",
|
| 188 |
+
"httpcore",
|
| 189 |
+
"filelock",
|
| 190 |
+
"fsspec",
|
| 191 |
+
"msal",
|
| 192 |
+
"msrest",
|
| 193 |
+
"openai",
|
| 194 |
+
"PIL",
|
| 195 |
+
"urllib3",
|
| 196 |
+
]
|
| 197 |
+
for module in logger_blocklist:
|
| 198 |
+
logging.getLogger(module).setLevel(logging.WARNING)
|
| 199 |
+
|
| 200 |
+
main()
|
EMMA/evaluation/utils.py
ADDED
|
@@ -0,0 +1,108 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
from latex2sympy2 import latex2sympy
|
| 2 |
+
import re
|
| 3 |
+
from sympy import simplify
|
| 4 |
+
from word2number import w2n
|
| 5 |
+
|
| 6 |
+
|
| 7 |
+
def verify_extraction(extraction):
|
| 8 |
+
extraction = extraction.strip()
|
| 9 |
+
if extraction == "" or extraction == None:
|
| 10 |
+
return False
|
| 11 |
+
return True
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def is_number(s):
|
| 15 |
+
try:
|
| 16 |
+
float(s)
|
| 17 |
+
return True
|
| 18 |
+
except ValueError:
|
| 19 |
+
return False
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
def process_answer(answer):
|
| 23 |
+
answer_pattern = re.compile(r'<answer>(.*?)</answer>')
|
| 24 |
+
answer = answer.split('### Final Answer ###')[-1].strip() if '### Final Answer ###' in answer else answer
|
| 25 |
+
answer = answer.split('Answer:')[-1].strip() if 'Answer:' in answer else answer
|
| 26 |
+
matches = re.findall(answer_pattern, answer)
|
| 27 |
+
answer = matches[-1] if matches else answer
|
| 28 |
+
return answer
|
| 29 |
+
|
| 30 |
+
def extract_full_boxed_content(s):
|
| 31 |
+
"""
|
| 32 |
+
Extract the full content inside \boxed{}, handling nested braces {{}} properly.
|
| 33 |
+
"""
|
| 34 |
+
results = []
|
| 35 |
+
|
| 36 |
+
i = 0
|
| 37 |
+
while i < len(s):
|
| 38 |
+
if s[i:i + 7] == r'\boxed{':
|
| 39 |
+
brace_stack = []
|
| 40 |
+
start = i + 7
|
| 41 |
+
i = start
|
| 42 |
+
|
| 43 |
+
while i < len(s):
|
| 44 |
+
if s[i] == '{':
|
| 45 |
+
brace_stack.append(i)
|
| 46 |
+
elif s[i] == '}':
|
| 47 |
+
if brace_stack:
|
| 48 |
+
brace_stack.pop()
|
| 49 |
+
else:
|
| 50 |
+
results.append(s[start:i])
|
| 51 |
+
break
|
| 52 |
+
i += 1
|
| 53 |
+
i += 1
|
| 54 |
+
|
| 55 |
+
return results
|
| 56 |
+
|
| 57 |
+
|
| 58 |
+
def is_equal(md_ans, gt_ans):
|
| 59 |
+
|
| 60 |
+
md_ans = md_ans.lower()
|
| 61 |
+
gt_ans = gt_ans.lower()
|
| 62 |
+
|
| 63 |
+
if md_ans.strip() == gt_ans.strip():
|
| 64 |
+
return True
|
| 65 |
+
|
| 66 |
+
try:
|
| 67 |
+
md_ans_cache = str(w2n.word_to_num(md_ans))
|
| 68 |
+
if md_ans_cache.strip() == gt_ans.strip():
|
| 69 |
+
return True
|
| 70 |
+
except ValueError:
|
| 71 |
+
pass
|
| 72 |
+
|
| 73 |
+
# For Math
|
| 74 |
+
try:
|
| 75 |
+
# Parse LaTeX expressions into sympy and compare numerical values
|
| 76 |
+
md_sympy = latex2sympy(md_ans)
|
| 77 |
+
gt_sympy = latex2sympy(gt_ans)
|
| 78 |
+
|
| 79 |
+
# Compare evaluated results, rounded to 2 decimal places
|
| 80 |
+
if round(float(md_sympy.evalf()), 2) == round(float(gt_sympy.evalf()), 2):
|
| 81 |
+
return True
|
| 82 |
+
|
| 83 |
+
# Additionally, compare simplified symbolic expressions
|
| 84 |
+
if simplify(md_sympy - gt_sympy) == 0:
|
| 85 |
+
return True
|
| 86 |
+
except Exception:
|
| 87 |
+
pass # Ignore parsing errors or evaluation failures
|
| 88 |
+
|
| 89 |
+
return False
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
score_demo_prompt = """Please read the following example. Then determine whether the response is correct and type it
|
| 93 |
+
at the end of the prompt. It is worth noting that the final answer in the response is usually in \\boxed{},
|
| 94 |
+
You only need to compare the final answer in the response with the answer, without considering the logical
|
| 95 |
+
correctness of the response itself.
|
| 96 |
+
|
| 97 |
+
Response: The correct answer is:\n\nA
|
| 98 |
+
|
| 99 |
+
Answer: A
|
| 100 |
+
|
| 101 |
+
Correct_or_not: Correct
|
| 102 |
+
|
| 103 |
+
Response: The correct option is:\n\n\\[\n\\boxed{E}\n\\]
|
| 104 |
+
|
| 105 |
+
Answer: C
|
| 106 |
+
|
| 107 |
+
Correct_or_not: Incorrect
|
| 108 |
+
"""
|
EMMA/generate_response.py
ADDED
|
@@ -0,0 +1,194 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
import logging
|
| 5 |
+
from tqdm import tqdm
|
| 6 |
+
from models.qwen import Qwen_vllm_Model
|
| 7 |
+
from datasets import load_dataset, concatenate_datasets
|
| 8 |
+
from data_utils import load_yaml, verify_response, build_query
|
| 9 |
+
|
| 10 |
+
def do_generate(dataset_name, model_path, output_path, subject=['Math', 'Physics', 'Chemistry', 'Coding'], split='test', config_path='/user/konglingyu/VLMEvalKit/EMMA/configs/gpt.yaml', strategy='TrainCoT', save_every=20, rerun=False, greedy=0, max_tokens=4096, ngpu=1, logger=logging.getLogger(__name__), seed=42):
|
| 11 |
+
# Load Dataset
|
| 12 |
+
logger.info(f"Loading dataset {dataset_name}, subject: {subject}")
|
| 13 |
+
sub_dataset_list = []
|
| 14 |
+
for subj in subject:
|
| 15 |
+
sub_dataset = load_dataset(dataset_name, subj, split=split)
|
| 16 |
+
sub_dataset_list.append(sub_dataset)
|
| 17 |
+
dataset = concatenate_datasets(sub_dataset_list)
|
| 18 |
+
|
| 19 |
+
# Load Config
|
| 20 |
+
logger.info(f"Loading config")
|
| 21 |
+
config = load_yaml(config_path)
|
| 22 |
+
|
| 23 |
+
# Load Model
|
| 24 |
+
# If we were given a custom path, load that model, otherwise use a remote service model
|
| 25 |
+
logger.info(f"Loading local model {model_path}")
|
| 26 |
+
device = 0
|
| 27 |
+
world_size = 1
|
| 28 |
+
try:
|
| 29 |
+
device = int(os.environ["LOCAL_RANK"])
|
| 30 |
+
world_size = int(os.environ["WORLD_SIZE"])
|
| 31 |
+
dist_keys = [
|
| 32 |
+
"RANK",
|
| 33 |
+
"LOCAL_RANK",
|
| 34 |
+
"WORLD_SIZE",
|
| 35 |
+
"LOCAL_WORLD_SIZE",
|
| 36 |
+
"GROUP_RANK",
|
| 37 |
+
"ROLE_RANK",
|
| 38 |
+
"ROLE_NAME",
|
| 39 |
+
"OMP_NUM_THREADS",
|
| 40 |
+
"MASTER_ADDR",
|
| 41 |
+
"MASTER_PORT",
|
| 42 |
+
"TORCHELASTIC_USE_AGENT_STORE",
|
| 43 |
+
"TORCHELASTIC_MAX_RESTARTS",
|
| 44 |
+
"TORCHELASTIC_RUN_ID",
|
| 45 |
+
"TORCH_NCCL_ASYNC_ERROR_HANDLING",
|
| 46 |
+
"TORCHELASTIC_ERROR_FILE",
|
| 47 |
+
]
|
| 48 |
+
|
| 49 |
+
for dist_key in dist_keys:
|
| 50 |
+
del os.environ[dist_key]
|
| 51 |
+
except:
|
| 52 |
+
pass
|
| 53 |
+
|
| 54 |
+
if world_size > 1:
|
| 55 |
+
assert ngpu==1
|
| 56 |
+
|
| 57 |
+
model = Qwen_vllm_Model(model_path, greedy=greedy, max_tokens=max_tokens, parallel=ngpu, seed=seed, device=device)
|
| 58 |
+
|
| 59 |
+
logger.info(f"Model loaded!")
|
| 60 |
+
|
| 61 |
+
if world_size > 1:
|
| 62 |
+
logger.info(f"Using distributed mode with {world_size} GPUs, device {device}")
|
| 63 |
+
output_path = output_path.replace('.json', f'_{device}.json')
|
| 64 |
+
else:
|
| 65 |
+
logger.info(f"Using single GPU mode")
|
| 66 |
+
logger.info(f"Output path: {output_path}")
|
| 67 |
+
|
| 68 |
+
if os.path.exists(output_path):
|
| 69 |
+
logger.info("Results already exists.")
|
| 70 |
+
logger.info(f"Reading {output_path}")
|
| 71 |
+
with open(output_path, 'r') as f:
|
| 72 |
+
results = json.load(f)
|
| 73 |
+
else:
|
| 74 |
+
results = {}
|
| 75 |
+
|
| 76 |
+
skip_pids = []
|
| 77 |
+
if not rerun and results:
|
| 78 |
+
for pid, data in results.items():
|
| 79 |
+
if 'response' in data and verify_response(data['response']):
|
| 80 |
+
skip_pids.append(pid)
|
| 81 |
+
|
| 82 |
+
if len(skip_pids) > 0:
|
| 83 |
+
logger.info(
|
| 84 |
+
f"Found existing results file with {len(skip_pids)} problems with valid responses. Skipping these problems...")
|
| 85 |
+
|
| 86 |
+
logger.info(f"Starting to generate.....")
|
| 87 |
+
for idx, sample in enumerate(tqdm(dataset)):
|
| 88 |
+
pid = sample['pid']
|
| 89 |
+
if skip_pids and pid in skip_pids:
|
| 90 |
+
continue
|
| 91 |
+
if idx % world_size != device:
|
| 92 |
+
continue
|
| 93 |
+
sample = build_query(sample, config, strategy)
|
| 94 |
+
problem: dict = sample.copy()
|
| 95 |
+
for i in range(1, 6):
|
| 96 |
+
problem.pop('image_' + str(i))
|
| 97 |
+
|
| 98 |
+
try:
|
| 99 |
+
response = model.get_response(sample)
|
| 100 |
+
results[pid] = problem
|
| 101 |
+
results[pid]['response'] = response
|
| 102 |
+
except Exception as e:
|
| 103 |
+
logger.error(f"Error in generating answer for {pid}")
|
| 104 |
+
logger.error(e)
|
| 105 |
+
results[pid] = problem
|
| 106 |
+
results[pid]['error'] = str(e)
|
| 107 |
+
|
| 108 |
+
if idx == 2 or (idx % save_every == 0 and idx > 0) or idx == len(dataset) - 1:
|
| 109 |
+
try:
|
| 110 |
+
with open(output_path, 'w') as f:
|
| 111 |
+
f.write(json.dumps(results, indent=2))
|
| 112 |
+
logger.info(f"Save results to {output_path}")
|
| 113 |
+
except Exception as e:
|
| 114 |
+
logger.info(f"Error in saving {output_path}")
|
| 115 |
+
logger.info(e)
|
| 116 |
+
|
| 117 |
+
with open(output_path, 'w') as f:
|
| 118 |
+
f.write(json.dumps(results, indent=2))
|
| 119 |
+
logger.info(f"Save results to {output_path}")
|
| 120 |
+
|
| 121 |
+
logger.info("End Generation......")
|
| 122 |
+
|
| 123 |
+
def main():
|
| 124 |
+
parser = argparse.ArgumentParser()
|
| 125 |
+
parser.add_argument('--dataset_name', type=str, default='/root/LMUData/EMMA-mini')
|
| 126 |
+
parser.add_argument('--subject', nargs='+', type=str, default=['Math', 'Physics', 'Chemistry', 'Coding'])
|
| 127 |
+
parser.add_argument('--split', type=str, default='test')
|
| 128 |
+
parser.add_argument('--strategy', type=str, default='CoT', choices=['CoT', 'Direct', 'TrainCoT'])
|
| 129 |
+
parser.add_argument('--config_path', type=str, default="configs/gpt.yaml")
|
| 130 |
+
parser.add_argument('--output_path', type=str, default='results/test-full.json')
|
| 131 |
+
parser.add_argument('--save_every', type=int, default=20, help='save every n problems')
|
| 132 |
+
parser.add_argument('--rerun', action='store_true', help='rerun the answer generation')
|
| 133 |
+
# Local model
|
| 134 |
+
parser.add_argument('--model_path', type=str, default='/user/konglingyu/ckpts/Qwen2-VL-7B', help="local model path or huggingface model name")
|
| 135 |
+
parser.add_argument('--max_tokens', type=int, default=4096)
|
| 136 |
+
parser.add_argument('--greedy', type=int, default=0)
|
| 137 |
+
parser.add_argument('--ngpu', type=int, default=1)
|
| 138 |
+
|
| 139 |
+
args = parser.parse_args()
|
| 140 |
+
do_generate(
|
| 141 |
+
dataset_name=args.dataset_name,
|
| 142 |
+
model_path=args.model_path,
|
| 143 |
+
output_path=args.output_path,
|
| 144 |
+
subject=args.subject,
|
| 145 |
+
split=args.split,
|
| 146 |
+
config_path=args.config_path,
|
| 147 |
+
strategy=args.strategy,
|
| 148 |
+
save_every=args.save_every,
|
| 149 |
+
rerun=args.rerun,
|
| 150 |
+
greedy=args.greedy,
|
| 151 |
+
max_tokens=args.max_tokens,
|
| 152 |
+
ngpu=args.ngpu
|
| 153 |
+
)
|
| 154 |
+
|
| 155 |
+
|
| 156 |
+
|
| 157 |
+
if __name__ == "__main__":
|
| 158 |
+
logging.basicConfig(
|
| 159 |
+
level=os.environ.get("LOGLEVEL", "INFO").upper(),
|
| 160 |
+
format="[%(name)s] %(message)s",
|
| 161 |
+
datefmt="[%X]"
|
| 162 |
+
)
|
| 163 |
+
logger_blocklist = [
|
| 164 |
+
"asyncio",
|
| 165 |
+
"azure",
|
| 166 |
+
"azureml",
|
| 167 |
+
"datasets",
|
| 168 |
+
"httpx",
|
| 169 |
+
"httpcore",
|
| 170 |
+
"filelock",
|
| 171 |
+
"fsspec",
|
| 172 |
+
"msal",
|
| 173 |
+
"msrest",
|
| 174 |
+
"openai",
|
| 175 |
+
"PIL",
|
| 176 |
+
"urllib3",
|
| 177 |
+
]
|
| 178 |
+
for module in logger_blocklist:
|
| 179 |
+
logging.getLogger(module).setLevel(logging.WARNING)
|
| 180 |
+
if not os.path.exists("/root/LMUData"):
|
| 181 |
+
os.symlink("/user/konglingyu/LMUData", "/root/LMUData")
|
| 182 |
+
main()
|
| 183 |
+
|
| 184 |
+
|
| 185 |
+
|
| 186 |
+
|
| 187 |
+
|
| 188 |
+
|
| 189 |
+
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
|
| 194 |
+
|
EMMA/models/__init__.py
ADDED
|
File without changes
|
EMMA/models/claude.py
ADDED
|
@@ -0,0 +1,81 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import re
|
| 3 |
+
import base64
|
| 4 |
+
from io import BytesIO
|
| 5 |
+
|
| 6 |
+
from anthropic import Anthropic
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
def encode_image_to_base64(image):
|
| 10 |
+
buffered = BytesIO()
|
| 11 |
+
image.save(buffered, format="PNG")
|
| 12 |
+
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
|
| 13 |
+
return img_str
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
def create_message(sample):
|
| 17 |
+
query = sample['query']
|
| 18 |
+
all_contents = []
|
| 19 |
+
matches = re.findall(r"<(image_\d+)>", query)
|
| 20 |
+
split_text = re.split(r"<image_\d+>", query)
|
| 21 |
+
for i, fragment in enumerate(split_text):
|
| 22 |
+
if fragment.strip():
|
| 23 |
+
all_contents.extend([
|
| 24 |
+
{"type": "text", "text": fragment}
|
| 25 |
+
])
|
| 26 |
+
if i < len(matches):
|
| 27 |
+
if sample[matches[i]]:
|
| 28 |
+
img_base64 = encode_image_to_base64(sample[matches[i]])
|
| 29 |
+
all_contents.extend([
|
| 30 |
+
{
|
| 31 |
+
"type": "image",
|
| 32 |
+
"source": {
|
| 33 |
+
"type": "base64",
|
| 34 |
+
"media_type": "image/png",
|
| 35 |
+
"data": img_base64
|
| 36 |
+
}
|
| 37 |
+
}
|
| 38 |
+
])
|
| 39 |
+
else:
|
| 40 |
+
logging.error(
|
| 41 |
+
f"The image token {matches[i]} is in the query, but there is no corresponding image provided by the data")
|
| 42 |
+
|
| 43 |
+
messages = [
|
| 44 |
+
{
|
| 45 |
+
"role": "user",
|
| 46 |
+
"content": all_contents
|
| 47 |
+
}
|
| 48 |
+
]
|
| 49 |
+
return messages
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
# build claude class
|
| 53 |
+
class Claude_Model():
|
| 54 |
+
def __init__(
|
| 55 |
+
self,
|
| 56 |
+
client: Anthropic,
|
| 57 |
+
model="claude-3-5-sonnet-latest",
|
| 58 |
+
temperature=0,
|
| 59 |
+
max_tokens=1024
|
| 60 |
+
):
|
| 61 |
+
self.client = client
|
| 62 |
+
self.model = model
|
| 63 |
+
self.temperature = temperature
|
| 64 |
+
self.max_tokens = max_tokens
|
| 65 |
+
|
| 66 |
+
def get_response(self, sample):
|
| 67 |
+
messages = create_message(sample)
|
| 68 |
+
try:
|
| 69 |
+
|
| 70 |
+
v_response = self.client.messages.create(
|
| 71 |
+
model=self.model,
|
| 72 |
+
max_tokens=self.max_tokens,
|
| 73 |
+
temperature=self.temperature,
|
| 74 |
+
messages=messages
|
| 75 |
+
)
|
| 76 |
+
response = v_response.content[0].text
|
| 77 |
+
|
| 78 |
+
return response
|
| 79 |
+
except Exception as e:
|
| 80 |
+
print(e)
|
| 81 |
+
return None
|
EMMA/models/gpt.py
ADDED
|
@@ -0,0 +1,103 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import logging
|
| 2 |
+
import re
|
| 3 |
+
import base64
|
| 4 |
+
from io import BytesIO
|
| 5 |
+
import time
|
| 6 |
+
|
| 7 |
+
from openai import OpenAI
|
| 8 |
+
|
| 9 |
+
|
| 10 |
+
def encode_image_to_base64(image):
|
| 11 |
+
buffered = BytesIO()
|
| 12 |
+
image.save(buffered, format="PNG")
|
| 13 |
+
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
|
| 14 |
+
return img_str
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
def create_message(sample):
|
| 18 |
+
query = sample['query']
|
| 19 |
+
all_contents = []
|
| 20 |
+
matches = re.findall(r"<(image_\d+)>", query)
|
| 21 |
+
split_text = re.split(r"<image_\d+>", query)
|
| 22 |
+
for i, fragment in enumerate(split_text):
|
| 23 |
+
if fragment.strip():
|
| 24 |
+
all_contents.extend([
|
| 25 |
+
{"type": "text", "text": fragment}
|
| 26 |
+
])
|
| 27 |
+
if i < len(matches):
|
| 28 |
+
if sample[matches[i]]:
|
| 29 |
+
img_base64 = encode_image_to_base64(sample[matches[i]])
|
| 30 |
+
all_contents.extend([
|
| 31 |
+
{
|
| 32 |
+
"type": "image_url",
|
| 33 |
+
"image_url": {
|
| 34 |
+
"url": f"data:image/png;base64,{img_base64}"
|
| 35 |
+
}
|
| 36 |
+
}
|
| 37 |
+
])
|
| 38 |
+
else:
|
| 39 |
+
logging.error(
|
| 40 |
+
f"The image token {matches[i]} is in the query, but there is no corresponding image provided by the data")
|
| 41 |
+
|
| 42 |
+
messages = [
|
| 43 |
+
{
|
| 44 |
+
"role": "user",
|
| 45 |
+
"content": all_contents
|
| 46 |
+
}
|
| 47 |
+
]
|
| 48 |
+
return messages
|
| 49 |
+
|
| 50 |
+
|
| 51 |
+
# build gpt class
|
| 52 |
+
class GPT_Model:
|
| 53 |
+
def __init__(
|
| 54 |
+
self,
|
| 55 |
+
client: OpenAI,
|
| 56 |
+
model="chatgpt-4o-latest",
|
| 57 |
+
temperature=0,
|
| 58 |
+
max_tokens=1024,
|
| 59 |
+
retry_attempts = 5
|
| 60 |
+
):
|
| 61 |
+
self.client = client
|
| 62 |
+
self.model = model
|
| 63 |
+
self.temperature = temperature
|
| 64 |
+
self.max_tokens = max_tokens
|
| 65 |
+
self.retry_attempts = retry_attempts
|
| 66 |
+
|
| 67 |
+
def get_response(self, sample):
|
| 68 |
+
attempt = 0
|
| 69 |
+
messages = create_message(sample)
|
| 70 |
+
|
| 71 |
+
while attempt < self.retry_attempts:
|
| 72 |
+
try:
|
| 73 |
+
response = self.client.chat.completions.create(
|
| 74 |
+
model=self.model,
|
| 75 |
+
messages=messages,
|
| 76 |
+
temperature=self.temperature,
|
| 77 |
+
max_tokens=self.max_tokens,
|
| 78 |
+
)
|
| 79 |
+
|
| 80 |
+
return response.choices[0].message.content.strip()
|
| 81 |
+
except Exception as e:
|
| 82 |
+
logging.error(f"Attempt {attempt + 1} failed: {e}")
|
| 83 |
+
|
| 84 |
+
if 'error' in str(e) and 'message' in str(e):
|
| 85 |
+
error_message = str(e)
|
| 86 |
+
if 'The server had an error processing your request.' in error_message:
|
| 87 |
+
sleep_time = 30
|
| 88 |
+
logging.error(f"Server error, retrying in {sleep_time}s...")
|
| 89 |
+
time.sleep(sleep_time)
|
| 90 |
+
elif 'Please try again in ' in error_message:
|
| 91 |
+
sleep_time = float(error_message.split('Please try again in ')[1].split('s.')[0])
|
| 92 |
+
logging.error(f"Rate limit exceeded, retrying in {sleep_time * 2}s...")
|
| 93 |
+
time.sleep(sleep_time * 2)
|
| 94 |
+
elif 'RESOURCE_EXHAUSTED' in error_message:
|
| 95 |
+
sleep_time = 30
|
| 96 |
+
logging.error(f"Gemini rate limit, retrying in {sleep_time}s...")
|
| 97 |
+
time.sleep(sleep_time)
|
| 98 |
+
else:
|
| 99 |
+
print("Unknown error, skipping this request.")
|
| 100 |
+
break
|
| 101 |
+
attempt += 1
|
| 102 |
+
|
| 103 |
+
return None
|
EMMA/models/internvl.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
import logging
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
import torchvision.transforms as T
|
| 6 |
+
from torchvision.transforms.functional import InterpolationMode
|
| 7 |
+
from transformers import AutoModel, AutoTokenizer
|
| 8 |
+
import math
|
| 9 |
+
|
| 10 |
+
IMAGENET_MEAN = (0.485, 0.456, 0.406)
|
| 11 |
+
IMAGENET_STD = (0.229, 0.224, 0.225)
|
| 12 |
+
|
| 13 |
+
|
| 14 |
+
def split_model(model_name):
|
| 15 |
+
device_map = {}
|
| 16 |
+
world_size = torch.cuda.device_count()
|
| 17 |
+
num_layers = {
|
| 18 |
+
'InternVL2-1B': 24, 'InternVL2-2B': 24, 'InternVL2-4B': 32, 'InternVL2-8B': 32,
|
| 19 |
+
'InternVL2-26B': 48, 'InternVL2-40B': 60, 'InternVL2-Llama3-76B': 80}[model_name]
|
| 20 |
+
# Since the first GPU will be used for ViT, treat it as half a GPU.
|
| 21 |
+
num_layers_per_gpu = math.ceil(num_layers / (world_size - 0.5))
|
| 22 |
+
num_layers_per_gpu = [num_layers_per_gpu] * world_size
|
| 23 |
+
num_layers_per_gpu[0] = math.ceil(num_layers_per_gpu[0] * 0.5)
|
| 24 |
+
layer_cnt = 0
|
| 25 |
+
for i, num_layer in enumerate(num_layers_per_gpu):
|
| 26 |
+
for j in range(num_layer):
|
| 27 |
+
device_map[f'language_model.model.layers.{layer_cnt}'] = i
|
| 28 |
+
layer_cnt += 1
|
| 29 |
+
device_map['vision_model'] = 0
|
| 30 |
+
device_map['mlp1'] = 0
|
| 31 |
+
device_map['language_model.model.tok_embeddings'] = 0
|
| 32 |
+
device_map['language_model.model.embed_tokens'] = 0
|
| 33 |
+
device_map['language_model.output'] = 0
|
| 34 |
+
device_map['language_model.model.norm'] = 0
|
| 35 |
+
device_map['language_model.lm_head'] = 0
|
| 36 |
+
device_map[f'language_model.model.layers.{num_layers - 1}'] = 0
|
| 37 |
+
|
| 38 |
+
return device_map
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
def build_transform(input_size):
|
| 42 |
+
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
|
| 43 |
+
transform = T.Compose([
|
| 44 |
+
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
|
| 45 |
+
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
|
| 46 |
+
T.ToTensor(),
|
| 47 |
+
T.Normalize(mean=MEAN, std=STD)
|
| 48 |
+
])
|
| 49 |
+
return transform
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
|
| 53 |
+
best_ratio_diff = float('inf')
|
| 54 |
+
best_ratio = (1, 1)
|
| 55 |
+
area = width * height
|
| 56 |
+
for ratio in target_ratios:
|
| 57 |
+
target_aspect_ratio = ratio[0] / ratio[1]
|
| 58 |
+
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
|
| 59 |
+
if ratio_diff < best_ratio_diff:
|
| 60 |
+
best_ratio_diff = ratio_diff
|
| 61 |
+
best_ratio = ratio
|
| 62 |
+
elif ratio_diff == best_ratio_diff:
|
| 63 |
+
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
|
| 64 |
+
best_ratio = ratio
|
| 65 |
+
return best_ratio
|
| 66 |
+
|
| 67 |
+
|
| 68 |
+
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
|
| 69 |
+
orig_width, orig_height = image.size
|
| 70 |
+
aspect_ratio = orig_width / orig_height
|
| 71 |
+
|
| 72 |
+
# calculate the existing image aspect ratio
|
| 73 |
+
target_ratios = set(
|
| 74 |
+
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
|
| 75 |
+
i * j <= max_num and i * j >= min_num)
|
| 76 |
+
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
|
| 77 |
+
|
| 78 |
+
# find the closest aspect ratio to the target
|
| 79 |
+
target_aspect_ratio = find_closest_aspect_ratio(
|
| 80 |
+
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
|
| 81 |
+
|
| 82 |
+
# calculate the target width and height
|
| 83 |
+
target_width = image_size * target_aspect_ratio[0]
|
| 84 |
+
target_height = image_size * target_aspect_ratio[1]
|
| 85 |
+
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
|
| 86 |
+
|
| 87 |
+
# resize the image
|
| 88 |
+
resized_img = image.resize((target_width, target_height))
|
| 89 |
+
processed_images = []
|
| 90 |
+
for i in range(blocks):
|
| 91 |
+
box = (
|
| 92 |
+
(i % (target_width // image_size)) * image_size,
|
| 93 |
+
(i // (target_width // image_size)) * image_size,
|
| 94 |
+
((i % (target_width // image_size)) + 1) * image_size,
|
| 95 |
+
((i // (target_width // image_size)) + 1) * image_size
|
| 96 |
+
)
|
| 97 |
+
# split the image
|
| 98 |
+
split_img = resized_img.crop(box)
|
| 99 |
+
processed_images.append(split_img)
|
| 100 |
+
assert len(processed_images) == blocks
|
| 101 |
+
if use_thumbnail and len(processed_images) != 1:
|
| 102 |
+
thumbnail_img = image.resize((image_size, image_size))
|
| 103 |
+
processed_images.append(thumbnail_img)
|
| 104 |
+
return processed_images
|
| 105 |
+
|
| 106 |
+
|
| 107 |
+
def load_image(image, input_size=448, max_num=12):
|
| 108 |
+
transform = build_transform(input_size=input_size)
|
| 109 |
+
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
|
| 110 |
+
pixel_values = [transform(image) for image in images]
|
| 111 |
+
pixel_values = torch.stack(pixel_values)
|
| 112 |
+
return pixel_values
|
| 113 |
+
|
| 114 |
+
|
| 115 |
+
def process_query(sample):
|
| 116 |
+
query = sample['query']
|
| 117 |
+
matches = re.findall(r"<(image_\d+)>", query)
|
| 118 |
+
modified_query = re.sub(r"<image_\d+>", "<image>", query)
|
| 119 |
+
images = []
|
| 120 |
+
for match in matches:
|
| 121 |
+
if sample[match]:
|
| 122 |
+
images.append(sample[match])
|
| 123 |
+
else:
|
| 124 |
+
logging.error(f"The image token <{match}> is in the query, but there is no corresponding image provided by the data")
|
| 125 |
+
return modified_query, images
|
| 126 |
+
|
| 127 |
+
|
| 128 |
+
class Internvl_Model:
|
| 129 |
+
def __init__(
|
| 130 |
+
self,
|
| 131 |
+
model_path,
|
| 132 |
+
temperature=0,
|
| 133 |
+
max_tokens=1024
|
| 134 |
+
):
|
| 135 |
+
self.temperature = temperature
|
| 136 |
+
self.max_tokens = max_tokens
|
| 137 |
+
self.device_map = split_model('InternVL2-Llama3-76B')
|
| 138 |
+
self.model = AutoModel.from_pretrained(
|
| 139 |
+
model_path,
|
| 140 |
+
torch_dtype=torch.bfloat16,
|
| 141 |
+
low_cpu_mem_usage=True,
|
| 142 |
+
use_flash_attn=True,
|
| 143 |
+
trust_remote_code=True,
|
| 144 |
+
device_map=self.device_map).eval()
|
| 145 |
+
self.tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False)
|
| 146 |
+
|
| 147 |
+
def get_response(self, sample):
|
| 148 |
+
model = self.model
|
| 149 |
+
tokenizer = self.tokenizer
|
| 150 |
+
|
| 151 |
+
try:
|
| 152 |
+
query, images = process_query(sample)
|
| 153 |
+
pixel_values_list = []
|
| 154 |
+
num_patches_list = []
|
| 155 |
+
|
| 156 |
+
for image in images:
|
| 157 |
+
pixel_value = load_image(image, max_num=12).to(torch.bfloat16).cuda()
|
| 158 |
+
pixel_values_list.append(pixel_value)
|
| 159 |
+
|
| 160 |
+
num_patches_list.append(pixel_value.size(0))
|
| 161 |
+
|
| 162 |
+
pixel_values = torch.cat(pixel_values_list, dim=0)
|
| 163 |
+
|
| 164 |
+
generation_config = dict(max_new_tokens=self.max_tokens, do_sample=True, temperature=self.temperature)
|
| 165 |
+
|
| 166 |
+
# single-image single-round conversation
|
| 167 |
+
response = model.chat(tokenizer, pixel_values, query, generation_config,
|
| 168 |
+
num_patches_list=num_patches_list)
|
| 169 |
+
return response
|
| 170 |
+
except Exception as e:
|
| 171 |
+
print(e)
|
| 172 |
+
return None
|
EMMA/models/llava.py
ADDED
|
@@ -0,0 +1,82 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
import logging
|
| 3 |
+
|
| 4 |
+
import torch
|
| 5 |
+
from transformers import AutoProcessor, LlavaOnevisionForConditionalGeneration
|
| 6 |
+
|
| 7 |
+
def create_message(sample):
|
| 8 |
+
query = sample['query']
|
| 9 |
+
all_contents = []
|
| 10 |
+
matches = re.findall(r"<(image_\d+)>", query)
|
| 11 |
+
split_text = re.split(r"<image_\d+>", query)
|
| 12 |
+
images = []
|
| 13 |
+
for i, fragment in enumerate(split_text):
|
| 14 |
+
if fragment.strip():
|
| 15 |
+
all_contents.extend([
|
| 16 |
+
{"type": "text", "text": fragment}
|
| 17 |
+
])
|
| 18 |
+
if i < len(matches):
|
| 19 |
+
if sample[matches[i]]:
|
| 20 |
+
all_contents.extend([
|
| 21 |
+
{"type": "image"}
|
| 22 |
+
])
|
| 23 |
+
images.append(sample[matches[i]])
|
| 24 |
+
else:
|
| 25 |
+
logging.error(
|
| 26 |
+
f"The image token {matches[i]} is in the query, but there is no corresponding image provided by the data")
|
| 27 |
+
messages = [
|
| 28 |
+
{
|
| 29 |
+
"role": "user",
|
| 30 |
+
"content": all_contents
|
| 31 |
+
}
|
| 32 |
+
]
|
| 33 |
+
return messages, images
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
class Llava_Model:
|
| 37 |
+
def __init__(
|
| 38 |
+
self,
|
| 39 |
+
model_path,
|
| 40 |
+
temperature=0,
|
| 41 |
+
max_tokens=1024
|
| 42 |
+
):
|
| 43 |
+
self.temperature = temperature
|
| 44 |
+
self.max_tokens = max_tokens
|
| 45 |
+
self.model = LlavaOnevisionForConditionalGeneration.from_pretrained(
|
| 46 |
+
model_path,
|
| 47 |
+
torch_dtype=torch.float16,
|
| 48 |
+
device_map="auto",
|
| 49 |
+
use_flash_attention_2=True
|
| 50 |
+
)
|
| 51 |
+
self.processor = AutoProcessor.from_pretrained(model_path)
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def get_response(self, sample):
|
| 55 |
+
|
| 56 |
+
model = self.model
|
| 57 |
+
processor = self.processor
|
| 58 |
+
|
| 59 |
+
try:
|
| 60 |
+
messages, images = create_message(sample)
|
| 61 |
+
|
| 62 |
+
input_text = processor.apply_chat_template(messages, add_generation_prompt=True)
|
| 63 |
+
inputs = processor(
|
| 64 |
+
images=images,
|
| 65 |
+
text=input_text,
|
| 66 |
+
add_special_tokens=False,
|
| 67 |
+
return_tensors="pt"
|
| 68 |
+
).to(model.device, torch.float16)
|
| 69 |
+
|
| 70 |
+
output = model.generate(**inputs, do_sample=True, temperature=self.temperature, max_new_tokens=self.max_tokens)
|
| 71 |
+
response = processor.decode(output[0], skip_special_tokens=True)
|
| 72 |
+
|
| 73 |
+
assistant_index = response.find("assistant")
|
| 74 |
+
if assistant_index != -1:
|
| 75 |
+
final_answer = response[assistant_index + len("assistant"):].strip()
|
| 76 |
+
else:
|
| 77 |
+
final_answer = response.strip()
|
| 78 |
+
return final_answer
|
| 79 |
+
|
| 80 |
+
except Exception as e:
|
| 81 |
+
print(e)
|
| 82 |
+
return None
|
EMMA/models/qwen.py
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import re
|
| 2 |
+
import logging
|
| 3 |
+
import base64
|
| 4 |
+
from io import BytesIO
|
| 5 |
+
import os
|
| 6 |
+
|
| 7 |
+
from transformers import Qwen2VLForConditionalGeneration, AutoTokenizer, AutoProcessor
|
| 8 |
+
from qwen_vl_utils import process_vision_info
|
| 9 |
+
import torch
|
| 10 |
+
from transformers import Qwen2_5_VLForConditionalGeneration, AutoProcessor
|
| 11 |
+
from vllm import LLM, SamplingParams
|
| 12 |
+
|
| 13 |
+
def encode_image_to_base64(image):
|
| 14 |
+
buffered = BytesIO()
|
| 15 |
+
image.save(buffered, format="PNG")
|
| 16 |
+
img_str = base64.b64encode(buffered.getvalue()).decode("utf-8")
|
| 17 |
+
return img_str
|
| 18 |
+
|
| 19 |
+
def create_message(sample):
|
| 20 |
+
query = sample['query']
|
| 21 |
+
all_contents = []
|
| 22 |
+
matches = re.findall(r"<(image_\d+)>", query)
|
| 23 |
+
split_text = re.split(r"<image_\d+>", query)
|
| 24 |
+
for i, fragment in enumerate(split_text):
|
| 25 |
+
if fragment.strip():
|
| 26 |
+
all_contents.extend([
|
| 27 |
+
{"type": "text", "text": fragment}
|
| 28 |
+
])
|
| 29 |
+
if i < len(matches):
|
| 30 |
+
if sample[matches[i]]:
|
| 31 |
+
img_base64 = encode_image_to_base64(sample[matches[i]])
|
| 32 |
+
all_contents.extend([
|
| 33 |
+
{
|
| 34 |
+
"type": "image",
|
| 35 |
+
"image": f"data:image/png;base64,{img_base64}"
|
| 36 |
+
}
|
| 37 |
+
])
|
| 38 |
+
else:
|
| 39 |
+
logging.error(
|
| 40 |
+
f"The image token {matches[i]} is in the query, but there is no corresponding image provided by the data")
|
| 41 |
+
|
| 42 |
+
messages = [
|
| 43 |
+
{
|
| 44 |
+
"role": "user",
|
| 45 |
+
"content": all_contents
|
| 46 |
+
}
|
| 47 |
+
]
|
| 48 |
+
return messages
|
| 49 |
+
|
| 50 |
+
class Qwen_Model:
|
| 51 |
+
def __init__(
|
| 52 |
+
self,
|
| 53 |
+
model_path,
|
| 54 |
+
temperature=0,
|
| 55 |
+
max_tokens=1024
|
| 56 |
+
):
|
| 57 |
+
self.model_path = model_path
|
| 58 |
+
self.temperature = temperature
|
| 59 |
+
self.max_tokens = max_tokens
|
| 60 |
+
self.model = Qwen2VLForConditionalGeneration.from_pretrained(self.model_path, torch_dtype=torch.bfloat16,
|
| 61 |
+
attn_implementation="flash_attention_2",
|
| 62 |
+
device_map="auto", )
|
| 63 |
+
self.processor = AutoProcessor.from_pretrained(self.model_path)
|
| 64 |
+
|
| 65 |
+
|
| 66 |
+
def get_response(self, sample):
|
| 67 |
+
|
| 68 |
+
model = self.model
|
| 69 |
+
processor = self.processor
|
| 70 |
+
|
| 71 |
+
try:
|
| 72 |
+
messages = create_message(sample)
|
| 73 |
+
|
| 74 |
+
text = processor.apply_chat_template(
|
| 75 |
+
messages, tokenize=False, add_generation_prompt=True, add_vision_id=True
|
| 76 |
+
)
|
| 77 |
+
image_inputs, video_inputs = process_vision_info(messages)
|
| 78 |
+
inputs = processor(
|
| 79 |
+
text=[text],
|
| 80 |
+
images=image_inputs,
|
| 81 |
+
videos=video_inputs,
|
| 82 |
+
padding=True,
|
| 83 |
+
return_tensors="pt",
|
| 84 |
+
)
|
| 85 |
+
inputs = inputs.to("cuda")
|
| 86 |
+
|
| 87 |
+
# Inference: Generation of the output
|
| 88 |
+
generated_ids = model.generate(**inputs, max_new_tokens=self.max_tokens, temperature=self.temperature)
|
| 89 |
+
generated_ids_trimmed = [
|
| 90 |
+
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
| 91 |
+
]
|
| 92 |
+
response = processor.batch_decode(
|
| 93 |
+
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 94 |
+
)
|
| 95 |
+
|
| 96 |
+
return response[0]
|
| 97 |
+
except Exception as e:
|
| 98 |
+
print(e)
|
| 99 |
+
return None
|
| 100 |
+
|
| 101 |
+
|
| 102 |
+
|
| 103 |
+
class Qwen2_5_Model:
|
| 104 |
+
def __init__(
|
| 105 |
+
self,
|
| 106 |
+
model_path="Qwen/Qwen2.5-VL-72B-Instruct",
|
| 107 |
+
temperature=0,
|
| 108 |
+
max_tokens=1024
|
| 109 |
+
):
|
| 110 |
+
self.model_path = model_path
|
| 111 |
+
self.temperature = temperature
|
| 112 |
+
self.max_tokens = max_tokens
|
| 113 |
+
|
| 114 |
+
self.model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
|
| 115 |
+
self.model_path,
|
| 116 |
+
torch_dtype=torch.bfloat16,
|
| 117 |
+
attn_implementation="flash_attention_2",
|
| 118 |
+
device_map="auto"
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
self.processor = AutoProcessor.from_pretrained(self.model_path)
|
| 122 |
+
|
| 123 |
+
|
| 124 |
+
def get_response(self, sample):
|
| 125 |
+
|
| 126 |
+
model = self.model
|
| 127 |
+
processor = self.processor
|
| 128 |
+
|
| 129 |
+
try:
|
| 130 |
+
messages = create_message(sample)
|
| 131 |
+
|
| 132 |
+
text = processor.apply_chat_template(
|
| 133 |
+
messages, tokenize=False, add_generation_prompt=True, add_vision_id=True
|
| 134 |
+
)
|
| 135 |
+
image_inputs, video_inputs = process_vision_info(messages)
|
| 136 |
+
inputs = processor(
|
| 137 |
+
text=[text],
|
| 138 |
+
images=image_inputs,
|
| 139 |
+
videos=video_inputs,
|
| 140 |
+
padding=True,
|
| 141 |
+
return_tensors="pt",
|
| 142 |
+
)
|
| 143 |
+
inputs = inputs.to("cuda")
|
| 144 |
+
|
| 145 |
+
# Inference: Generation of the output
|
| 146 |
+
generated_ids = model.generate(**inputs, max_new_tokens=self.max_tokens, temperature=self.temperature)
|
| 147 |
+
generated_ids_trimmed = [
|
| 148 |
+
out_ids[len(in_ids):] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
|
| 149 |
+
]
|
| 150 |
+
response = processor.batch_decode(
|
| 151 |
+
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
|
| 152 |
+
)
|
| 153 |
+
|
| 154 |
+
return response[0]
|
| 155 |
+
except Exception as e:
|
| 156 |
+
print(e)
|
| 157 |
+
return None
|
| 158 |
+
|
| 159 |
+
class Qwen_vllm_Model:
|
| 160 |
+
def __init__(
|
| 161 |
+
self,
|
| 162 |
+
model_path,
|
| 163 |
+
greedy=1,
|
| 164 |
+
max_tokens=1024,
|
| 165 |
+
parallel=1,
|
| 166 |
+
seed=42,
|
| 167 |
+
device=0
|
| 168 |
+
):
|
| 169 |
+
self.model_path = model_path
|
| 170 |
+
self.max_tokens = max_tokens
|
| 171 |
+
|
| 172 |
+
self.model = LLM(
|
| 173 |
+
model=model_path,
|
| 174 |
+
enable_prefix_caching=True,
|
| 175 |
+
trust_remote_code=True,
|
| 176 |
+
limit_mm_per_prompt={"image": 8, "video": 1},
|
| 177 |
+
tensor_parallel_size=parallel,
|
| 178 |
+
device=device
|
| 179 |
+
)
|
| 180 |
+
self.sampling_params = SamplingParams(
|
| 181 |
+
temperature=0 if greedy else 1,
|
| 182 |
+
top_p=0.001 if greedy else 1,
|
| 183 |
+
top_k=1 if greedy else -1,
|
| 184 |
+
repetition_penalty=1,
|
| 185 |
+
max_tokens=max_tokens,
|
| 186 |
+
stop_token_ids=[],
|
| 187 |
+
seed=seed
|
| 188 |
+
)
|
| 189 |
+
self.processor = AutoProcessor.from_pretrained(self.model_path)
|
| 190 |
+
|
| 191 |
+
|
| 192 |
+
def get_response(self, sample):
|
| 193 |
+
try:
|
| 194 |
+
messages = create_message(sample)
|
| 195 |
+
|
| 196 |
+
text = self.processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
|
| 197 |
+
image_inputs, _ = process_vision_info([messages])
|
| 198 |
+
inputs = {
|
| 199 |
+
"prompt": text,
|
| 200 |
+
"multi_modal_data": {'image': image_inputs},
|
| 201 |
+
}
|
| 202 |
+
|
| 203 |
+
out = self.model.generate(
|
| 204 |
+
inputs,
|
| 205 |
+
sampling_params=self.sampling_params,
|
| 206 |
+
use_tqdm=False
|
| 207 |
+
)
|
| 208 |
+
response = out[0].outputs[0].text
|
| 209 |
+
return response
|
| 210 |
+
except Exception as e:
|
| 211 |
+
print(e)
|
| 212 |
+
return None
|
EMMA/scripts/evaluation_fast.sh
ADDED
|
@@ -0,0 +1,4 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python evaluate.py \
|
| 2 |
+
--results_dir 'path_to_your_results_dir' \
|
| 3 |
+
--response_label 'response' \
|
| 4 |
+
--save_every 20
|
EMMA/scripts/evaluation_llm.sh
ADDED
|
@@ -0,0 +1,7 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
python evaluate.py \
|
| 2 |
+
--results_dir 'path_to_your_results_dir' \
|
| 3 |
+
--response_label 'response' \
|
| 4 |
+
--save_every 20 \
|
| 5 |
+
--gpt_eval \
|
| 6 |
+
--api_key '' \
|
| 7 |
+
--model 'chatgpt-4o-latest'
|
EMMA/scripts/run_closesource.sh
ADDED
|
@@ -0,0 +1,47 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
python generate_response.py \
|
| 3 |
+
--dataset_name 'luckychao/EMMA' \
|
| 4 |
+
--split 'test' \
|
| 5 |
+
--subject 'Math' 'Physics' 'Chemistry' 'Coding' \
|
| 6 |
+
--strategy 'CoT' \
|
| 7 |
+
--config_path 'configs/gpt.yaml' \
|
| 8 |
+
--model 'remote-model-name' \
|
| 9 |
+
--api_key '' \
|
| 10 |
+
--output_path 'path_to_output_file' \
|
| 11 |
+
--max_tokens 4096 \
|
| 12 |
+
--temperature 0 \
|
| 13 |
+
--save_every 20
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
|
| 47 |
+
|
EMMA/scripts/run_opensource.sh
ADDED
|
@@ -0,0 +1,46 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
#!/bin/bash
|
| 2 |
+
python generate_response.py \
|
| 3 |
+
--dataset_name 'luckychao/EMMA' \
|
| 4 |
+
--split 'test' \
|
| 5 |
+
--subject 'Math' 'Physics' 'Chemistry' 'Coding' \
|
| 6 |
+
--strategy 'CoT' \
|
| 7 |
+
--config_path 'configs/gpt.yaml' \
|
| 8 |
+
--model_path 'path_to_your_local_model' \
|
| 9 |
+
--output_path 'path_to_output_file' \
|
| 10 |
+
--max_tokens 4096 \
|
| 11 |
+
--temperature 0.7 \
|
| 12 |
+
--save_every 20
|
| 13 |
+
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
|
| 18 |
+
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
|
| 30 |
+
|
| 31 |
+
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
|
| 35 |
+
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
|
LICENSE
ADDED
|
@@ -0,0 +1,203 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Copyright 2023 VLMEvalKit Authors. All rights reserved.
|
| 2 |
+
|
| 3 |
+
Apache License
|
| 4 |
+
Version 2.0, January 2004
|
| 5 |
+
http://www.apache.org/licenses/
|
| 6 |
+
|
| 7 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 8 |
+
|
| 9 |
+
1. Definitions.
|
| 10 |
+
|
| 11 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 12 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 13 |
+
|
| 14 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 15 |
+
the copyright owner that is granting the License.
|
| 16 |
+
|
| 17 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 18 |
+
other entities that control, are controlled by, or are under common
|
| 19 |
+
control with that entity. For the purposes of this definition,
|
| 20 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 21 |
+
direction or management of such entity, whether by contract or
|
| 22 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 23 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 24 |
+
|
| 25 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 26 |
+
exercising permissions granted by this License.
|
| 27 |
+
|
| 28 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 29 |
+
including but not limited to software source code, documentation
|
| 30 |
+
source, and configuration files.
|
| 31 |
+
|
| 32 |
+
"Object" form shall mean any form resulting from mechanical
|
| 33 |
+
transformation or translation of a Source form, including but
|
| 34 |
+
not limited to compiled object code, generated documentation,
|
| 35 |
+
and conversions to other media types.
|
| 36 |
+
|
| 37 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 38 |
+
Object form, made available under the License, as indicated by a
|
| 39 |
+
copyright notice that is included in or attached to the work
|
| 40 |
+
(an example is provided in the Appendix below).
|
| 41 |
+
|
| 42 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 43 |
+
form, that is based on (or derived from) the Work and for which the
|
| 44 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 45 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 46 |
+
of this License, Derivative Works shall not include works that remain
|
| 47 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 48 |
+
the Work and Derivative Works thereof.
|
| 49 |
+
|
| 50 |
+
"Contribution" shall mean any work of authorship, including
|
| 51 |
+
the original version of the Work and any modifications or additions
|
| 52 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 53 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 54 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 55 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 56 |
+
means any form of electronic, verbal, or written communication sent
|
| 57 |
+
to the Licensor or its representatives, including but not limited to
|
| 58 |
+
communication on electronic mailing lists, source code control systems,
|
| 59 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 60 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 61 |
+
excluding communication that is conspicuously marked or otherwise
|
| 62 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 63 |
+
|
| 64 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 65 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 66 |
+
subsequently incorporated within the Work.
|
| 67 |
+
|
| 68 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 69 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 70 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 71 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 72 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 73 |
+
Work and such Derivative Works in Source or Object form.
|
| 74 |
+
|
| 75 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 76 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 77 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 78 |
+
(except as stated in this section) patent license to make, have made,
|
| 79 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 80 |
+
where such license applies only to those patent claims licensable
|
| 81 |
+
by such Contributor that are necessarily infringed by their
|
| 82 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 83 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 84 |
+
institute patent litigation against any entity (including a
|
| 85 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 86 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 87 |
+
or contributory patent infringement, then any patent licenses
|
| 88 |
+
granted to You under this License for that Work shall terminate
|
| 89 |
+
as of the date such litigation is filed.
|
| 90 |
+
|
| 91 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 92 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 93 |
+
modifications, and in Source or Object form, provided that You
|
| 94 |
+
meet the following conditions:
|
| 95 |
+
|
| 96 |
+
(a) You must give any other recipients of the Work or
|
| 97 |
+
Derivative Works a copy of this License; and
|
| 98 |
+
|
| 99 |
+
(b) You must cause any modified files to carry prominent notices
|
| 100 |
+
stating that You changed the files; and
|
| 101 |
+
|
| 102 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 103 |
+
that You distribute, all copyright, patent, trademark, and
|
| 104 |
+
attribution notices from the Source form of the Work,
|
| 105 |
+
excluding those notices that do not pertain to any part of
|
| 106 |
+
the Derivative Works; and
|
| 107 |
+
|
| 108 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 109 |
+
distribution, then any Derivative Works that You distribute must
|
| 110 |
+
include a readable copy of the attribution notices contained
|
| 111 |
+
within such NOTICE file, excluding those notices that do not
|
| 112 |
+
pertain to any part of the Derivative Works, in at least one
|
| 113 |
+
of the following places: within a NOTICE text file distributed
|
| 114 |
+
as part of the Derivative Works; within the Source form or
|
| 115 |
+
documentation, if provided along with the Derivative Works; or,
|
| 116 |
+
within a display generated by the Derivative Works, if and
|
| 117 |
+
wherever such third-party notices normally appear. The contents
|
| 118 |
+
of the NOTICE file are for informational purposes only and
|
| 119 |
+
do not modify the License. You may add Your own attribution
|
| 120 |
+
notices within Derivative Works that You distribute, alongside
|
| 121 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 122 |
+
that such additional attribution notices cannot be construed
|
| 123 |
+
as modifying the License.
|
| 124 |
+
|
| 125 |
+
You may add Your own copyright statement to Your modifications and
|
| 126 |
+
may provide additional or different license terms and conditions
|
| 127 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 128 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 129 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 130 |
+
the conditions stated in this License.
|
| 131 |
+
|
| 132 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 133 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 134 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 135 |
+
this License, without any additional terms or conditions.
|
| 136 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 137 |
+
the terms of any separate license agreement you may have executed
|
| 138 |
+
with Licensor regarding such Contributions.
|
| 139 |
+
|
| 140 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 141 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 142 |
+
except as required for reasonable and customary use in describing the
|
| 143 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 144 |
+
|
| 145 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 146 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 147 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 148 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 149 |
+
implied, including, without limitation, any warranties or conditions
|
| 150 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 151 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 152 |
+
appropriateness of using or redistributing the Work and assume any
|
| 153 |
+
risks associated with Your exercise of permissions under this License.
|
| 154 |
+
|
| 155 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 156 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 157 |
+
unless required by applicable law (such as deliberate and grossly
|
| 158 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 159 |
+
liable to You for damages, including any direct, indirect, special,
|
| 160 |
+
incidental, or consequential damages of any character arising as a
|
| 161 |
+
result of this License or out of the use or inability to use the
|
| 162 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 163 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 164 |
+
other commercial damages or losses), even if such Contributor
|
| 165 |
+
has been advised of the possibility of such damages.
|
| 166 |
+
|
| 167 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 168 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 169 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 170 |
+
or other liability obligations and/or rights consistent with this
|
| 171 |
+
License. However, in accepting such obligations, You may act only
|
| 172 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 173 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 174 |
+
defend, and hold each Contributor harmless for any liability
|
| 175 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 176 |
+
of your accepting any such warranty or additional liability.
|
| 177 |
+
|
| 178 |
+
END OF TERMS AND CONDITIONS
|
| 179 |
+
|
| 180 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 181 |
+
|
| 182 |
+
To apply the Apache License to your work, attach the following
|
| 183 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 184 |
+
replaced with your own identifying information. (Don't include
|
| 185 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 186 |
+
comment syntax for the file format. We also recommend that a
|
| 187 |
+
file or class name and description of purpose be included on the
|
| 188 |
+
same "printed page" as the copyright notice for easier
|
| 189 |
+
identification within third-party archives.
|
| 190 |
+
|
| 191 |
+
Copyright 2023 VLMEvalKit Authors.
|
| 192 |
+
|
| 193 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 194 |
+
you may not use this file except in compliance with the License.
|
| 195 |
+
You may obtain a copy of the License at
|
| 196 |
+
|
| 197 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 198 |
+
|
| 199 |
+
Unless required by applicable law or agreed to in writing, software
|
| 200 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 201 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 202 |
+
See the License for the specific language governing permissions and
|
| 203 |
+
limitations under the License.
|
README.md
ADDED
|
@@ -0,0 +1,149 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
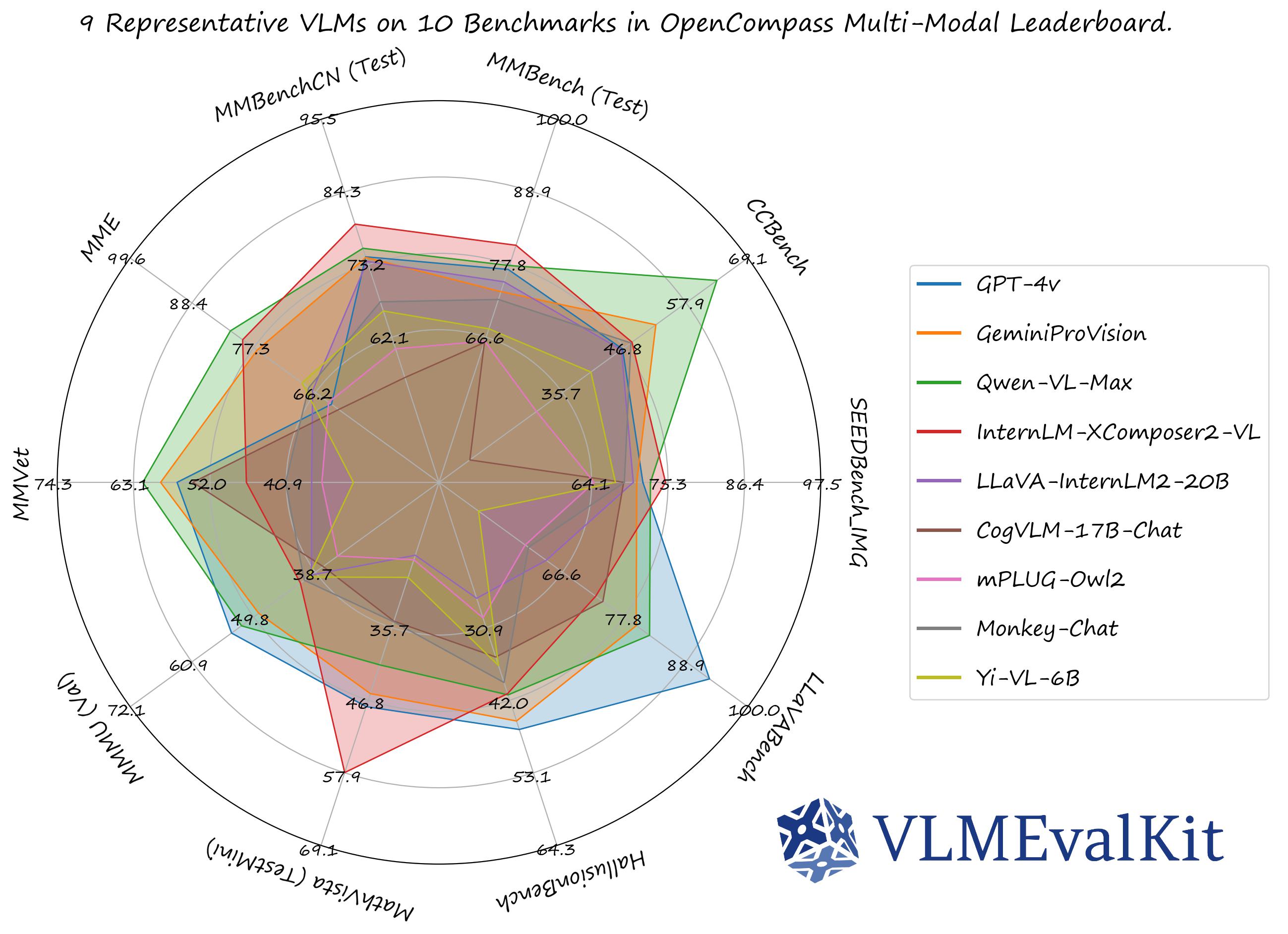
|
| 2 |
+
|
| 3 |
+
<b>A Toolkit for Evaluating Large Vision-Language Models. </b>
|
| 4 |
+
|
| 5 |
+
[![][github-contributors-shield]][github-contributors-link] • [![][github-forks-shield]][github-forks-link] • [![][github-stars-shield]][github-stars-link] • [![][github-issues-shield]][github-issues-link] • [![][github-license-shield]][github-license-link]
|
| 6 |
+
|
| 7 |
+
English | [简体中文](/docs/zh-CN/README_zh-CN.md) | [日本語](/docs/ja/README_ja.md)
|
| 8 |
+
|
| 9 |
+
<a href="https://rank.opencompass.org.cn/leaderboard-multimodal">🏆 OC Learderboard </a> •
|
| 10 |
+
<a href="#%EF%B8%8F-quickstart">🏗️Quickstart </a> •
|
| 11 |
+
<a href="#-datasets-models-and-evaluation-results">📊Datasets & Models </a> •
|
| 12 |
+
<a href="#%EF%B8%8F-development-guide">🛠️Development </a>
|
| 13 |
+
|
| 14 |
+
<a href="https://huggingface.co/spaces/opencompass/open_vlm_leaderboard">🤗 HF Leaderboard</a> •
|
| 15 |
+
<a href="https://huggingface.co/datasets/VLMEval/OpenVLMRecords">🤗 Evaluation Records</a> •
|
| 16 |
+
<a href="https://huggingface.co/spaces/opencompass/openvlm_video_leaderboard">🤗 HF Video Leaderboard</a> •
|
| 17 |
+
|
| 18 |
+
<a href="https://discord.gg/evDT4GZmxN">🔊 Discord</a> •
|
| 19 |
+
<a href="https://www.arxiv.org/abs/2407.11691">📝 Report</a> •
|
| 20 |
+
<a href="#-the-goal-of-vlmevalkit">🎯Goal </a> •
|
| 21 |
+
<a href="#%EF%B8%8F-citation">🖊️Citation </a>
|
| 22 |
+
</div>
|
| 23 |
+
|
| 24 |
+
**VLMEvalKit** (the python package name is **vlmeval**) is an **open-source evaluation toolkit** of **large vision-language models (LVLMs)**. It enables **one-command evaluation** of LVLMs on various benchmarks, without the heavy workload of data preparation under multiple repositories. In VLMEvalKit, we adopt **generation-based evaluation** for all LVLMs, and provide the evaluation results obtained with both **exact matching** and **LLM-based answer extraction**.
|
| 25 |
+
|
| 26 |
+
## 🆕 News
|
| 27 |
+
|
| 28 |
+
> We have presented a [**comprehensive survey**](https://arxiv.org/pdf/2411.15296) on the evaluation of large multi-modality models, jointly with [**MME Team**](https://github.com/BradyFU/Awesome-Multimodal-Large-Language-Models) and [**LMMs-Lab**](https://lmms-lab.github.io) 🔥🔥🔥
|
| 29 |
+
- **[2025-02-20]** Supported Models: **InternVL2.5 series, QwenVL2.5 series, QVQ-72B, Doubao-VL, Janus-Pro-7B, MiniCPM-o-2.6, InternVL2-MPO, LLaVA-CoT, Hunyuan-Standard-Vision, Ovis2, Valley, SAIL-VL, Ross, Long-VITA, EMU3, SmolVLM**. Supported Benchmarks: **MMMU-Pro, WeMath, 3DSRBench, LogicVista, VL-RewardBench, CC-OCR, CG-Bench, CMMMU, WorldSense**. Please refer to [**VLMEvalKit Features**](https://aicarrier.feishu.cn/wiki/Qp7wwSzQ9iK1Y6kNUJVcr6zTnPe?table=tblsdEpLieDoCxtb) for more details. Thanks to all contributors 🔥🔥🔥
|
| 30 |
+
- **[2024-12-11]** Supported [**NaturalBench**](https://huggingface.co/datasets/BaiqiL/NaturalBench), a vision-centric VQA benchmark (NeurIPS'24) that challenges vision-language models with simple questions about natural imagery.
|
| 31 |
+
- **[2024-12-02]** Supported [**VisOnlyQA**](https://github.com/psunlpgroup/VisOnlyQA/), a benchmark for evaluating the visual perception capabilities 🔥🔥🔥
|
| 32 |
+
- **[2024-11-26]** Supported [**Ovis1.6-Gemma2-27B**](https://huggingface.co/AIDC-AI/Ovis1.6-Gemma2-27B), thanks to [**runninglsy**](https://github.com/runninglsy) 🔥🔥🔥
|
| 33 |
+
- **[2024-11-25]** Create a new flag `VLMEVALKIT_USE_MODELSCOPE`. By setting this environment variable, you can download the video benchmarks supported from [**modelscope**](https://www.modelscope.cn) 🔥🔥🔥
|
| 34 |
+
- **[2024-11-25]** Supported [**VizWiz**](https://vizwiz.org/tasks/vqa/) benchmark 🔥🔥🔥
|
| 35 |
+
- **[2024-11-22]** Supported the inference of [**MMGenBench**](https://mmgenbench.alsoai.com), thanks [**lerogo**](https://github.com/lerogo) 🔥🔥🔥
|
| 36 |
+
- **[2024-11-22]** Supported [**Dynamath**](https://huggingface.co/datasets/DynaMath/DynaMath_Sample), a multimodal math benchmark comprising of 501 SEED problems and 10 variants generated based on random seeds. The benchmark can be used to measure the robustness of MLLMs in multi-modal math solving 🔥🔥🔥
|
| 37 |
+
- **[2024-11-21]** Integrated a new config system to enable more flexible evaluation settings. Check the [Document](/docs/en/ConfigSystem.md) or run `python run.py --help` for more details 🔥🔥🔥
|
| 38 |
+
- **[2024-11-21]** Supported [**QSpatial**](https://andrewliao11.github.io/spatial_prompt/), a multimodal benchmark for Quantitative Spatial Reasoning (determine the size / distance, e.g.), thanks [**andrewliao11**](https://github.com/andrewliao11) for providing the official support 🔥🔥🔥
|
| 39 |
+
- **[2024-11-21]** Supported [**MM-Math**](https://github.com/kge-sun/mm-math), a new multimodal math benchmark comprising of ~6K middle school multi-modal reasoning math problems. GPT-4o-20240806 achieces 22.5% accuracy on this benchmark 🔥🔥🔥
|
| 40 |
+
|
| 41 |
+
## 🏗️ QuickStart
|
| 42 |
+
|
| 43 |
+
See [[QuickStart](/docs/en/Quickstart.md) | [快速开始](/docs/zh-CN/Quickstart.md)] for a quick start guide.
|
| 44 |
+
|
| 45 |
+
## 📊 Datasets, Models, and Evaluation Results
|
| 46 |
+
|
| 47 |
+
### Evaluation Results
|
| 48 |
+
|
| 49 |
+
**The performance numbers on our official multi-modal leaderboards can be downloaded from here!**
|
| 50 |
+
|
| 51 |
+
[**OpenVLM Leaderboard**](https://huggingface.co/spaces/opencompass/open_vlm_leaderboard): [**Download All DETAILED Results**](http://opencompass.openxlab.space/assets/OpenVLM.json).
|
| 52 |
+
|
| 53 |
+
Check **Supported Benchmarks** Tab in [**VLMEvalKit Features**](https://aicarrier.feishu.cn/wiki/Qp7wwSzQ9iK1Y6kNUJVcr6zTnPe?table=tblsdEpLieDoCxtb) to view all supported image & video benchmarks (70+).
|
| 54 |
+
|
| 55 |
+
Check **Supported LMMs** Tab in [**VLMEvalKit Features**](https://aicarrier.feishu.cn/wiki/Qp7wwSzQ9iK1Y6kNUJVcr6zTnPe?table=tblsdEpLieDoCxtb) to view all supported LMMs, including commercial APIs, open-source models, and more (200+).
|
| 56 |
+
|
| 57 |
+
**Transformers Version Recommendation:**
|
| 58 |
+
|
| 59 |
+
Note that some VLMs may not be able to run under certain transformer versions, we recommend the following settings to evaluate each VLM:
|
| 60 |
+
|
| 61 |
+
- **Please use** `transformers==4.33.0` **for**: `Qwen series`, `Monkey series`, `InternLM-XComposer Series`, `mPLUG-Owl2`, `OpenFlamingo v2`, `IDEFICS series`, `VisualGLM`, `MMAlaya`, `ShareCaptioner`, `MiniGPT-4 series`, `InstructBLIP series`, `PandaGPT`, `VXVERSE`.
|
| 62 |
+
- **Please use** `transformers==4.36.2` **for**: `Moondream1`.
|
| 63 |
+
- **Please use** `transformers==4.37.0` **for**: `LLaVA series`, `ShareGPT4V series`, `TransCore-M`, `LLaVA (XTuner)`, `CogVLM Series`, `EMU2 Series`, `Yi-VL Series`, `MiniCPM-[V1/V2]`, `OmniLMM-12B`, `DeepSeek-VL series`, `InternVL series`, `Cambrian Series`, `VILA Series`, `Llama-3-MixSenseV1_1`, `Parrot-7B`, `PLLaVA Series`.
|
| 64 |
+
- **Please use** `transformers==4.40.0` **for**: `IDEFICS2`, `Bunny-Llama3`, `MiniCPM-Llama3-V2.5`, `360VL-70B`, `Phi-3-Vision`, `WeMM`.
|
| 65 |
+
- **Please use** `transformers==4.42.0` **for**: `AKI`.
|
| 66 |
+
- **Please use** `transformers==4.44.0` **for**: `Moondream2`, `H2OVL series`.
|
| 67 |
+
- **Please use** `transformers==4.45.0` **for**: `Aria`.
|
| 68 |
+
- **Please use** `transformers==latest` **for**: `LLaVA-Next series`, `PaliGemma-3B`, `Chameleon series`, `Video-LLaVA-7B-HF`, `Ovis series`, `Mantis series`, `MiniCPM-V2.6`, `OmChat-v2.0-13B-sinlge-beta`, `Idefics-3`, `GLM-4v-9B`, `VideoChat2-HD`, `RBDash_72b`, `Llama-3.2 series`, `Kosmos series`.
|
| 69 |
+
|
| 70 |
+
**Torchvision Version Recommendation:**
|
| 71 |
+
|
| 72 |
+
Note that some VLMs may not be able to run under certain torchvision versions, we recommend the following settings to evaluate each VLM:
|
| 73 |
+
|
| 74 |
+
- **Please use** `torchvision>=0.16` **for**: `Moondream series` and `Aria`
|
| 75 |
+
|
| 76 |
+
**Flash-attn Version Recommendation:**
|
| 77 |
+
|
| 78 |
+
Note that some VLMs may not be able to run under certain flash-attention versions, we recommend the following settings to evaluate each VLM:
|
| 79 |
+
|
| 80 |
+
- **Please use** `pip install flash-attn --no-build-isolation` **for**: `Aria`
|
| 81 |
+
|
| 82 |
+
```python
|
| 83 |
+
# Demo
|
| 84 |
+
from vlmeval.config import supported_VLM
|
| 85 |
+
model = supported_VLM['idefics_9b_instruct']()
|
| 86 |
+
# Forward Single Image
|
| 87 |
+
ret = model.generate(['assets/apple.jpg', 'What is in this image?'])
|
| 88 |
+
print(ret) # The image features a red apple with a leaf on it.
|
| 89 |
+
# Forward Multiple Images
|
| 90 |
+
ret = model.generate(['assets/apple.jpg', 'assets/apple.jpg', 'How many apples are there in the provided images? '])
|
| 91 |
+
print(ret) # There are two apples in the provided images.
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
## 🛠️ Development Guide
|
| 95 |
+
|
| 96 |
+
To develop custom benchmarks, VLMs, or simply contribute other codes to **VLMEvalKit**, please refer to [[Development_Guide](/docs/en/Development.md) | [开发指南](/docs/zh-CN/Development.md)].
|
| 97 |
+
|
| 98 |
+
**Call for contributions**
|
| 99 |
+
|
| 100 |
+
To promote the contribution from the community and share the corresponding credit (in the next report update):
|
| 101 |
+
|
| 102 |
+
- All Contributions will be acknowledged in the report.
|
| 103 |
+
- Contributors with 3 or more major contributions (implementing an MLLM, benchmark, or major feature) can join the author list of [VLMEvalKit Technical Report](https://www.arxiv.org/abs/2407.11691) on ArXiv. Eligible contributors can create an issue or dm kennyutc in [VLMEvalKit Discord Channel](https://discord.com/invite/evDT4GZmxN).
|
| 104 |
+
|
| 105 |
+
Here is a [contributor list](/docs/en/Contributors.md) we curated based on the records.
|
| 106 |
+
|
| 107 |
+
## 🎯 The Goal of VLMEvalKit
|
| 108 |
+
|
| 109 |
+
**The codebase is designed to:**
|
| 110 |
+
|
| 111 |
+
1. Provide an **easy-to-use**, **opensource evaluation toolkit** to make it convenient for researchers & developers to evaluate existing LVLMs and make evaluation results **easy to reproduce**.
|
| 112 |
+
2. Make it easy for VLM developers to evaluate their own models. To evaluate the VLM on multiple supported benchmarks, one just need to **implement a single `generate_inner()` function**, all other workloads (data downloading, data preprocessing, prediction inference, metric calculation) are handled by the codebase.
|
| 113 |
+
|
| 114 |
+
**The codebase is not designed to:**
|
| 115 |
+
|
| 116 |
+
1. Reproduce the exact accuracy number reported in the original papers of all **3rd party benchmarks**. The reason can be two-fold:
|
| 117 |
+
1. VLMEvalKit uses **generation-based evaluation** for all VLMs (and optionally with **LLM-based answer extraction**). Meanwhile, some benchmarks may use different approaches (SEEDBench uses PPL-based evaluation, *eg.*). For those benchmarks, we compare both scores in the corresponding result. We encourage developers to support other evaluation paradigms in the codebase.
|
| 118 |
+
2. By default, we use the same prompt template for all VLMs to evaluate on a benchmark. Meanwhile, **some VLMs may have their specific prompt templates** (some may not covered by the codebase at this time). We encourage VLM developers to implement their own prompt template in VLMEvalKit, if that is not covered currently. That will help to improve the reproducibility.
|
| 119 |
+
|
| 120 |
+
## 🖊️ Citation
|
| 121 |
+
|
| 122 |
+
If you find this work helpful, please consider to **star🌟** this repo. Thanks for your support!
|
| 123 |
+
|
| 124 |
+
[](https://github.com/open-compass/VLMEvalKit/stargazers)
|
| 125 |
+
|
| 126 |
+
If you use VLMEvalKit in your research or wish to refer to published OpenSource evaluation results, please use the following BibTeX entry and the BibTex entry corresponding to the specific VLM / benchmark you used.
|
| 127 |
+
|
| 128 |
+
```bib
|
| 129 |
+
@inproceedings{duan2024vlmevalkit,
|
| 130 |
+
title={Vlmevalkit: An open-source toolkit for evaluating large multi-modality models},
|
| 131 |
+
author={Duan, Haodong and Yang, Junming and Qiao, Yuxuan and Fang, Xinyu and Chen, Lin and Liu, Yuan and Dong, Xiaoyi and Zang, Yuhang and Zhang, Pan and Wang, Jiaqi and others},
|
| 132 |
+
booktitle={Proceedings of the 32nd ACM International Conference on Multimedia},
|
| 133 |
+
pages={11198--11201},
|
| 134 |
+
year={2024}
|
| 135 |
+
}
|
| 136 |
+
```
|
| 137 |
+
|
| 138 |
+
<p align="right"><a href="#top">🔝Back to top</a></p>
|
| 139 |
+
|
| 140 |
+
[github-contributors-link]: https://github.com/open-compass/VLMEvalKit/graphs/contributors
|
| 141 |
+
[github-contributors-shield]: https://img.shields.io/github/contributors/open-compass/VLMEvalKit?color=c4f042&labelColor=black&style=flat-square
|
| 142 |
+
[github-forks-link]: https://github.com/open-compass/VLMEvalKit/network/members
|
| 143 |
+
[github-forks-shield]: https://img.shields.io/github/forks/open-compass/VLMEvalKit?color=8ae8ff&labelColor=black&style=flat-square
|
| 144 |
+
[github-issues-link]: https://github.com/open-compass/VLMEvalKit/issues
|
| 145 |
+
[github-issues-shield]: https://img.shields.io/github/issues/open-compass/VLMEvalKit?color=ff80eb&labelColor=black&style=flat-square
|
| 146 |
+
[github-license-link]: https://github.com/open-compass/VLMEvalKit/blob/main/LICENSE
|
| 147 |
+
[github-license-shield]: https://img.shields.io/github/license/open-compass/VLMEvalKit?color=white&labelColor=black&style=flat-square
|
| 148 |
+
[github-stars-link]: https://github.com/open-compass/VLMEvalKit/stargazers
|
| 149 |
+
[github-stars-shield]: https://img.shields.io/github/stars/open-compass/VLMEvalKit?color=ffcb47&labelColor=black&style=flat-square
|
assets/LOGO.svg
ADDED
|
|
do_eval.py
ADDED
|
@@ -0,0 +1,144 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
from datetime import datetime
|
| 5 |
+
import subprocess
|
| 6 |
+
|
| 7 |
+
# the emprical settings for each dataset
|
| 8 |
+
full_datasets = {
|
| 9 |
+
"MathVista_MINI": "train_prompt_sampling",
|
| 10 |
+
"MathVision": "train_prompt_greedy",
|
| 11 |
+
"MathVerse_MINI": "train_prompt_greedy",
|
| 12 |
+
"MMMU_DEV_VAL": "origin_prompt_greedy",
|
| 13 |
+
"MMStar": "train_prompt_greedy",
|
| 14 |
+
"DynaMath": "train_prompt_greedy",
|
| 15 |
+
"WeMath": "train_prompt_greedy",
|
| 16 |
+
"TextVQA_VAL": "origin_prompt_greedy",
|
| 17 |
+
"DocVQA_TEST": "origin_prompt_greedy",
|
| 18 |
+
"MMVet": "origin_prompt_greedy",
|
| 19 |
+
}
|
| 20 |
+
|
| 21 |
+
settings = {
|
| 22 |
+
"train_prompt_sampling": {
|
| 23 |
+
"use_reasoning_prompt": 2,
|
| 24 |
+
"do_sample": True,
|
| 25 |
+
"top_p": 1,
|
| 26 |
+
"top_k": -1,
|
| 27 |
+
"temperature": 1,
|
| 28 |
+
},
|
| 29 |
+
"train_prompt_greedy": {
|
| 30 |
+
"use_reasoning_prompt": 2,
|
| 31 |
+
"do_sample": True,
|
| 32 |
+
"top_p": 0.001,
|
| 33 |
+
"top_k": 1,
|
| 34 |
+
"temperature": 0.01,
|
| 35 |
+
},
|
| 36 |
+
"origin_prompt_greedy": {
|
| 37 |
+
"use_reasoning_prompt": 0,
|
| 38 |
+
"do_sample": True,
|
| 39 |
+
"top_p": 0.001,
|
| 40 |
+
"top_k": 1,
|
| 41 |
+
"temperature": 0.01,
|
| 42 |
+
},
|
| 43 |
+
}
|
| 44 |
+
|
| 45 |
+
|
| 46 |
+
def main():
|
| 47 |
+
parser = argparse.ArgumentParser()
|
| 48 |
+
|
| 49 |
+
parser.add_argument("--run_name", type=str, required=True, help="Name of the run")
|
| 50 |
+
parser.add_argument("--gpus", type=int, default=8, help="Number of GPUs to use")
|
| 51 |
+
parser.add_argument("--path", type=str, required=True, help="Path to the model")
|
| 52 |
+
parser.add_argument(
|
| 53 |
+
"--dataset", type=str, nargs="+", required=True, help="List of datasets to use"
|
| 54 |
+
)
|
| 55 |
+
|
| 56 |
+
parser.add_argument(
|
| 57 |
+
"--min_pixels", type=int, default=3136, help="Minimum number of pixels"
|
| 58 |
+
)
|
| 59 |
+
parser.add_argument(
|
| 60 |
+
"--max_pixels", type=int, default=12845056, help="Maximum number of pixels"
|
| 61 |
+
)
|
| 62 |
+
parser.add_argument(
|
| 63 |
+
"--max_new_tokens", type=int, default=2048, help="Maximum number of new tokens"
|
| 64 |
+
)
|
| 65 |
+
|
| 66 |
+
args = parser.parse_args()
|
| 67 |
+
assert len(args.dataset), "--dataset should be a list of datasets"
|
| 68 |
+
|
| 69 |
+
datasets = args.dataset
|
| 70 |
+
if len(args.dataset) == 1 and args.dataset[0] == "full":
|
| 71 |
+
datasets = list(full_datasets.keys())
|
| 72 |
+
|
| 73 |
+
for dataset in datasets:
|
| 74 |
+
assert (
|
| 75 |
+
dataset in full_datasets
|
| 76 |
+
), f"Dataset {dataset} is not in the list of available datasets: {list(full_datasets.keys())}"
|
| 77 |
+
|
| 78 |
+
print("Datasets to be used:", datasets)
|
| 79 |
+
print("Run name:", args.run_name)
|
| 80 |
+
print("Number of GPUs:", args.gpus)
|
| 81 |
+
print("Model path:", args.path)
|
| 82 |
+
|
| 83 |
+
for dataset in datasets:
|
| 84 |
+
config = {
|
| 85 |
+
"model": {
|
| 86 |
+
args.run_name: {
|
| 87 |
+
"class": "Qwen2VLChat",
|
| 88 |
+
"model_path": args.path,
|
| 89 |
+
"min_pixels": args.min_pixels,
|
| 90 |
+
"max_pixels": args.max_pixels,
|
| 91 |
+
"use_vllm": True,
|
| 92 |
+
"max_new_tokens": args.max_new_tokens,
|
| 93 |
+
**settings[full_datasets[dataset]],
|
| 94 |
+
},
|
| 95 |
+
},
|
| 96 |
+
"datasets": datasets,
|
| 97 |
+
}
|
| 98 |
+
|
| 99 |
+
current_datetime = datetime.now().strftime("%Y%m%d")
|
| 100 |
+
save_dir = f"public_eval/{args.run_name}/{dataset}/{current_datetime}"
|
| 101 |
+
os.makedirs(save_dir, exist_ok=True)
|
| 102 |
+
|
| 103 |
+
config_name = f"config.json"
|
| 104 |
+
config_path = os.path.join(save_dir, config_name)
|
| 105 |
+
with open(config_path, "w") as json_file:
|
| 106 |
+
json.dump(config, json_file, indent=4)
|
| 107 |
+
|
| 108 |
+
print(f"Start evaluating on {dataset}.")
|
| 109 |
+
print(f"Eval config {full_datasets[dataset]}")
|
| 110 |
+
|
| 111 |
+
env_vars = os.environ.copy()
|
| 112 |
+
env_vars["VLLM_USE_V1"] = "0"
|
| 113 |
+
|
| 114 |
+
command = [
|
| 115 |
+
"torchrun",
|
| 116 |
+
f"--nproc_per_node={args.gpus}",
|
| 117 |
+
"run_for_bash.py",
|
| 118 |
+
"--config",
|
| 119 |
+
f"{config_path}",
|
| 120 |
+
"--data",
|
| 121 |
+
f"{dataset}",
|
| 122 |
+
"--verbose",
|
| 123 |
+
"--work-dir",
|
| 124 |
+
f"{save_dir}",
|
| 125 |
+
]
|
| 126 |
+
|
| 127 |
+
stdout_file = os.path.join(save_dir, f"{dataset}_stdout.log")
|
| 128 |
+
stderr_file = os.path.join(save_dir, f"{dataset}_stderr.log")
|
| 129 |
+
|
| 130 |
+
with open(stdout_file, "w") as stdout, open(stderr_file, "w") as stderr:
|
| 131 |
+
try:
|
| 132 |
+
print(f"Output redirected to {stdout_file}")
|
| 133 |
+
print(f"Errors redirected to {stderr_file}")
|
| 134 |
+
subprocess.run(
|
| 135 |
+
command, env=env_vars, check=True, stdout=stdout, stderr=stderr
|
| 136 |
+
)
|
| 137 |
+
# os.symlink(source, link_name)
|
| 138 |
+
|
| 139 |
+
except subprocess.CalledProcessError as e:
|
| 140 |
+
print(f"torchrun failed. Check {stderr_file} for error details.")
|
| 141 |
+
|
| 142 |
+
|
| 143 |
+
if __name__ == "__main__":
|
| 144 |
+
main()
|
do_eval.sh
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
cd /user/konglingyu
|
| 2 |
+
source venv/tabfact/bin/activate
|
| 3 |
+
cd VLMEvalKit
|
| 4 |
+
|
| 5 |
+
CUDA_VISIBLE_DEVICES=0 python do_eval_temp.py --run_name NEW_naive_grpo_step_400 --gpus 8 --path /user/xuqixin/checkpoints/qwen25_vl-7b/grpo_v7_exp8_qwen25vl_grpo_opensource_math_doc_vanilla_grpo/global_step_400/actor/huggingface --dataset EMMA-mini &
|
| 6 |
+
|
| 7 |
+
CUDA_VISIBLE_DEVICES=1 python do_eval_temp.py --run_name NEW_grpo_v7_exp0_qwen25vl_grpo_opensource_math_onlinefilter_regen --gpus 8 --path /user/xuqixin/checkpoints/qwen25_vl-7b/grpo_v7_exp0_qwen25vl_grpo_opensource_math_onlinefilter_regen/global_step_300/actor/huggingface --dataset EMMA-mini &
|
| 8 |
+
|
| 9 |
+
CUDA_VISIBLE_DEVICES=2 python do_eval_temp.py --run_name NEW_dr_grpo_step_800 --gpus 8 --path /user/xuqixin/checkpoints/qwen25_vl-7b/grpo_v7_exp9_qwen25vl_grpo_opensource_math_doc_dr_grpo/global_step_800/actor/huggingface --dataset EMMA-mini &
|
| 10 |
+
|
| 11 |
+
CUDA_VISIBLE_DEVICES=3 python do_eval_temp.py --run_name NEW_dr_grpo_step_600 --gpus 8 --path /user/xuqixin/checkpoints/qwen25_vl-7b/grpo_v7_exp9_qwen25vl_grpo_opensource_math_doc_dr_grpo/global_step_600/actor/huggingface --dataset EMMA-mini &
|
| 12 |
+
|
| 13 |
+
CUDA_VISIBLE_DEVICES=4 python do_eval_temp.py --run_name NEW_bbox_step_300 --gpus 8 --path /user/xuqixin/checkpoints/qwen25_vl-7b/grpo_v7_exp10_qwen25_vl_sft_bbox_grpo_opensource_doc/global_step_300/actor/huggingface --dataset EMMA-mini &
|
| 14 |
+
|
| 15 |
+
CUDA_VISIBLE_DEVICES=5 python do_eval_temp.py --run_name NEW_clip_high_step_500 --gpus 8 --path /user/xuqixin/checkpoints/qwen25_vl-7b/grpo_v6_exp7_qwen25vl_grpo_opensource_doc_clip_high_028/global_step_500/actor/huggingface --dataset EMMA-mini &
|
| 16 |
+
|
| 17 |
+
CUDA_VISIBLE_DEVICES=6 python do_eval_temp.py --run_name NEW_clip_high_step_600 --gpus 8 --path /user/xuqixin/checkpoints/qwen25_vl-7b/grpo_v6_exp7_qwen25vl_grpo_opensource_doc_clip_high_028/global_step_600/actor/huggingface --dataset EMMA-mini &
|
do_eval_emma.py
ADDED
|
@@ -0,0 +1,222 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
from datetime import datetime
|
| 5 |
+
import subprocess
|
| 6 |
+
import logging
|
| 7 |
+
|
| 8 |
+
full_datasets = {
|
| 9 |
+
"MathVista_MINI": ["train_prompt_sampling"],
|
| 10 |
+
"MathVision": ["train_prompt_greedy"],
|
| 11 |
+
"MathVerse_MINI": ["train_prompt_greedy"],
|
| 12 |
+
"MMMU_DEV_VAL": ["origin_prompt_greedy"],
|
| 13 |
+
"MMStar": ["train_prompt_greedy"],
|
| 14 |
+
"DynaMath": ["train_prompt_greedy"],
|
| 15 |
+
"WeMath": ["train_prompt_greedy"],
|
| 16 |
+
"TextVQA_VAL": ["origin_prompt_greedy"],
|
| 17 |
+
"MMVet": ["origin_prompt_greedy"],
|
| 18 |
+
"MMDocBench": ["origin_prompt_greedy"],
|
| 19 |
+
"AI2D_TEST": ["origin_prompt_greedy"],
|
| 20 |
+
"HallusionBench": ["origin_prompt_greedy"],
|
| 21 |
+
"MMBench_DEV_EN_V11": ["origin_prompt_greedy"],
|
| 22 |
+
"OCRBench": ["origin_prompt_greedy"],
|
| 23 |
+
"DocVQA_VAL": ["origin_prompt_greedy"],
|
| 24 |
+
# "EMMA-mini": ["train_prompt_sampling"],
|
| 25 |
+
"EMMA": ["train_prompt_sampling"],
|
| 26 |
+
# "DocVQA_TEST": ["origin_prompt_greedy"],
|
| 27 |
+
# "MMBench_TEST_EN_V11": ["origin_prompt_greedy"],
|
| 28 |
+
}
|
| 29 |
+
|
| 30 |
+
settings = {
|
| 31 |
+
"train_prompt_sampling": {
|
| 32 |
+
"use_reasoning_prompt": 2,
|
| 33 |
+
"do_sample": True,
|
| 34 |
+
"top_p": 1,
|
| 35 |
+
"top_k": -1,
|
| 36 |
+
"temperature": 1,
|
| 37 |
+
},
|
| 38 |
+
"train_prompt_greedy": {
|
| 39 |
+
"use_reasoning_prompt": 2,
|
| 40 |
+
"do_sample": True,
|
| 41 |
+
"top_p": 0.001,
|
| 42 |
+
"top_k": 1,
|
| 43 |
+
"temperature": 0.01,
|
| 44 |
+
},
|
| 45 |
+
"origin_prompt_greedy": {
|
| 46 |
+
"use_reasoning_prompt": 0,
|
| 47 |
+
"do_sample": True,
|
| 48 |
+
"top_p": 0.001,
|
| 49 |
+
"top_k": 1,
|
| 50 |
+
"temperature": 0.01,
|
| 51 |
+
},
|
| 52 |
+
}
|
| 53 |
+
|
| 54 |
+
|
| 55 |
+
def main():
|
| 56 |
+
parser = argparse.ArgumentParser()
|
| 57 |
+
|
| 58 |
+
parser.add_argument("--run_name", type=str, required=True, help="Name of the run")
|
| 59 |
+
parser.add_argument("--gpus", type=int, default=8, help="Number of GPUs to use")
|
| 60 |
+
parser.add_argument("--path", type=str, required=True, help="Path to the model")
|
| 61 |
+
parser.add_argument(
|
| 62 |
+
"--dataset", type=str, nargs="+", required=True, help="List of datasets to use"
|
| 63 |
+
)
|
| 64 |
+
|
| 65 |
+
parser.add_argument(
|
| 66 |
+
"--min_pixels", type=int, default=3136, help="Minimum number of pixels"
|
| 67 |
+
)
|
| 68 |
+
parser.add_argument(
|
| 69 |
+
"--max_pixels", type=int, default=12845056, help="Maximum number of pixels"
|
| 70 |
+
)
|
| 71 |
+
parser.add_argument(
|
| 72 |
+
"--max_new_tokens", type=int, default=2048, help="Maximum number of new tokens"
|
| 73 |
+
)
|
| 74 |
+
|
| 75 |
+
args = parser.parse_args()
|
| 76 |
+
assert len(args.dataset), "--dataset should be a list of datasets"
|
| 77 |
+
|
| 78 |
+
datasets = args.dataset
|
| 79 |
+
if len(args.dataset) == 1 and args.dataset[0] == "full":
|
| 80 |
+
datasets = list(full_datasets.keys())
|
| 81 |
+
|
| 82 |
+
for dataset in datasets:
|
| 83 |
+
assert (
|
| 84 |
+
dataset in full_datasets
|
| 85 |
+
), f"Dataset {dataset} is not in the list of available datasets: {list(full_datasets.keys())}"
|
| 86 |
+
|
| 87 |
+
print("Datasets to be used:", datasets)
|
| 88 |
+
print("Run name:", args.run_name)
|
| 89 |
+
print("Number of GPUs:", args.gpus)
|
| 90 |
+
print("Model path:", args.path)
|
| 91 |
+
print("Minimum pixels:", args.min_pixels)
|
| 92 |
+
print("Maximum pixels:", args.max_pixels)
|
| 93 |
+
print("Maximum new tokens:", args.max_new_tokens, flush=True)
|
| 94 |
+
|
| 95 |
+
for dataset in datasets:
|
| 96 |
+
assert isinstance(full_datasets[dataset], list)
|
| 97 |
+
for setting in full_datasets[dataset]:
|
| 98 |
+
config = {
|
| 99 |
+
"model": {
|
| 100 |
+
args.run_name: {
|
| 101 |
+
"class": "Qwen2VLChat",
|
| 102 |
+
"model_path": args.path,
|
| 103 |
+
"min_pixels": args.min_pixels,
|
| 104 |
+
"max_pixels": args.max_pixels,
|
| 105 |
+
"use_vllm": True,
|
| 106 |
+
"max_new_tokens": args.max_new_tokens,
|
| 107 |
+
**settings[setting],
|
| 108 |
+
},
|
| 109 |
+
},
|
| 110 |
+
"datasets": datasets,
|
| 111 |
+
}
|
| 112 |
+
|
| 113 |
+
current_datetime = datetime.now().strftime("%Y%m%d")
|
| 114 |
+
save_dir = f"public_eval/{args.run_name}/{dataset}_{setting}/{current_datetime}"
|
| 115 |
+
os.makedirs(save_dir, exist_ok=True)
|
| 116 |
+
|
| 117 |
+
config_name = f"config.json"
|
| 118 |
+
config_path = os.path.join(save_dir, config_name)
|
| 119 |
+
with open(config_path, "w") as json_file:
|
| 120 |
+
json.dump(config, json_file, indent=4)
|
| 121 |
+
|
| 122 |
+
print(f"Start evaluating on {dataset}.")
|
| 123 |
+
print(f"Eval config {setting}", flush=True)
|
| 124 |
+
|
| 125 |
+
env_vars = os.environ.copy()
|
| 126 |
+
env_vars["VLLM_USE_V1"] = "0"
|
| 127 |
+
|
| 128 |
+
if dataset == "EMMA" or dataset == "EMMA-mini":
|
| 129 |
+
command = [
|
| 130 |
+
"torchrun",
|
| 131 |
+
f"--nproc_per_node={args.gpus}",
|
| 132 |
+
"EMMA/generate_response.py",
|
| 133 |
+
"--dataset_name",
|
| 134 |
+
f"/root/LMUData/{dataset}",
|
| 135 |
+
"--model_path",
|
| 136 |
+
f"{args.path}",
|
| 137 |
+
"--output_path",
|
| 138 |
+
f"{save_dir}/results.json",
|
| 139 |
+
"--config_path",
|
| 140 |
+
"/user/konglingyu/VLMEvalKit/EMMA/configs/gpt.yaml",
|
| 141 |
+
"--strategy",
|
| 142 |
+
"CoT"
|
| 143 |
+
]
|
| 144 |
+
|
| 145 |
+
stdout_file = os.path.join(save_dir, f"out.log")
|
| 146 |
+
stderr_file = os.path.join(save_dir, f"err.log")
|
| 147 |
+
|
| 148 |
+
with open(stdout_file, "w") as stdout, open(stderr_file, "w") as stderr:
|
| 149 |
+
try:
|
| 150 |
+
print(f"Output redirected to {stdout_file}")
|
| 151 |
+
print(f"Errors redirected to {stderr_file}", flush=True)
|
| 152 |
+
|
| 153 |
+
process = subprocess.Popen(
|
| 154 |
+
command, env=env_vars, stdout=stdout, stderr=subprocess.PIPE, text=True
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
for line in process.stderr:
|
| 158 |
+
print(line, end="") # 输出到屏幕
|
| 159 |
+
stderr.write(line) # 写入文件
|
| 160 |
+
|
| 161 |
+
# 等待命令完成
|
| 162 |
+
process.wait()
|
| 163 |
+
|
| 164 |
+
if process.returncode != 0:
|
| 165 |
+
print(f"Command failed with return code {process.returncode}. Check {stderr_file} for error details.", flush=True)
|
| 166 |
+
continue
|
| 167 |
+
|
| 168 |
+
data = {}
|
| 169 |
+
for i in range(args.gpus):
|
| 170 |
+
assert os.path.exists(f"{save_dir}/results_{i}.json")
|
| 171 |
+
data.update(json.load(open(f"{save_dir}/results_{i}.json", "r")))
|
| 172 |
+
with open(f"{save_dir}/results.json", "w") as f:
|
| 173 |
+
json.dump(data, f, indent=4)
|
| 174 |
+
from EMMA.evaluation.evaluate import gen_true_false
|
| 175 |
+
from EMMA.evaluation.calculate_acc import gen_score
|
| 176 |
+
gen_true_false(f"{save_dir}/results.json")
|
| 177 |
+
gen_score(f"{save_dir}/results.json", f"{save_dir}/results_acc.json")
|
| 178 |
+
except Exception as e:
|
| 179 |
+
print(f"torchrun failed. Check {stderr_file} for error details.", flush=True)
|
| 180 |
+
else:
|
| 181 |
+
command = [
|
| 182 |
+
"torchrun",
|
| 183 |
+
f"--nproc_per_node={args.gpus}",
|
| 184 |
+
"run_for_bash.py",
|
| 185 |
+
"--config",
|
| 186 |
+
f"{config_path}",
|
| 187 |
+
"--data",
|
| 188 |
+
f"{dataset}",
|
| 189 |
+
"--verbose",
|
| 190 |
+
"--work-dir",
|
| 191 |
+
f"{save_dir}",
|
| 192 |
+
]
|
| 193 |
+
|
| 194 |
+
stdout_file = os.path.join(save_dir, f"out.log")
|
| 195 |
+
stderr_file = os.path.join(save_dir, f"err.log")
|
| 196 |
+
|
| 197 |
+
with open(stdout_file, "w") as stdout, open(stderr_file, "w") as stderr:
|
| 198 |
+
try:
|
| 199 |
+
print(f"Output redirected to {stdout_file}")
|
| 200 |
+
print(f"Errors redirected to {stderr_file}", flush=True)
|
| 201 |
+
|
| 202 |
+
process = subprocess.Popen(
|
| 203 |
+
command, env=env_vars, stdout=stdout, stderr=subprocess.PIPE, text=True
|
| 204 |
+
)
|
| 205 |
+
|
| 206 |
+
for line in process.stderr:
|
| 207 |
+
print(line, end="") # 输出到屏幕
|
| 208 |
+
stderr.write(line) # 写入文件
|
| 209 |
+
|
| 210 |
+
# 等待命令完成
|
| 211 |
+
process.wait()
|
| 212 |
+
|
| 213 |
+
if process.returncode != 0:
|
| 214 |
+
print(f"Command failed with return code {process.returncode}. Check {stderr_file} for error details.", flush=True)
|
| 215 |
+
except subprocess.CalledProcessError as e:
|
| 216 |
+
print(f"torchrun failed. Check {stderr_file} for error details.", flush=True)
|
| 217 |
+
|
| 218 |
+
|
| 219 |
+
if __name__ == "__main__":
|
| 220 |
+
if not os.path.exists("/root/LMUData"):
|
| 221 |
+
os.symlink("/user/konglingyu/LMUData", "/root/LMUData")
|
| 222 |
+
main()
|
do_eval_temp.py
ADDED
|
@@ -0,0 +1,196 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
import argparse
|
| 2 |
+
import json
|
| 3 |
+
import os
|
| 4 |
+
from datetime import datetime
|
| 5 |
+
import subprocess
|
| 6 |
+
import logging
|
| 7 |
+
|
| 8 |
+
full_datasets = {
|
| 9 |
+
"MathVista_MINI": ["train_prompt_sampling"],
|
| 10 |
+
"MathVision": ["train_prompt_greedy"],
|
| 11 |
+
"MathVerse_MINI": ["train_prompt_greedy"],
|
| 12 |
+
"MMMU_DEV_VAL": ["origin_prompt_greedy"],
|
| 13 |
+
"MMStar": ["train_prompt_greedy"],
|
| 14 |
+
"DynaMath": ["train_prompt_greedy"],
|
| 15 |
+
"WeMath": ["train_prompt_greedy"],
|
| 16 |
+
"TextVQA_VAL": ["origin_prompt_greedy"],
|
| 17 |
+
"MMVet": ["origin_prompt_greedy"],
|
| 18 |
+
"MMDocBench": ["origin_prompt_greedy"],
|
| 19 |
+
"AI2D_TEST": ["origin_prompt_greedy"],
|
| 20 |
+
"HallusionBench": ["origin_prompt_greedy"],
|
| 21 |
+
"MMBench_DEV_EN_V11": ["origin_prompt_greedy"],
|
| 22 |
+
"OCRBench": ["origin_prompt_greedy"],
|
| 23 |
+
"DocVQA_VAL": ["origin_prompt_greedy"],
|
| 24 |
+
"EMMA-mini": ["train_prompt_sampling"],
|
| 25 |
+
# "DocVQA_TEST": ["origin_prompt_greedy"],
|
| 26 |
+
# "MMBench_TEST_EN_V11": ["origin_prompt_greedy"],
|
| 27 |
+
}
|
| 28 |
+
|
| 29 |
+
settings = {
|
| 30 |
+
"train_prompt_sampling": {
|
| 31 |
+
"use_reasoning_prompt": 2,
|
| 32 |
+
"do_sample": True,
|
| 33 |
+
"top_p": 1,
|
| 34 |
+
"top_k": -1,
|
| 35 |
+
"temperature": 1,
|
| 36 |
+
},
|
| 37 |
+
"train_prompt_greedy": {
|
| 38 |
+
"use_reasoning_prompt": 2,
|
| 39 |
+
"do_sample": True,
|
| 40 |
+
"top_p": 0.001,
|
| 41 |
+
"top_k": 1,
|
| 42 |
+
"temperature": 0.01,
|
| 43 |
+
},
|
| 44 |
+
"origin_prompt_greedy": {
|
| 45 |
+
"use_reasoning_prompt": 0,
|
| 46 |
+
"do_sample": True,
|
| 47 |
+
"top_p": 0.001,
|
| 48 |
+
"top_k": 1,
|
| 49 |
+
"temperature": 0.01,
|
| 50 |
+
},
|
| 51 |
+
}
|
| 52 |
+
|
| 53 |
+
|
| 54 |
+
def main():
|
| 55 |
+
parser = argparse.ArgumentParser()
|
| 56 |
+
|
| 57 |
+
parser.add_argument("--run_name", type=str, required=True, help="Name of the run")
|
| 58 |
+
parser.add_argument("--gpus", type=int, default=8, help="Number of GPUs to use")
|
| 59 |
+
parser.add_argument("--path", type=str, required=True, help="Path to the model")
|
| 60 |
+
parser.add_argument(
|
| 61 |
+
"--dataset", type=str, nargs="+", required=True, help="List of datasets to use"
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
parser.add_argument(
|
| 65 |
+
"--min_pixels", type=int, default=3136, help="Minimum number of pixels"
|
| 66 |
+
)
|
| 67 |
+
parser.add_argument(
|
| 68 |
+
"--max_pixels", type=int, default=12845056, help="Maximum number of pixels"
|
| 69 |
+
)
|
| 70 |
+
parser.add_argument(
|
| 71 |
+
"--max_new_tokens", type=int, default=2048, help="Maximum number of new tokens"
|
| 72 |
+
)
|
| 73 |
+
|
| 74 |
+
args = parser.parse_args()
|
| 75 |
+
assert len(args.dataset), "--dataset should be a list of datasets"
|
| 76 |
+
|
| 77 |
+
datasets = args.dataset
|
| 78 |
+
if len(args.dataset) == 1 and args.dataset[0] == "full":
|
| 79 |
+
datasets = list(full_datasets.keys())
|
| 80 |
+
|
| 81 |
+
for dataset in datasets:
|
| 82 |
+
assert (
|
| 83 |
+
dataset in full_datasets
|
| 84 |
+
), f"Dataset {dataset} is not in the list of available datasets: {list(full_datasets.keys())}"
|
| 85 |
+
|
| 86 |
+
print("Datasets to be used:", datasets)
|
| 87 |
+
print("Run name:", args.run_name)
|
| 88 |
+
print("Number of GPUs:", args.gpus)
|
| 89 |
+
print("Model path:", args.path)
|
| 90 |
+
print("Minimum pixels:", args.min_pixels)
|
| 91 |
+
print("Maximum pixels:", args.max_pixels)
|
| 92 |
+
print("Maximum new tokens:", args.max_new_tokens, flush=True)
|
| 93 |
+
|
| 94 |
+
for dataset in datasets:
|
| 95 |
+
assert isinstance(full_datasets[dataset], list)
|
| 96 |
+
for setting in full_datasets[dataset]:
|
| 97 |
+
config = {
|
| 98 |
+
"model": {
|
| 99 |
+
args.run_name: {
|
| 100 |
+
"class": "Qwen2VLChat",
|
| 101 |
+
"model_path": args.path,
|
| 102 |
+
"min_pixels": args.min_pixels,
|
| 103 |
+
"max_pixels": args.max_pixels,
|
| 104 |
+
"use_vllm": True,
|
| 105 |
+
"max_new_tokens": args.max_new_tokens,
|
| 106 |
+
**settings[setting],
|
| 107 |
+
},
|
| 108 |
+
},
|
| 109 |
+
"datasets": datasets,
|
| 110 |
+
}
|
| 111 |
+
|
| 112 |
+
current_datetime = datetime.now().strftime("%Y%m%d")
|
| 113 |
+
save_dir = f"public_eval/{args.run_name}/{dataset}_{setting}/{current_datetime}"
|
| 114 |
+
os.makedirs(save_dir, exist_ok=True)
|
| 115 |
+
|
| 116 |
+
config_name = f"config.json"
|
| 117 |
+
config_path = os.path.join(save_dir, config_name)
|
| 118 |
+
with open(config_path, "w") as json_file:
|
| 119 |
+
json.dump(config, json_file, indent=4)
|
| 120 |
+
|
| 121 |
+
print(f"Start evaluating on {dataset}.")
|
| 122 |
+
print(f"Eval config {setting}", flush=True)
|
| 123 |
+
|
| 124 |
+
env_vars = os.environ.copy()
|
| 125 |
+
env_vars["VLLM_USE_V1"] = "0"
|
| 126 |
+
|
| 127 |
+
if dataset == "EMMA" or dataset == "EMMA-mini":
|
| 128 |
+
logger = logging.getLogger('EMMA-logger')
|
| 129 |
+
logger.setLevel(level=logging.DEBUG)
|
| 130 |
+
|
| 131 |
+
formatter = logging.Formatter('%(asctime)s - %(filename)s[line:%(lineno)d] - %(levelname)s: %(message)s')
|
| 132 |
+
|
| 133 |
+
file_handler = logging.FileHandler(os.path.join(save_dir, f"out.log"))
|
| 134 |
+
file_handler.setLevel(level=logging.DEBUG)
|
| 135 |
+
file_handler.setFormatter(formatter)
|
| 136 |
+
|
| 137 |
+
stream_handler = logging.StreamHandler()
|
| 138 |
+
stream_handler.setLevel(logging.DEBUG)
|
| 139 |
+
stream_handler.setFormatter(formatter)
|
| 140 |
+
|
| 141 |
+
logger.addHandler(file_handler)
|
| 142 |
+
logger.addHandler(stream_handler)
|
| 143 |
+
|
| 144 |
+
from EMMA.generate_response import do_generate
|
| 145 |
+
from EMMA.evaluation.evaluate import gen_true_false
|
| 146 |
+
from EMMA.evaluation.calculate_acc import gen_score
|
| 147 |
+
|
| 148 |
+
dataset_name = f"/root/LMUData/{dataset}"
|
| 149 |
+
os.environ["VLLM_USE_V1"] = "0"
|
| 150 |
+
os.environ["VLLM_WORKER_MULTIPROC_METHOD"] = "spawn"
|
| 151 |
+
do_generate(dataset_name, args.path, f"{save_dir}/results.json", logger=logger, seed=114413)
|
| 152 |
+
gen_true_false(f"{save_dir}/results.json", logger=logger)
|
| 153 |
+
gen_score(f"{save_dir}/results.json", f"{save_dir}/results_acc.json", logger=logger)
|
| 154 |
+
else:
|
| 155 |
+
command = [
|
| 156 |
+
"torchrun",
|
| 157 |
+
f"--nproc_per_node={args.gpus}",
|
| 158 |
+
"run_for_bash.py",
|
| 159 |
+
"--config",
|
| 160 |
+
f"{config_path}",
|
| 161 |
+
"--data",
|
| 162 |
+
f"{dataset}",
|
| 163 |
+
"--verbose",
|
| 164 |
+
"--work-dir",
|
| 165 |
+
f"{save_dir}",
|
| 166 |
+
]
|
| 167 |
+
|
| 168 |
+
stdout_file = os.path.join(save_dir, f"out.log")
|
| 169 |
+
stderr_file = os.path.join(save_dir, f"err.log")
|
| 170 |
+
|
| 171 |
+
with open(stdout_file, "w") as stdout, open(stderr_file, "w") as stderr:
|
| 172 |
+
try:
|
| 173 |
+
print(f"Output redirected to {stdout_file}")
|
| 174 |
+
print(f"Errors redirected to {stderr_file}", flush=True)
|
| 175 |
+
|
| 176 |
+
process = subprocess.Popen(
|
| 177 |
+
command, env=env_vars, stdout=stdout, stderr=subprocess.PIPE, text=True
|
| 178 |
+
)
|
| 179 |
+
|
| 180 |
+
for line in process.stderr:
|
| 181 |
+
print(line, end="") # 输出到屏幕
|
| 182 |
+
stderr.write(line) # 写入文件
|
| 183 |
+
|
| 184 |
+
# 等待命令完成
|
| 185 |
+
process.wait()
|
| 186 |
+
|
| 187 |
+
if process.returncode != 0:
|
| 188 |
+
print(f"Command failed with return code {process.returncode}. Check {stderr_file} for error details.", flush=True)
|
| 189 |
+
except subprocess.CalledProcessError as e:
|
| 190 |
+
print(f"torchrun failed. Check {stderr_file} for error details.", flush=True)
|
| 191 |
+
|
| 192 |
+
|
| 193 |
+
if __name__ == "__main__":
|
| 194 |
+
if not os.path.exists("/root/LMUData"):
|
| 195 |
+
os.symlink("/user/konglingyu/LMUData", "/root/LMUData")
|
| 196 |
+
main()
|
docs/en/.readthedocs.yaml
ADDED
|
@@ -0,0 +1,17 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version: 2
|
| 2 |
+
|
| 3 |
+
# Set the version of Python and other tools you might need
|
| 4 |
+
build:
|
| 5 |
+
os: ubuntu-22.04
|
| 6 |
+
tools:
|
| 7 |
+
python: "3.8"
|
| 8 |
+
|
| 9 |
+
formats:
|
| 10 |
+
- epub
|
| 11 |
+
|
| 12 |
+
sphinx:
|
| 13 |
+
configuration: docs/en/conf.py
|
| 14 |
+
|
| 15 |
+
python:
|
| 16 |
+
install:
|
| 17 |
+
- requirements: requirements/docs.txt
|
docs/en/ConfigSystem.md
ADDED
|
@@ -0,0 +1,67 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Config System
|
| 2 |
+
|
| 3 |
+
By default, VLMEvalKit launches the evaluation by setting the model name(s) (defined in `/vlmeval/config.py`) and dataset name(s) (defined in `vlmeval/dataset/__init__.py` or `vlmeval/dataset/video_dataset_config.py`) in the `run.py` script with the `--model` and `--data` arguments. Such approach is simple and efficient in most scenarios, however, it may not be flexible enough when the user wants to evaluate multiple models / datasets with different settings.
|
| 4 |
+
|
| 5 |
+
To address this, VLMEvalKit provides a more flexible config system. The user can specify the model and dataset settings in a json file, and pass the path to the config file to the `run.py` script with the `--config` argument. Here is a sample config json:
|
| 6 |
+
|
| 7 |
+
```json
|
| 8 |
+
{
|
| 9 |
+
"model": {
|
| 10 |
+
"GPT4o_20240806_T00_HIGH": {
|
| 11 |
+
"class": "GPT4V",
|
| 12 |
+
"model": "gpt-4o-2024-08-06",
|
| 13 |
+
"temperature": 0,
|
| 14 |
+
"img_detail": "high"
|
| 15 |
+
},
|
| 16 |
+
"GPT4o_20240806_T10_Low": {
|
| 17 |
+
"class": "GPT4V",
|
| 18 |
+
"model": "gpt-4o-2024-08-06",
|
| 19 |
+
"temperature": 1.0,
|
| 20 |
+
"img_detail": "low"
|
| 21 |
+
},
|
| 22 |
+
"GPT4o_20241120": {}
|
| 23 |
+
},
|
| 24 |
+
"data": {
|
| 25 |
+
"MME-RealWorld-Lite": {
|
| 26 |
+
"class": "MMERealWorld",
|
| 27 |
+
"dataset": "MME-RealWorld-Lite"
|
| 28 |
+
},
|
| 29 |
+
"MMBench_DEV_EN_V11": {
|
| 30 |
+
"class": "ImageMCQDataset",
|
| 31 |
+
"dataset": "MMBench_DEV_EN_V11"
|
| 32 |
+
},
|
| 33 |
+
"MMBench_Video_8frame_nopack":{},
|
| 34 |
+
"Video-MME_16frame_subs": {
|
| 35 |
+
"class": "VideoMME",
|
| 36 |
+
"dataset": "Video-MME",
|
| 37 |
+
"nframe": 16,
|
| 38 |
+
"use_subtitle": true
|
| 39 |
+
},
|
| 40 |
+
}
|
| 41 |
+
}
|
| 42 |
+
```
|
| 43 |
+
|
| 44 |
+
Explanation of the config json:
|
| 45 |
+
|
| 46 |
+
1. Now we support two fields: `model` and `data`, each of which is a dictionary. The key of the dictionary is the name of the model / dataset (set by the user), and the value is the setting of the model / dataset.
|
| 47 |
+
2. For items in `model`, the value is a dictionary containing the following keys:
|
| 48 |
+
- `class`: The class name of the model, which should be a class name defined in `vlmeval/vlm/__init__.py` (open-source models) or `vlmeval/api/__init__.py` (API models).
|
| 49 |
+
- Other kwargs: Other kwargs are model-specific parameters, please refer to the definition of the model class for detailed usage. For example, `model`, `temperature`, `img_detail` are arguments of the `GPT4V` class. It's noteworthy that the `model` argument is required by most model classes.
|
| 50 |
+
- Tip: The defined model in the `supported_VLM` of `vlmeval/config.py` can be used as a shortcut, for example, `GPT4o_20241120: {}` is equivalent to `GPT4o_20241120: {'class': 'GPT4V', 'model': 'gpt-4o-2024-11-20', 'temperature': 0, 'img_size': -1, 'img_detail': 'high', 'retry': 10, 'verbose': False}`
|
| 51 |
+
3. For the dictionary `data`, we suggest users to use the official dataset name as the key (or part of the key), since we frequently determine the post-processing / judging settings based on the dataset name. For items in `data`, the value is a dictionary containing the following keys:
|
| 52 |
+
- `class`: The class name of the dataset, which should be a class name defined in `vlmeval/dataset/__init__.py`.
|
| 53 |
+
- Other kwargs: Other kwargs are dataset-specific parameters, please refer to the definition of the dataset class for detailed usage. Typically, the `dataset` argument is required by most dataset classes. It's noteworthy that the `nframe` argument or `fps` argument is required by most video dataset classes.
|
| 54 |
+
- Tip: The defined dataset in the `supported_video_datasets` of `vlmeval/dataset/video_dataset_config.py` can be used as a shortcut, for example, `MMBench_Video_8frame_nopack: {}` is equivalent to `MMBench_Video_8frame_nopack: {'class': 'MMBenchVideo', 'dataset': 'MMBench-Video', 'nframe': 8, 'pack': False}`.
|
| 55 |
+
Saving the example config json to `config.json`, you can launch the evaluation by:
|
| 56 |
+
|
| 57 |
+
```bash
|
| 58 |
+
python run.py --config config.json
|
| 59 |
+
```
|
| 60 |
+
|
| 61 |
+
That will generate the following output files under the working directory `$WORK_DIR` (Following the format `{$WORK_DIR}/{$MODEL_NAME}/{$MODEL_NAME}_{$DATASET_NAME}_*`):
|
| 62 |
+
|
| 63 |
+
- `$WORK_DIR/GPT4o_20240806_T00_HIGH/GPT4o_20240806_T00_HIGH_MME-RealWorld-Lite*`
|
| 64 |
+
- `$WORK_DIR/GPT4o_20240806_T10_Low/GPT4o_20240806_T10_Low_MME-RealWorld-Lite*`
|
| 65 |
+
- `$WORK_DIR/GPT4o_20240806_T00_HIGH/GPT4o_20240806_T00_HIGH_MMBench_DEV_EN_V11*`
|
| 66 |
+
- `$WORK_DIR/GPT4o_20240806_T10_Low/GPT4o_20240806_T10_Low_MMBench_DEV_EN_V11*`
|
| 67 |
+
...
|
docs/en/Contributors.md
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Contributors
|
| 2 |
+
|
| 3 |
+
## Contributors w. 3+ Major Contributions
|
| 4 |
+
|
| 5 |
+
> In this section, we list all the contributors who have made significant contributions (3+) to the development of VLMEvalKit.
|
| 6 |
+
|
| 7 |
+
New Qualified Contributors (2024.09):
|
| 8 |
+
|
| 9 |
+
1. [amitbcp](https://github.com/amitbcp): The contributor helped support MUIRBench, Phi-3.5, Idefics3, VILA, and xGen-MM
|
| 10 |
+
2. [czczup](https://github.com/czczup): The contributor helped support the InternVL Series (V1.5, Mini-InternVL, V2, etc.)
|
| 11 |
+
3. [DseidLi](https://github.com/DseidLi): The contributor helped support LLaVA-OneVision, GQA, and developed the readthedocs site for VLMEvalKit
|
| 12 |
+
4. [mayubo2333](https://github.com/mayubo2333): The contributor helped support MMLongBench, SlideVQA, and DUDE
|
| 13 |
+
5. [sun-hailong](https://github.com/sun-hailong): The contributor helped support A-OKVQA, Parrot, MMMB, and MTL-MMBench
|
| 14 |
+
6. [PhoenixZ810](https://github.com/PhoenixZ810): The contributor helped support Video-ChatGPT, Chat-UniVI, and Llama-VID
|
| 15 |
+
7. [Cuiunbo](https://github.com/Cuiunbo): The contributor helped support OmniLMM-12B, MiniCPM-V Series (V1, V2, V2.5)
|
| 16 |
+
|
| 17 |
+
## Full Contributor List
|
| 18 |
+
|
| 19 |
+
> In this section, we list all the contributors as well as their corresponding contributions to the development of VLMEvalKit.
|
| 20 |
+
|
| 21 |
+
TBD.
|
docs/en/Development.md
ADDED
|
@@ -0,0 +1,145 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Develop new Benchmark / MLLM
|
| 2 |
+
|
| 3 |
+
> 🛠️ How to implement a new Benchmark / VLM in VLMEvalKit?
|
| 4 |
+
|
| 5 |
+
## Implement a new benchmark
|
| 6 |
+
|
| 7 |
+
Example PR: **Math-Vision Benchmark** ([#292](https://github.com/open-compass/VLMEvalKit/pull/292/files))
|
| 8 |
+
|
| 9 |
+
In VLMEvalKit, benchmarks are organized as dataset classes. When you try to implement a new benchmark, you can either reuse existing dataset classes (*e.g.*, You can reuse `ImageMCQDataset` when implementing a new multi-choice benchmark), or support a new dataset class. Each dataset must have the following two member functions (either reuse the one of the parent class or implement your own):
|
| 10 |
+
|
| 11 |
+
- `build_prompt(self, line)`: The function input `line` is an integer (the sample index) or a `pd.Series` object (the raw record of the sample). The function outputs a `multi-modal message`, serving as the input of an MLLM. The `multi-modal message` is an interleaved list of multi-modal messages adopting the following format (the example includes an image and a text message): `[dict(type='image', value=IMAGE_PTH), dict(type='text', value=prompt)]`.
|
| 12 |
+
- `evaluate(self, eval_file, **judge_kwargs)`: The function input `eval_file` is the MLLM prediction (typically in `.xlsx` format). If the benchmark requires an external LLM (typically GPT) for evaluation, then `judge_kwargs` can pass the arguments for the LLM. The function outputs the benchmark evaluation results (metrics) in the form of `dict` or `pd.DataFrame`.
|
| 13 |
+
|
| 14 |
+
We then brief the typical steps to implement a new benchmark under VLMEvalKit:
|
| 15 |
+
|
| 16 |
+
### 1. Prepare your benchmark tsv file
|
| 17 |
+
|
| 18 |
+
Currently, we organize a benchmark as one single TSV file. During inference, the data file will be automatically downloaded from the definited `DATASET_URL` link to `$LMUData` file (default path is `$HOME/LMUData`, if not set explicitly). You can upload the prepared TSV file to a downloadable address (e.g., Huggingface) or send it to us at <[email protected]>. We will assist in uploading the dataset to the server. You can also customize `LMUData` path in the environment variable `LMUData=/path/to/your/data`.
|
| 19 |
+
|
| 20 |
+
The contents of the TSV file consist of:
|
| 21 |
+
|
| 22 |
+
| Dataset Name \ Fields | index | image | image_path | question | hint | multi-choice<br>options | answer | category | l2-category | split |
|
| 23 |
+
| --------------------------------------- | ----- | ----- | ---------- | -------- | ---- | ----------------------- | ------ | -------- | ----------- | ----- |
|
| 24 |
+
| MMBench_DEV_[CN/EN] | ✅ | ✅ | | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 25 |
+
| MMBench_TEST_[CN/EN] | ✅ | ✅ | | ✅ | ✅ | ✅ | | ✅ | ✅ | ✅ |
|
| 26 |
+
| CCBench | ✅ | ✅ | | ✅ | | ✅ | ✅ | ✅ | | |
|
| 27 |
+
| SEEDBench_IMG | ✅ | ✅ | | ✅ | | ✅ | ✅ | ✅ | | |
|
| 28 |
+
| MME | ✅ | ✅ | | ✅ | | | ✅ | ✅ | | |
|
| 29 |
+
| MMVet | ✅ | ✅ | | ✅ | | | ✅ | ✅ | | |
|
| 30 |
+
| MMMU_DEV_VAL | ✅ | ✅ | ✅ | ✅ | | ✅ | ✅ | ✅ | ✅ | ✅ |
|
| 31 |
+
| COCO_VAL | ✅ | ✅ | | | | | ✅ | | | |
|
| 32 |
+
| OCRVQA_[TEST/TESTCORE] | ✅ | ✅ | | ✅ | | | ✅ | | | |
|
| 33 |
+
| TextVQA_VAL | ✅ | ✅ | | ✅ | | | ✅ | | | |
|
| 34 |
+
| VCR_[EN/ZH]\_[EASY/HARD]\_[ALL/500/100] | ✅ | ✅ | | ✅ | | | ✅ | | | |
|
| 35 |
+
| MMMB_[en/cn/pt/ar/tr/ru] | ✅ | ✅ | | ✅ | ✅ | ✅ | ✅ | ✅ | |✅ |
|
| 36 |
+
| MMBench_dev_[en/cn/pt/ar/tr/ru] | ✅ | ✅ | | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |✅ |
|
| 37 |
+
|
| 38 |
+
<div align="center"><b>Table 1. TSV fields of supported datasets.</b></div>
|
| 39 |
+
|
| 40 |
+
**Intro to mandatory fields in the `TSV` file:**
|
| 41 |
+
|
| 42 |
+
- **index:** Integer, Unique for each line in `tsv`
|
| 43 |
+
- **image:** The base64 of the image, you can use APIs implemented in `vlmeval/smp/vlm.py` for encoding and decoding:
|
| 44 |
+
- Encoding: `encode_image_to_base64 `(for PIL Image) / `encode_image_file_to_base64` (for image file path)
|
| 45 |
+
- Decoding: `decode_base64_to_image`(for PIL Image) / `decode_base64_to_image_file` (for image file path)
|
| 46 |
+
- **question**: The question corresponding to the image, a string
|
| 47 |
+
- **answer**: The answer to the question, a string. The `test` split does not need this field
|
| 48 |
+
|
| 49 |
+
### 2. Cutomize your benchmark prompt
|
| 50 |
+
|
| 51 |
+
`ImageBaseDataset` defines the default prompt format. If you need to add prompts specific to the dataset or input data in the `Interleave` format to the model, you can implement this through the `build_prompt(line)` function. This function takes a line from a TSV file as input, containing fields such as index, image, question, etc. The function returns a dictionary list of multimodal messages `msg` in the format `[dict(type='image', value=IMAGE_PTH), dict(type='text', value=prompt)]`, including the image path and the text prompt to be input into VLMs. For interleave type inputs, you can directly place the dictionary of the image path at the image token position.
|
| 52 |
+
|
| 53 |
+
### 3. Cutomize your benchmark metrics
|
| 54 |
+
|
| 55 |
+
To add evaluation for a new benchmark, you need to customize a class object to implement the dataset’s metrics calculation. Multimodal datasets inherit from the `ImageBaseDataset` object in `vlmeval/dataset/image_base.py`. The TYPE defines the type of dataset, `DATASET_URL` is the download address of the dataset, and `DATASET_MD5` is the MD5 checksum for consistency checking of the dataset file.
|
| 56 |
+
|
| 57 |
+
In this class, **you need to implement** the `evaluate(eval_file, **judge_kwargs)` class function to calculate metrics and output results for the custom dataset. The function input `eval_file` is the path to the model prediction results file `{model_name}_{dataset}.xlsx`. This file can be read as a pandas.DataFrame using the `load(eval_file)` method, containing fields such as index, question, answer, category, prediction, etc. The judge_kwargs will pass a dictionary related to evaluation, such as the name of the `judge model`, the number of API request threads, etc. **The return value** of the function is the calculated accuracy and other metrics, formatted as a dictionary composed of lists, organized into a pandas.DataFrame.
|
| 58 |
+
|
| 59 |
+
## Implement a new model
|
| 60 |
+
|
| 61 |
+
Example PR: **Support LLaVA-Next-Interleave** ([#294](https://github.com/open-compass/VLMEvalKit/pull/294))
|
| 62 |
+
|
| 63 |
+
**1. Support `generate_inner` API (mandatory).**
|
| 64 |
+
|
| 65 |
+
All existing models are implemented in `vlmeval/vlm`. For a minimal model, your model class **must implement the method** `generate_inner(msgs, dataset=None)`. In this function, you feed a multi-modal message to your VLM and return the VLM prediction (which is a string). The optional argument `dataset` can be used as the flag for the model to switch among various inference strategies.
|
| 66 |
+
|
| 67 |
+
The multi-modal messages `msgs` is a list of dictionaries, each dictionary has two keys: type and value:
|
| 68 |
+
- `type`: We currently support two types, choices are ["image", "text"].
|
| 69 |
+
- `value`: When type=='text' , the value is the text message (a single string); when type=='image', the value can be the local path of an image file, or the image URL.
|
| 70 |
+
|
| 71 |
+
Currently a multi-modal message may contain arbitrarily interleaved images and texts. If your model do not support that, a practice can be taking the 1st image and concatenated text messages as the input. You can set the `INTERLEAVE = False` in your model class and use `self.message_to_promptimg(message, dataset=dataset)` to build your prompt and the first image's path.
|
| 72 |
+
|
| 73 |
+
Here are some examples of multi-modal messages:
|
| 74 |
+
|
| 75 |
+
```python
|
| 76 |
+
IMAGE_PTH = 'assets/apple.jpg'
|
| 77 |
+
IMAGE_URL = 'https://raw.githubusercontent.com/open-compass/VLMEvalKit/main/assets/apple.jpg'
|
| 78 |
+
msg1 = [
|
| 79 |
+
dict(type='image', value=IMAGE_PTH),
|
| 80 |
+
dict(type='text', value='What is in this image?')
|
| 81 |
+
]
|
| 82 |
+
msg2 = [
|
| 83 |
+
dict(type='image', value=IMAGE_URL),
|
| 84 |
+
dict(type='image', value=IMAGE_URL),
|
| 85 |
+
dict(type='text', value='How many apples are there in these images?')
|
| 86 |
+
]
|
| 87 |
+
response = model.generate(msg1)
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
For convenience sake, we also support to take a list of string as inputs. In that case, we will check if a string is an image path or image URL and automatically convert it to the list[dict] format:
|
| 91 |
+
|
| 92 |
+
```python
|
| 93 |
+
IMAGE_PTH = 'assets/apple.jpg'
|
| 94 |
+
IMAGE_URL = 'https://raw.githubusercontent.com/open-compass/VLMEvalKit/main/assets/apple.jpg'
|
| 95 |
+
msg1 = [IMAGE_PTH, 'What is in this image?']
|
| 96 |
+
msg2 = [IMAGE_URL, IMAGE_URL, 'How many apples are there in these images?']
|
| 97 |
+
response = model.generate(msg1)
|
| 98 |
+
```
|
| 99 |
+
|
| 100 |
+
**Support Custom Prompt (optional).**
|
| 101 |
+
|
| 102 |
+
Besides, your model can support **custom prompt building** by implementing two optional methods: `use_custom_prompt(dataset)` and `build_prompt(line, dataset=None)`.
|
| 103 |
+
|
| 104 |
+
Both functions take the dataset name as the input:
|
| 105 |
+
|
| 106 |
+
- `use_custom_prompt(dataset)` returns a boolean flag, indicating whether the model should use the custom prompt building strategy.
|
| 107 |
+
- If `use_custom_prompt(dataset)` returns True, `build_prompt(line, dataset)` should return a customly bulit multimodal message for the corresponding `dataset`, given `line`, which is a dictionary that includes the necessary information of a data sample. If `use_custom_prompt(dataset)` returns False, the default prompt building strategy will be used.
|
| 108 |
+
|
| 109 |
+
**Support multi-turn chatting (optional).**
|
| 110 |
+
|
| 111 |
+
You can also support the multi-turn chatting and evaluation with your VLM by supporting the `chat_inner(message, dataset)` function. The function outputs a single string response, and the `message` is a list of chat history, following the below format.
|
| 112 |
+
|
| 113 |
+
```python
|
| 114 |
+
# Assume msg1, msg2, msg3, ... are multi-modal messages following the previously described format
|
| 115 |
+
# `chat_inner` take the following chat history list as input:
|
| 116 |
+
message = [
|
| 117 |
+
dict(role='user', content=msg1),
|
| 118 |
+
dict(role='assistant', content=msg2),
|
| 119 |
+
dict(role='user', content=msg3),
|
| 120 |
+
dict(role='assistant', content=msg4),
|
| 121 |
+
......
|
| 122 |
+
dict(role='user', content=msgn),
|
| 123 |
+
]
|
| 124 |
+
# `message` should contain an odd number of chat utterances, the role of utterances should be interleaved "user" and "assistant", with the role of the last utterance to be "user".
|
| 125 |
+
# The chat function will call `chat_inner`
|
| 126 |
+
response = model.chat(message)
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
### Example PRs:
|
| 130 |
+
|
| 131 |
+
- VLM that doesn't support interleaved images and texts, and does not use custom prompts: [[Model] Support glm-4v-9b](https://github.com/open-compass/VLMEvalKit/pull/221)
|
| 132 |
+
- VLM that supports interleaved images and texts and custom prompts: [Add MiniCPM-Llama3-V-2.5](https://github.com/open-compass/VLMEvalKit/pull/205)
|
| 133 |
+
- VLM API: [Feature add glmv](https://github.com/open-compass/VLMEvalKit/pull/201)
|
| 134 |
+
|
| 135 |
+
## Contribute to VLMEvalKit
|
| 136 |
+
|
| 137 |
+
If you want to contribute codes to **VLMEvalKit**, please do the pre-commit check before you submit a PR. That helps to keep the code tidy.
|
| 138 |
+
|
| 139 |
+
```bash
|
| 140 |
+
# Under the directory of VLMEvalKit, install the pre-commit hook:
|
| 141 |
+
pip install pre-commit
|
| 142 |
+
pre-commit install
|
| 143 |
+
pre-commit run --all-files
|
| 144 |
+
# Then you can commit your code.
|
| 145 |
+
```
|
docs/en/EvalByLMDeploy.md
ADDED
|
@@ -0,0 +1,27 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Using LMDeploy to Accelerate Evaluation and Inference
|
| 2 |
+
|
| 3 |
+
VLMEvalKit supports testing VLM models deployed by LMDeploy. Below, we use InternVL2-8B as an example to show how to test the model.
|
| 4 |
+
|
| 5 |
+
## Step 0: Install LMDeploy
|
| 6 |
+
|
| 7 |
+
```bash
|
| 8 |
+
pip install lmdeploy
|
| 9 |
+
```
|
| 10 |
+
For other installation methods, you can refer to LMDeploy's [documentation](https://github.com/InternLM/lmdeploy).
|
| 11 |
+
|
| 12 |
+
## Step 1: Start the Inference Service
|
| 13 |
+
|
| 14 |
+
```bash
|
| 15 |
+
lmdeploy serve api_server OpenGVLab/InternVL2-8B --model-name InternVL2-8B
|
| 16 |
+
```
|
| 17 |
+
> [!IMPORTANT]
|
| 18 |
+
> Since models in VLMEvalKit may have custom behaviors when building prompts for different datasets, such as InternVL2's handling of HallusionBench, it is necessary to specify `--model-name` when starting the server. This allows the VLMEvalKit to select appropriate prompt construction strategy based on the name when using the LMDeploy API.
|
| 19 |
+
>
|
| 20 |
+
> If `--server-port`, is specified, the corresponding environment variable `LMDEPLOY_API_BASE` needs to be set.
|
| 21 |
+
|
| 22 |
+
|
| 23 |
+
## Step 2: Evaluation
|
| 24 |
+
|
| 25 |
+
```bash
|
| 26 |
+
python run.py --data MMStar --model lmdeploy --verbose --api-nproc 64
|
| 27 |
+
```
|
docs/en/Makefile
ADDED
|
@@ -0,0 +1,20 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Minimal makefile for Sphinx documentation
|
| 2 |
+
#
|
| 3 |
+
|
| 4 |
+
# You can set these variables from the command line, and also
|
| 5 |
+
# from the environment for the first two.
|
| 6 |
+
SPHINXOPTS ?=
|
| 7 |
+
SPHINXBUILD ?= sphinx-build
|
| 8 |
+
SOURCEDIR = .
|
| 9 |
+
BUILDDIR = _build
|
| 10 |
+
|
| 11 |
+
# Put it first so that "make" without argument is like "make help".
|
| 12 |
+
help:
|
| 13 |
+
@$(SPHINXBUILD) -M help "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
| 14 |
+
|
| 15 |
+
.PHONY: help Makefile
|
| 16 |
+
|
| 17 |
+
# Catch-all target: route all unknown targets to Sphinx using the new
|
| 18 |
+
# "make mode" option. $(O) is meant as a shortcut for $(SPHINXOPTS).
|
| 19 |
+
%: Makefile
|
| 20 |
+
@$(SPHINXBUILD) -M $@ "$(SOURCEDIR)" "$(BUILDDIR)" $(SPHINXOPTS) $(O)
|
docs/en/Quickstart.md
ADDED
|
@@ -0,0 +1,212 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Quickstart
|
| 2 |
+
|
| 3 |
+
Before running the evaluation script, you need to **configure** the VLMs and set the model_paths properly.
|
| 4 |
+
|
| 5 |
+
After that, you can use a single script `run.py` to inference and evaluate multiple VLMs and benchmarks at a same time.
|
| 6 |
+
|
| 7 |
+
## Step 0. Installation & Setup essential keys
|
| 8 |
+
|
| 9 |
+
**Installation.**
|
| 10 |
+
|
| 11 |
+
```bash
|
| 12 |
+
git clone https://github.com/open-compass/VLMEvalKit.git
|
| 13 |
+
cd VLMEvalKit
|
| 14 |
+
pip install -e .
|
| 15 |
+
```
|
| 16 |
+
|
| 17 |
+
**Setup Keys.**
|
| 18 |
+
|
| 19 |
+
To infer with API models (GPT-4v, Gemini-Pro-V, etc.) or use LLM APIs as the **judge or choice extractor**, you need to first setup API keys. VLMEvalKit will use an judge **LLM** to extract answer from the output if you set the key, otherwise it uses the **exact matching** mode (find "Yes", "No", "A", "B", "C"... in the output strings). **The exact matching can only be applied to the Yes-or-No tasks and the Multi-choice tasks.**
|
| 20 |
+
- You can place the required keys in `$VLMEvalKit/.env` or directly set them as the environment variable. If you choose to create a `.env` file, its content will look like:
|
| 21 |
+
|
| 22 |
+
```bash
|
| 23 |
+
# The .env file, place it under $VLMEvalKit
|
| 24 |
+
# API Keys of Proprietary VLMs
|
| 25 |
+
# QwenVL APIs
|
| 26 |
+
DASHSCOPE_API_KEY=
|
| 27 |
+
# Gemini w. Google Cloud Backends
|
| 28 |
+
GOOGLE_API_KEY=
|
| 29 |
+
# OpenAI API
|
| 30 |
+
OPENAI_API_KEY=
|
| 31 |
+
OPENAI_API_BASE=
|
| 32 |
+
# StepAI API
|
| 33 |
+
STEPAI_API_KEY=
|
| 34 |
+
# REKA API
|
| 35 |
+
REKA_API_KEY=
|
| 36 |
+
# GLMV API
|
| 37 |
+
GLMV_API_KEY=
|
| 38 |
+
# CongRong API
|
| 39 |
+
CW_API_BASE=
|
| 40 |
+
CW_API_KEY=
|
| 41 |
+
# SenseChat-V API
|
| 42 |
+
SENSECHAT_AK=
|
| 43 |
+
SENSECHAT_SK=
|
| 44 |
+
# Hunyuan-Vision API
|
| 45 |
+
HUNYUAN_SECRET_KEY=
|
| 46 |
+
HUNYUAN_SECRET_ID=
|
| 47 |
+
# LMDeploy API
|
| 48 |
+
LMDEPLOY_API_BASE=
|
| 49 |
+
# You can also set a proxy for calling api models during the evaluation stage
|
| 50 |
+
EVAL_PROXY=
|
| 51 |
+
```
|
| 52 |
+
|
| 53 |
+
- Fill the blanks with your API keys (if necessary). Those API keys will be automatically loaded when doing the inference and evaluation.
|
| 54 |
+
## Step 1. Configuration
|
| 55 |
+
|
| 56 |
+
**VLM Configuration**: All VLMs are configured in `vlmeval/config.py`. Few legacy VLMs (like MiniGPT-4, LLaVA-v1-7B) requires additional configuration (configuring the code / model_weight root in the config file). During evaluation, you should use the model name specified in `supported_VLM` in `vlmeval/config.py` to select the VLM. Make sure you can successfully infer with the VLM before starting the evaluation with the following command `vlmutil check {MODEL_NAME}`.
|
| 57 |
+
|
| 58 |
+
## Step 2. Evaluation
|
| 59 |
+
|
| 60 |
+
**New!!!** We integrated a new config system to enable more flexible evaluation settings. Check the [Document](/docs/en/ConfigSystem.md) or run `python run.py --help` for more details 🔥🔥🔥
|
| 61 |
+
|
| 62 |
+
We use `run.py` for evaluation. To use the script, you can use `$VLMEvalKit/run.py` or create a soft-link of the script (to use the script anywhere):
|
| 63 |
+
|
| 64 |
+
**Arguments**
|
| 65 |
+
|
| 66 |
+
- `--data (list[str])`: Set the dataset names that are supported in VLMEvalKit (names can be found in the codebase README).
|
| 67 |
+
- `--model (list[str])`: Set the VLM names that are supported in VLMEvalKit (defined in `supported_VLM` in `vlmeval/config.py`).
|
| 68 |
+
- `--mode (str, default to 'all', choices are ['all', 'infer'])`: When `mode` set to "all", will perform both inference and evaluation; when set to "infer", will only perform the inference.
|
| 69 |
+
- `--api-nproc (int, default to 4)`: The number of threads for OpenAI API calling.
|
| 70 |
+
- `--work-dir (str, default to '.')`: The directory to save evaluation results.
|
| 71 |
+
|
| 72 |
+
**Command for Evaluating Image Benchmarks **
|
| 73 |
+
|
| 74 |
+
You can run the script with `python` or `torchrun`:
|
| 75 |
+
|
| 76 |
+
```bash
|
| 77 |
+
# When running with `python`, only one VLM instance is instantiated, and it might use multiple GPUs (depending on its default behavior).
|
| 78 |
+
# That is recommended for evaluating very large VLMs (like IDEFICS-80B-Instruct).
|
| 79 |
+
|
| 80 |
+
# IDEFICS-80B-Instruct on MMBench_DEV_EN, MME, and SEEDBench_IMG, Inference and Evalution
|
| 81 |
+
python run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct --verbose
|
| 82 |
+
# IDEFICS-80B-Instruct on MMBench_DEV_EN, MME, and SEEDBench_IMG, Inference only
|
| 83 |
+
python run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct --verbose --mode infer
|
| 84 |
+
|
| 85 |
+
# When running with `torchrun`, one VLM instance is instantiated on each GPU. It can speed up the inference.
|
| 86 |
+
# However, that is only suitable for VLMs that consume small amounts of GPU memory.
|
| 87 |
+
|
| 88 |
+
# IDEFICS-9B-Instruct, Qwen-VL-Chat, mPLUG-Owl2 on MMBench_DEV_EN, MME, and SEEDBench_IMG. On a node with 8 GPU. Inference and Evaluation.
|
| 89 |
+
torchrun --nproc-per-node=8 run.py --data MMBench_DEV_EN MME SEEDBench_IMG --model idefics_80b_instruct qwen_chat mPLUG-Owl2 --verbose
|
| 90 |
+
# Qwen-VL-Chat on MME. On a node with 2 GPU. Inference and Evaluation.
|
| 91 |
+
torchrun --nproc-per-node=2 run.py --data MME --model qwen_chat --verbose
|
| 92 |
+
```
|
| 93 |
+
|
| 94 |
+
**Command for Evaluating Video Benchmarks**
|
| 95 |
+
|
| 96 |
+
```bash
|
| 97 |
+
# When running with `python`, only one VLM instance is instantiated, and it might use multiple GPUs (depending on its default behavior).
|
| 98 |
+
# That is recommended for evaluating very large VLMs (like IDEFICS-80B-Instruct).
|
| 99 |
+
|
| 100 |
+
# IDEFICS2-8B on MMBench-Video, with 8 frames as inputs and vanilla evaluation. On a node with 8 GPUs. MMBench_Video_8frame_nopack is a defined dataset setting in `vlmeval/dataset/video_dataset_config.py`.
|
| 101 |
+
torchrun --nproc-per-node=8 run.py --data MMBench_Video_8frame_nopack --model idefics2_8
|
| 102 |
+
# GPT-4o (API model) on MMBench-Video, with 1 frame per second as inputs and pack evaluation (all questions of a video in a single query).
|
| 103 |
+
python run.py --data MMBench_Video_1fps_pack --model GPT4o
|
| 104 |
+
```
|
| 105 |
+
|
| 106 |
+
The evaluation results will be printed as logs, besides. **Result Files** will also be generated in the directory `$YOUR_WORKING_DIRECTORY/{model_name}`. Files ending with `.csv` contain the evaluated metrics.
|
| 107 |
+
|
| 108 |
+
### Frequently Asked Questions
|
| 109 |
+
|
| 110 |
+
#### Constructing Input Prompt: The `build_prompt()` Function
|
| 111 |
+
If you find that the model's output does not match the expected results when evaluating a specific benchmark, it could be due to the model not constructing the input prompt correctly.
|
| 112 |
+
|
| 113 |
+
In VLMEvalKit, each `dataset` class includes a function named `build_prompt()`, which is responsible for formatting input questions. Different benchmarks can either customize their own `build_prompt()` function or use the default implementation.
|
| 114 |
+
|
| 115 |
+
For instance, when handling the default [Multiple-Choice QA](https://github.com/open-compass/VLMEvalKit/blob/43af13e052de6805a8b08cd04aed5e0d74f82ff5/vlmeval/dataset/image_mcq.py#L164), the `ImageMCQDataset.build_prompt()` method combines elements such as `hint`, `question`, and `options` (if present in the dataset) into a complete question format, as shown below:
|
| 116 |
+
|
| 117 |
+
```
|
| 118 |
+
HINT
|
| 119 |
+
QUESTION
|
| 120 |
+
Options:
|
| 121 |
+
A. Option A
|
| 122 |
+
B. Option B
|
| 123 |
+
···
|
| 124 |
+
Please select the correct answer from the options above.
|
| 125 |
+
```
|
| 126 |
+
|
| 127 |
+
Additionally, since different models may have varying evaluation requirements, VLMEvalKit also supports customizing the prompt construction method at the model level through `model.build_prompt()`. For an example, you can refer to [InternVL](https://github.com/open-compass/VLMEvalKit/blob/43af13e052de6805a8b08cd04aed5e0d74f82ff5/vlmeval/vlm/internvl_chat.py#L324).
|
| 128 |
+
|
| 129 |
+
**Note: If both `model.build_prompt()` and `dataset.build_prompt()` are defined, `model.build_prompt()` will take precedence over `dataset.build_prompt()`, effectively overriding it.**
|
| 130 |
+
|
| 131 |
+
Some models, such as Qwen2VL and InternVL, define extensive prompt-building methods for various types of benchmarks. To provide more flexibility in adapting to different benchmarks, VLMEvalKit allows users to customize the `model.use_custom_prompt()` function within the model. By adding or modifying the `use_custom_prompt()` function, you can decide which benchmarks should utilize the model's custom prompt logic. Below is an example:
|
| 132 |
+
|
| 133 |
+
```python
|
| 134 |
+
def use_custom_prompt(self, dataset: str) -> bool:
|
| 135 |
+
from vlmeval.dataset import DATASET_TYPE, DATASET_MODALITY
|
| 136 |
+
dataset_type = DATASET_TYPE(dataset, default=None)
|
| 137 |
+
if not self._use_custom_prompt:
|
| 138 |
+
return False
|
| 139 |
+
if listinstr(['MMVet'], dataset):
|
| 140 |
+
return True
|
| 141 |
+
if dataset_type == 'MCQ':
|
| 142 |
+
return True
|
| 143 |
+
if DATASET_MODALITY(dataset) == 'VIDEO':
|
| 144 |
+
return False
|
| 145 |
+
return False
|
| 146 |
+
```
|
| 147 |
+
Only when the `use_custom_prompt()` function returns `True` will VLMEvalKit call the model's `build_prompt()` function for the current benchmark.
|
| 148 |
+
With this approach, you can flexibly control which benchmarks use the model's custom prompt logic based on your specific needs, thereby better adapting to different models and tasks.
|
| 149 |
+
|
| 150 |
+
#### Model Splitting
|
| 151 |
+
|
| 152 |
+
For large models with substantial parameter counts, such as InternVL2-78B, a single GPU may not be able to accommodate the entire model during inference. In such cases, you can define the environment variable `AUTO_SPLIT=1`. For models that support the `split_model()` function, the model will automatically be split and distributed across multiple GPUs.
|
| 153 |
+
|
| 154 |
+
For example, on a machine equipped with 8 GPUs, you can run the model using the following command:
|
| 155 |
+
|
| 156 |
+
```bash
|
| 157 |
+
# For an 8-GPU machine
|
| 158 |
+
AUTO_SPLIT=1 torchrun --nproc-per-node=1 run.py --data MMBench_DEV_EN --model InternVL2-76B --verbose
|
| 159 |
+
```
|
| 160 |
+
This command will automatically split the InternVL2-76B model into 8 parts and run each part on a separate GPU.
|
| 161 |
+
#### Performance Discrepancies
|
| 162 |
+
|
| 163 |
+
Model performance may vary across different environments. As a result, you might observe discrepancies between your evaluation results and those listed on the official VLMEvalKit leaderboard. These differences could be attributed to variations in versions of libraries such as `transformers`, `cuda`, and `torch`.
|
| 164 |
+
|
| 165 |
+
Besides, if you encounter unexpected performance, we recommend first reviewing the local generation records (`{model}_{dataset}.xlsx`) or the evaluation records (`{model}_{dataset}_{judge_model}.xlsx`). This may help you better understand the evaluation outcomes and identify potential issues.
|
| 166 |
+
|
| 167 |
+
## Deploy a local language model as the judge / choice extractor
|
| 168 |
+
The default setting mentioned above uses OpenAI's GPT as the judge LLM. However, you can also deploy a local judge LLM with [LMDeploy](https://github.com/InternLM/lmdeploy).
|
| 169 |
+
|
| 170 |
+
First install:
|
| 171 |
+
```
|
| 172 |
+
pip install lmdeploy openai
|
| 173 |
+
```
|
| 174 |
+
|
| 175 |
+
And then deploy a local judge LLM with the single line of code. LMDeploy will automatically download the model from Huggingface. Assuming we use internlm2-chat-1_8b as the judge, port 23333, and the key sk-123456 (the key must start with "sk-" and follow with any number you like):
|
| 176 |
+
```
|
| 177 |
+
lmdeploy serve api_server internlm/internlm2-chat-1_8b --server-port 23333
|
| 178 |
+
```
|
| 179 |
+
|
| 180 |
+
You need to get the model name registered by LMDeploy with the following python code:
|
| 181 |
+
```
|
| 182 |
+
from openai import OpenAI
|
| 183 |
+
client = OpenAI(
|
| 184 |
+
api_key='sk-123456',
|
| 185 |
+
base_url="http://0.0.0.0:23333/v1"
|
| 186 |
+
)
|
| 187 |
+
model_name = client.models.list().data[0].id
|
| 188 |
+
```
|
| 189 |
+
|
| 190 |
+
Now set some environment variables to tell VLMEvalKit how to use the local judge LLM. As mentioned above, you can also set them in `$VLMEvalKit/.env` file:
|
| 191 |
+
```
|
| 192 |
+
OPENAI_API_KEY=sk-123456
|
| 193 |
+
OPENAI_API_BASE=http://0.0.0.0:23333/v1/chat/completions
|
| 194 |
+
LOCAL_LLM=<model_name you get>
|
| 195 |
+
```
|
| 196 |
+
|
| 197 |
+
Finally, you can run the commands in step 2 to evaluate your VLM with the local judge LLM.
|
| 198 |
+
|
| 199 |
+
Note that
|
| 200 |
+
|
| 201 |
+
- If you hope to deploy the judge LLM in a single GPU and evaluate your VLM on other GPUs because of limited GPU memory, try `CUDA_VISIBLE_DEVICES=x` like
|
| 202 |
+
```
|
| 203 |
+
CUDA_VISIBLE_DEVICES=0 lmdeploy serve api_server internlm/internlm2-chat-1_8b --server-port 23333
|
| 204 |
+
CUDA_VISIBLE_DEVICES=1,2,3 torchrun --nproc-per-node=3 run.py --data HallusionBench --model qwen_chat --verbose
|
| 205 |
+
```
|
| 206 |
+
- If the local judge LLM is not good enough in following the instructions, the evaluation may fail. Please report such failures (e.g., by issues).
|
| 207 |
+
- It's possible to deploy the judge LLM in different ways, e.g., use a private LLM (not from HuggingFace) or use a quantized LLM. Please refer to the [LMDeploy doc](https://lmdeploy.readthedocs.io/en/latest/serving/api_server.html). You can use any other deployment framework if they support OpenAI API.
|
| 208 |
+
|
| 209 |
+
|
| 210 |
+
### Using LMDeploy to Accelerate Evaluation and Inference
|
| 211 |
+
|
| 212 |
+
You can refer this [doc](/docs/en/EvalByLMDeploy.md)
|
docs/en/_static/css/readthedocs.css
ADDED
|
@@ -0,0 +1,63 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.header-logo {
|
| 2 |
+
background-image: url("../image/logo.svg");
|
| 3 |
+
background-size: 275px 80px;
|
| 4 |
+
height: 80px;
|
| 5 |
+
width: 275px;
|
| 6 |
+
}
|
| 7 |
+
|
| 8 |
+
|
| 9 |
+
@media screen and (min-width: 1100px) {
|
| 10 |
+
.header-logo {
|
| 11 |
+
top: -25px;
|
| 12 |
+
}
|
| 13 |
+
}
|
| 14 |
+
|
| 15 |
+
pre {
|
| 16 |
+
white-space: pre;
|
| 17 |
+
}
|
| 18 |
+
|
| 19 |
+
@media screen and (min-width: 2000px) {
|
| 20 |
+
.pytorch-content-left {
|
| 21 |
+
width: 1200px;
|
| 22 |
+
margin-left: 30px;
|
| 23 |
+
}
|
| 24 |
+
article.pytorch-article {
|
| 25 |
+
max-width: 1200px;
|
| 26 |
+
}
|
| 27 |
+
.pytorch-breadcrumbs-wrapper {
|
| 28 |
+
width: 1200px;
|
| 29 |
+
}
|
| 30 |
+
.pytorch-right-menu.scrolling-fixed {
|
| 31 |
+
position: fixed;
|
| 32 |
+
top: 45px;
|
| 33 |
+
left: 1580px;
|
| 34 |
+
}
|
| 35 |
+
}
|
| 36 |
+
|
| 37 |
+
|
| 38 |
+
article.pytorch-article section code {
|
| 39 |
+
padding: .2em .4em;
|
| 40 |
+
background-color: #f3f4f7;
|
| 41 |
+
border-radius: 5px;
|
| 42 |
+
}
|
| 43 |
+
|
| 44 |
+
/* Disable the change in tables */
|
| 45 |
+
article.pytorch-article section table code {
|
| 46 |
+
padding: unset;
|
| 47 |
+
background-color: unset;
|
| 48 |
+
border-radius: unset;
|
| 49 |
+
}
|
| 50 |
+
|
| 51 |
+
table.autosummary td {
|
| 52 |
+
width: 50%
|
| 53 |
+
}
|
| 54 |
+
|
| 55 |
+
img.align-center {
|
| 56 |
+
display: block;
|
| 57 |
+
margin-left: auto;
|
| 58 |
+
margin-right: auto;
|
| 59 |
+
}
|
| 60 |
+
|
| 61 |
+
article.pytorch-article p.rubric {
|
| 62 |
+
font-weight: bold;
|
| 63 |
+
}
|
docs/en/_static/image/logo.svg
ADDED
|
|
docs/en/_static/image/logo_icon.svg
ADDED
|
|
docs/en/_static/js/custom.js
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
var collapsedSections = [];
|
| 2 |
+
|
| 3 |
+
$(document).ready(function () {
|
| 4 |
+
$('.model-summary').DataTable({
|
| 5 |
+
"stateSave": false,
|
| 6 |
+
"lengthChange": false,
|
| 7 |
+
"pageLength": 20,
|
| 8 |
+
"order": []
|
| 9 |
+
});
|
| 10 |
+
});
|
docs/en/_templates/404.html
ADDED
|
@@ -0,0 +1,18 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
{% extends "layout.html" %}
|
| 2 |
+
|
| 3 |
+
{% block body %}
|
| 4 |
+
|
| 5 |
+
<h1>Page Not Found</h1>
|
| 6 |
+
<p>
|
| 7 |
+
The page you are looking for cannot be found.
|
| 8 |
+
</p>
|
| 9 |
+
<p>
|
| 10 |
+
If you just switched documentation versions, it is likely that the page you were on is moved. You can look for it in
|
| 11 |
+
the content table left, or go to <a href="{{ pathto(root_doc) }}">the homepage</a>.
|
| 12 |
+
</p>
|
| 13 |
+
<!-- <p>
|
| 14 |
+
If you cannot find documentation you want, please <a
|
| 15 |
+
href="">open an issue</a> to tell us!
|
| 16 |
+
</p> -->
|
| 17 |
+
|
| 18 |
+
{% endblock %}
|
docs/en/_templates/autosummary/class.rst
ADDED
|
@@ -0,0 +1,13 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.. role:: hidden
|
| 2 |
+
:class: hidden-section
|
| 3 |
+
.. currentmodule:: {{ module }}
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
{{ name | underline}}
|
| 7 |
+
|
| 8 |
+
.. autoclass:: {{ name }}
|
| 9 |
+
:members:
|
| 10 |
+
|
| 11 |
+
..
|
| 12 |
+
autogenerated from _templates/autosummary/class.rst
|
| 13 |
+
note it does not have :inherited-members:
|
docs/en/_templates/callable.rst
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
.. role:: hidden
|
| 2 |
+
:class: hidden-section
|
| 3 |
+
.. currentmodule:: {{ module }}
|
| 4 |
+
|
| 5 |
+
|
| 6 |
+
{{ name | underline}}
|
| 7 |
+
|
| 8 |
+
.. autoclass:: {{ name }}
|
| 9 |
+
:members:
|
| 10 |
+
:special-members: __call__
|
| 11 |
+
|
| 12 |
+
..
|
| 13 |
+
autogenerated from _templates/callable.rst
|
| 14 |
+
note it does not have :inherited-members:
|
docs/en/conf.py
ADDED
|
@@ -0,0 +1,234 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# flake8: noqa
|
| 2 |
+
# Configuration file for the Sphinx documentation builder.
|
| 3 |
+
#
|
| 4 |
+
# This file only contains a selection of the most common options. For a full
|
| 5 |
+
# list see the documentation:
|
| 6 |
+
# https://www.sphinx-doc.org/en/master/usage/configuration.html
|
| 7 |
+
|
| 8 |
+
# -- Path setup --------------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
# If extensions (or modules to document with autodoc) are in another directory,
|
| 11 |
+
# add these directories to sys.path here. If the directory is relative to the
|
| 12 |
+
# documentation root, use os.path.abspath to make it absolute, like shown here.
|
| 13 |
+
#
|
| 14 |
+
import os
|
| 15 |
+
import ast
|
| 16 |
+
import subprocess
|
| 17 |
+
import sys
|
| 18 |
+
|
| 19 |
+
import pytorch_sphinx_theme
|
| 20 |
+
from sphinx.builders.html import StandaloneHTMLBuilder
|
| 21 |
+
|
| 22 |
+
sys.path.insert(0, os.path.abspath('../../'))
|
| 23 |
+
|
| 24 |
+
# -- Project information -----------------------------------------------------
|
| 25 |
+
|
| 26 |
+
project = 'VLMEvalKit'
|
| 27 |
+
copyright = '2023, VLMEvalKit'
|
| 28 |
+
author = 'VLMEvalKit Authors'
|
| 29 |
+
|
| 30 |
+
# The full version, including alpha/beta/rc tags
|
| 31 |
+
version_file = '../../vlmeval/__init__.py'
|
| 32 |
+
|
| 33 |
+
|
| 34 |
+
def get_version():
|
| 35 |
+
with open(version_file, 'r') as f:
|
| 36 |
+
file_content = f.read()
|
| 37 |
+
# Parse the file content into an abstract syntax tree (AST)
|
| 38 |
+
tree = ast.parse(file_content, filename=version_file)
|
| 39 |
+
|
| 40 |
+
# Iterate through the body of the AST, looking for an assignment to __version__
|
| 41 |
+
for node in tree.body:
|
| 42 |
+
if isinstance(node, ast.Assign):
|
| 43 |
+
for target in node.targets:
|
| 44 |
+
if isinstance(target, ast.Name) and target.id == '__version__':
|
| 45 |
+
return node.value.s
|
| 46 |
+
raise ValueError('__version__ not found')
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
release = get_version()
|
| 50 |
+
|
| 51 |
+
# -- General configuration ---------------------------------------------------
|
| 52 |
+
|
| 53 |
+
# Add any Sphinx extension module names here, as strings. They can be
|
| 54 |
+
# extensions coming with Sphinx (named 'sphinx.ext.*') or your custom
|
| 55 |
+
# ones.
|
| 56 |
+
extensions = [
|
| 57 |
+
'sphinx.ext.autodoc',
|
| 58 |
+
'sphinx.ext.autosummary',
|
| 59 |
+
'sphinx.ext.intersphinx',
|
| 60 |
+
'sphinx.ext.napoleon',
|
| 61 |
+
'sphinx.ext.viewcode',
|
| 62 |
+
'myst_parser',
|
| 63 |
+
'sphinx_copybutton',
|
| 64 |
+
'sphinx_tabs.tabs',
|
| 65 |
+
'notfound.extension',
|
| 66 |
+
'sphinxcontrib.jquery',
|
| 67 |
+
'sphinx_design',
|
| 68 |
+
]
|
| 69 |
+
|
| 70 |
+
# Add any paths that contain templates here, relative to this directory.
|
| 71 |
+
templates_path = ['_templates']
|
| 72 |
+
|
| 73 |
+
# The suffix(es) of source filenames.
|
| 74 |
+
# You can specify multiple suffix as a list of string:
|
| 75 |
+
#
|
| 76 |
+
source_suffix = {
|
| 77 |
+
'.rst': 'restructuredtext',
|
| 78 |
+
'.md': 'markdown',
|
| 79 |
+
}
|
| 80 |
+
|
| 81 |
+
language = 'en'
|
| 82 |
+
|
| 83 |
+
# The master toctree document.
|
| 84 |
+
root_doc = 'index'
|
| 85 |
+
html_context = {
|
| 86 |
+
'github_version': 'latest',
|
| 87 |
+
}
|
| 88 |
+
# List of patterns, relative to source directory, that match files and
|
| 89 |
+
# directories to ignore when looking for source files.
|
| 90 |
+
# This pattern also affects html_static_path and html_extra_path.
|
| 91 |
+
exclude_patterns = ['_build', 'Thumbs.db', '.DS_Store']
|
| 92 |
+
|
| 93 |
+
# -- Options for HTML output -------------------------------------------------
|
| 94 |
+
|
| 95 |
+
# The theme to use for HTML and HTML Help pages. See the documentation for
|
| 96 |
+
# a list of builtin themes.
|
| 97 |
+
#
|
| 98 |
+
html_theme = 'pytorch_sphinx_theme'
|
| 99 |
+
html_theme_path = [pytorch_sphinx_theme.get_html_theme_path()]
|
| 100 |
+
|
| 101 |
+
# Theme options are theme-specific and customize the look and feel of a theme
|
| 102 |
+
# further. For a list of options available for each theme, see the
|
| 103 |
+
# documentation.
|
| 104 |
+
# yapf: disable
|
| 105 |
+
html_theme_options = {
|
| 106 |
+
'menu': [
|
| 107 |
+
{
|
| 108 |
+
'name': 'GitHub',
|
| 109 |
+
'url': 'https://github.com/open-compass/VLMEvalKit'
|
| 110 |
+
},
|
| 111 |
+
],
|
| 112 |
+
# Specify the language of shared menu
|
| 113 |
+
'menu_lang': 'en',
|
| 114 |
+
# Disable the default edit on GitHub
|
| 115 |
+
'default_edit_on_github': False,
|
| 116 |
+
}
|
| 117 |
+
# yapf: enable
|
| 118 |
+
|
| 119 |
+
# Add any paths that contain custom static files (such as style sheets) here,
|
| 120 |
+
# relative to this directory. They are copied after the builtin static files,
|
| 121 |
+
# so a file named "default.css" will overwrite the builtin "default.css".
|
| 122 |
+
html_static_path = ['_static']
|
| 123 |
+
html_css_files = [
|
| 124 |
+
'https://cdn.datatables.net/v/bs4/dt-1.12.1/datatables.min.css',
|
| 125 |
+
'css/readthedocs.css'
|
| 126 |
+
]
|
| 127 |
+
html_js_files = [
|
| 128 |
+
'https://cdn.datatables.net/v/bs4/dt-1.12.1/datatables.min.js',
|
| 129 |
+
'js/custom.js'
|
| 130 |
+
]
|
| 131 |
+
|
| 132 |
+
# -- Options for HTMLHelp output ---------------------------------------------
|
| 133 |
+
|
| 134 |
+
# Output file base name for HTML help builder.
|
| 135 |
+
htmlhelp_basename = 'vlmevalkitdoc'
|
| 136 |
+
|
| 137 |
+
# -- Options for LaTeX output ------------------------------------------------
|
| 138 |
+
|
| 139 |
+
latex_elements = {
|
| 140 |
+
# The paper size ('letterpaper' or 'a4paper').
|
| 141 |
+
#
|
| 142 |
+
# 'papersize': 'letterpaper',
|
| 143 |
+
|
| 144 |
+
# The font size ('10pt', '11pt' or '12pt').
|
| 145 |
+
#
|
| 146 |
+
# 'pointsize': '10pt',
|
| 147 |
+
|
| 148 |
+
# Additional stuff for the LaTeX preamble.
|
| 149 |
+
#
|
| 150 |
+
# 'preamble': '',
|
| 151 |
+
}
|
| 152 |
+
|
| 153 |
+
# Grouping the document tree into LaTeX files. List of tuples
|
| 154 |
+
# (source start file, target name, title,
|
| 155 |
+
# author, documentclass [howto, manual, or own class]).
|
| 156 |
+
latex_documents = [
|
| 157 |
+
(root_doc, 'vlmevalkit.tex', 'VLMEvalKit Documentation', author,
|
| 158 |
+
'manual'),
|
| 159 |
+
]
|
| 160 |
+
|
| 161 |
+
# -- Options for manual page output ------------------------------------------
|
| 162 |
+
|
| 163 |
+
# One entry per manual page. List of tuples
|
| 164 |
+
# (source start file, name, description, authors, manual section).
|
| 165 |
+
man_pages = [(root_doc, 'vlmevalkit', 'VLMEvalKit Documentation', [author],
|
| 166 |
+
1)]
|
| 167 |
+
|
| 168 |
+
# -- Options for Texinfo output ----------------------------------------------
|
| 169 |
+
|
| 170 |
+
# Grouping the document tree into Texinfo files. List of tuples
|
| 171 |
+
# (source start file, target name, title, author,
|
| 172 |
+
# dir menu entry, description, category)
|
| 173 |
+
texinfo_documents = [
|
| 174 |
+
(root_doc, 'vlmevalkit', 'VLMEvalKit Documentation', author,
|
| 175 |
+
'VLMEvalKit Authors', 'AGI evaluation toolbox and benchmark.',
|
| 176 |
+
'Miscellaneous'),
|
| 177 |
+
]
|
| 178 |
+
|
| 179 |
+
# -- Options for Epub output -------------------------------------------------
|
| 180 |
+
|
| 181 |
+
# Bibliographic Dublin Core info.
|
| 182 |
+
epub_title = project
|
| 183 |
+
|
| 184 |
+
# The unique identifier of the text. This can be a ISBN number
|
| 185 |
+
# or the project homepage.
|
| 186 |
+
#
|
| 187 |
+
# epub_identifier = ''
|
| 188 |
+
|
| 189 |
+
# A unique identification for the text.
|
| 190 |
+
#
|
| 191 |
+
# epub_uid = ''
|
| 192 |
+
|
| 193 |
+
# A list of files that should not be packed into the epub file.
|
| 194 |
+
epub_exclude_files = ['search.html']
|
| 195 |
+
|
| 196 |
+
# set priority when building html
|
| 197 |
+
StandaloneHTMLBuilder.supported_image_types = [
|
| 198 |
+
'image/svg+xml', 'image/gif', 'image/png', 'image/jpeg'
|
| 199 |
+
]
|
| 200 |
+
|
| 201 |
+
# -- Extension configuration -------------------------------------------------
|
| 202 |
+
# Ignore >>> when copying code
|
| 203 |
+
copybutton_prompt_text = r'>>> |\.\.\. '
|
| 204 |
+
copybutton_prompt_is_regexp = True
|
| 205 |
+
|
| 206 |
+
# Auto-generated header anchors
|
| 207 |
+
myst_heading_anchors = 3
|
| 208 |
+
# Enable "colon_fence" extension of myst.
|
| 209 |
+
myst_enable_extensions = ['colon_fence', 'dollarmath']
|
| 210 |
+
|
| 211 |
+
# Configuration for intersphinx
|
| 212 |
+
intersphinx_mapping = {
|
| 213 |
+
'python': ('https://docs.python.org/3', None),
|
| 214 |
+
'numpy': ('https://numpy.org/doc/stable', None),
|
| 215 |
+
'torch': ('https://pytorch.org/docs/stable/', None),
|
| 216 |
+
'mmengine': ('https://mmengine.readthedocs.io/en/latest/', None),
|
| 217 |
+
'transformers':
|
| 218 |
+
('https://huggingface.co/docs/transformers/main/en/', None),
|
| 219 |
+
}
|
| 220 |
+
napoleon_custom_sections = [
|
| 221 |
+
# Custom sections for data elements.
|
| 222 |
+
('Meta fields', 'params_style'),
|
| 223 |
+
('Data fields', 'params_style'),
|
| 224 |
+
]
|
| 225 |
+
|
| 226 |
+
# Disable docstring inheritance
|
| 227 |
+
autodoc_inherit_docstrings = False
|
| 228 |
+
# Mock some imports during generate API docs.
|
| 229 |
+
autodoc_mock_imports = ['rich', 'attr', 'einops']
|
| 230 |
+
# Disable displaying type annotations, these can be very verbose
|
| 231 |
+
autodoc_typehints = 'none'
|
| 232 |
+
|
| 233 |
+
# The not found page
|
| 234 |
+
notfound_template = '404.html'
|
docs/en/docutils.conf
ADDED
|
@@ -0,0 +1,2 @@
|
|
|
|
|
|
|
|
|
|
| 1 |
+
[html writers]
|
| 2 |
+
table_style: colwidths-auto
|
docs/en/index.rst
ADDED
|
@@ -0,0 +1,41 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Welcome to the VLMEvalKit Tutorial!
|
| 2 |
+
==========================================
|
| 3 |
+
|
| 4 |
+
VLMEvalKit Getting Started Guide
|
| 5 |
+
-------------------------------
|
| 6 |
+
|
| 7 |
+
To help users get started quickly, we recommend the following process:
|
| 8 |
+
|
| 9 |
+
- For users who want to use VLMEvalKit, we recommend reading the "Start Your First Step" section to set up the environment and start a mini-experiment to familiarize yourself with the process.
|
| 10 |
+
|
| 11 |
+
- If you want to customize more modules, such as adding datasets and models, we provide an "Advanced Tutorial."
|
| 12 |
+
|
| 13 |
+
We always welcome users' PRs (Pull Requests) and Issues to improve VLMEvalKit!
|
| 14 |
+
|
| 15 |
+
.. _Start Your First Step:
|
| 16 |
+
.. toctree::
|
| 17 |
+
:maxdepth: 1
|
| 18 |
+
:caption: Start Your First Step
|
| 19 |
+
|
| 20 |
+
Quickstart.md
|
| 21 |
+
|
| 22 |
+
.. _Advanced Tutorial:
|
| 23 |
+
.. toctree::
|
| 24 |
+
:maxdepth: 1
|
| 25 |
+
:caption: Advanced Tutorial
|
| 26 |
+
|
| 27 |
+
Development.md
|
| 28 |
+
ConfigSystem.md
|
| 29 |
+
|
| 30 |
+
.. _Other Notes:
|
| 31 |
+
.. toctree::
|
| 32 |
+
:maxdepth: 1
|
| 33 |
+
:caption: Other Notes
|
| 34 |
+
|
| 35 |
+
Contributors.md
|
| 36 |
+
|
| 37 |
+
Index and Tables
|
| 38 |
+
==================
|
| 39 |
+
|
| 40 |
+
* :ref:`genindex`
|
| 41 |
+
* :ref:`search`
|