Parameter-Efficient LLM Finetuning
Collection
Implementation of different PEFT methods for HW3
•
3 items
•
Updated
В этом репозитории представлен результат обучения LoRA в рамках курса по LLM от VK.
В данном эксперименте используется датасет cardiffnlp/tweet_eval. Решаемая задача - предсказание тональности текста (Sentiment Classification). Для файнтюна на задачу Sentiment Classification бралась в связи с особенностью QLoRA мы взяли модель побольше, чем в других экспериментах этой серии TinyLlama/TinyLlama-1.1B-Chat-v1.0.
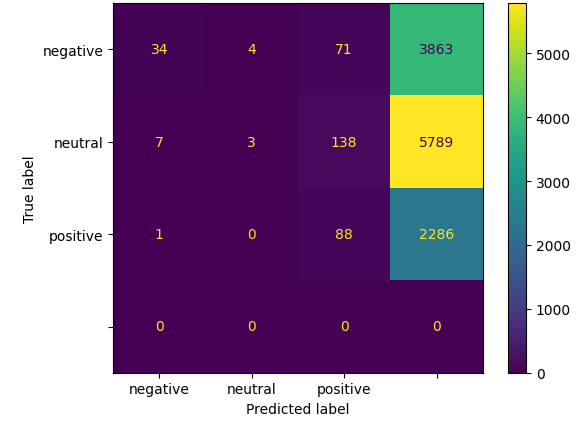
Отметим, что в zero-shot режиме качество предсказаний модели даже с учётом вспомогательных сценариев (некоторого парсинга ответов модели) остаётся довольно низким.
QLoRA - один из способов эффективного файнтюна модели. Идея, описанная в статье про LoRA довольно проста: мы можем выучить скелетные разложения матриц вместо полных матриц, что сильно сокращает число используемых параметров.
Основная идея модификации QLoRA заключается в том, что во время обратного распространения ошибки модель квантует исходные веса с точностью до 4 бит, что позволяет значительно сократить использование GPU памяти. Для обработки пиков памяти при этом применяются страничные оптимизаторы.