
VTP
Collection
Towards Scalable Pre-training of Visual Tokenizers for Generation
•
4 items
•
Updated
•
35
Jingfeng Yao1, Yuda Song2, Yucong Zhou2, Xinggang Wang1,*
1Huazhong University of Science and Technology
2MiniMax
*Corresponding author: [email protected]
Work still in Progress.
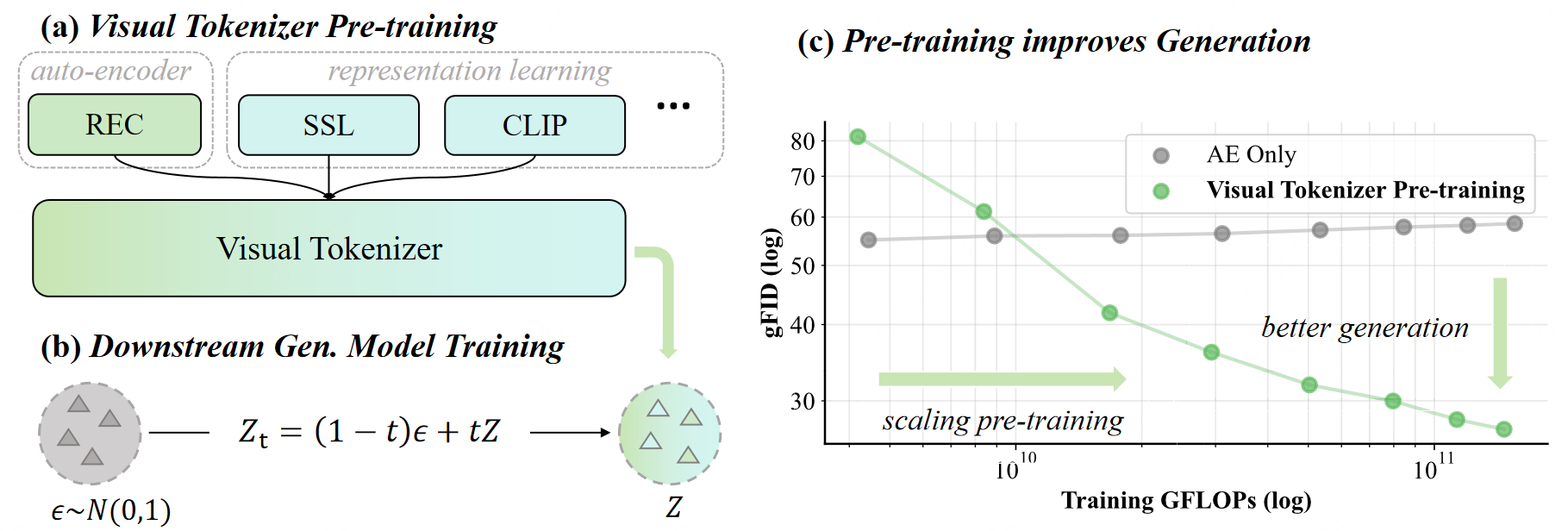
By integrating contrastive, self-supervised, and reconstruction learning, we have trained numerous visual tokenizers from scratch. We are seeking to unveil the novel scalability interlinking understanding, generation, and reconstruction.
Same FLOPs in DiT Training, VTP scaling helps better generation.
Traditional auto-encoders CANNOT be scaled up for diffusion generative models.
Understanding is the key driver for improving the learnability scaling.
Parameter, data and training scalability can be seen while representation learning involved.
| Checkpoints |
|---|
Weights will be released very soon.
pip install -r requirements.txt
import torch
from PIL import Image
from torchvision import transforms
from vtp.models.vtp_hf import VTPConfig, VTPModel
from vtp.tokenizers import get_tokenizer
model = VTPModel.from_pretrained("/path/to/MiniMaxAI/VTP-Large-f16d64")
model.eval()
# print model parameters
def count_params(m): return sum(p.numel() for p in m.parameters()) / 1e6
print(f"Vision Encoder: {count_params(model.trunk):.1f}M")
print(f"Pixel Decoder: {count_params(model.pixel_decoder):.1f}M")
print(f"Text Encoder: {count_params(model.text_transformer):.1f}M")
preprocess = transforms.Compose([
transforms.Resize((256, 256)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
image = preprocess(Image.open("figures/dog.png")).unsqueeze(0)
# ---------------------------------------------------------------------------------------
# use it as auto-encoder; rFID=0.36
# ---------------------------------------------------------------------------------------
denormalize = transforms.Normalize(
mean=[-0.485/0.229, -0.456/0.224, -0.406/0.225],
std=[1/0.229, 1/0.224, 1/0.225]
)
with torch.no_grad(), torch.autocast("cuda"):
latents = model.get_reconstruction_latents(image) # encode
recon = model.get_latents_decoded_images(latents) # decode
recon_image = denormalize(recon[0]).clamp(0, 1).permute(1, 2, 0).cpu().numpy()
Image.fromarray((recon_image * 255).astype("uint8")).save("output/reconstructed.png")
# ---------------------------------------------------------------------------------------
# use it as clip; zero-shot 78.2
# ---------------------------------------------------------------------------------------
tokenizer = get_tokenizer('ViT-B-32', context_length=model.config.text_context_length)
text = tokenizer(["a diagram", "a dog", "a cat", "a person"])
with torch.no_grad(), torch.autocast("cuda"):
image_features = model.get_clip_image_feature(image, normalize=True)
text_features = model.get_clip_text_feature(text, normalize=True)
text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1)
print("Label probs:", [f"{p:.4f}" for p in text_probs[0].tolist()])
# ---------------------------------------------------------------------------------------
# use it as ssl feature extractor; linear probing 85.7
# ---------------------------------------------------------------------------------------
with torch.no_grad(), torch.autocast("cuda"):
# get last layer features (cls token + patch tokens)
features = model.get_last_layer_feature(image)
cls_token = features['cls_token'] # (B, 1024)
patch_tokens = features['patch_tokens'] # (B, 256, 1024) for 256x256 image
# or get intermediate layer features for linear probing
intermediate = model.get_intermediate_layers_feature(
image, n=4, return_class_token=True
) # returns 4 x (patch_tokens, cls_token), each cls_token is (B, 1024)
for i in range(1, 5):
print('Last %d layers:' % i)
print('Patch tokens shape:', intermediate[-i][0].shape)
print('Cls token shape:', intermediate[-i][1].shape)
| Model | Understanding | Reconstruction | Generation | |
|---|---|---|---|---|
| Zero-shot Acc. | Linear Probing | rFID | LightningDiT-XL 80ep nocfg FID-50K |
|
| OpenCLIP | 74.0 | - | - | - |
| CLIP | 75.5 | - | - | - |
| SigLIP | 80.5 | - | - | - |
| MAE | - | 85.9 | - | - |
| DINOv2 | - | 86.7 | - | - |
| UniTok | 70.8 | - | 0.41 | - |
| VILA-U | 73.3 | - | 1.80 | - |
| VA-VAE-f16d32 | - | - | 0.28 | 4.29 |
| VA-VAE-f16d64 | - | - | 0.15 | - |
| RAE-f16d768 | - | 84.5 | 0.57 | 4.28 |
| VTP-S-f16d64 (ours) | 66.7 | 77.5 | 0.98 | 5.46 |
| VTP-B-f16d64 (ours) | 73.2 | 81.0 | 0.74 | 3.88 |
| VTP-L-f16d64 (ours) | 78.2 | 85.7 | 0.36 | 2.81 |
The quality of the latent space in visual tokenizers (e.g., VAEs) is crucial for modern generative models. However, the standard reconstruction-based training paradigm produces a latent space that is biased towards low-level information, leading to a foundation flaw: better pixel-level accuracy does not lead to higher-quality generation. This implies that pouring extensive compute into visual tokenizer pre-training translates poorly to improved performance in generation.
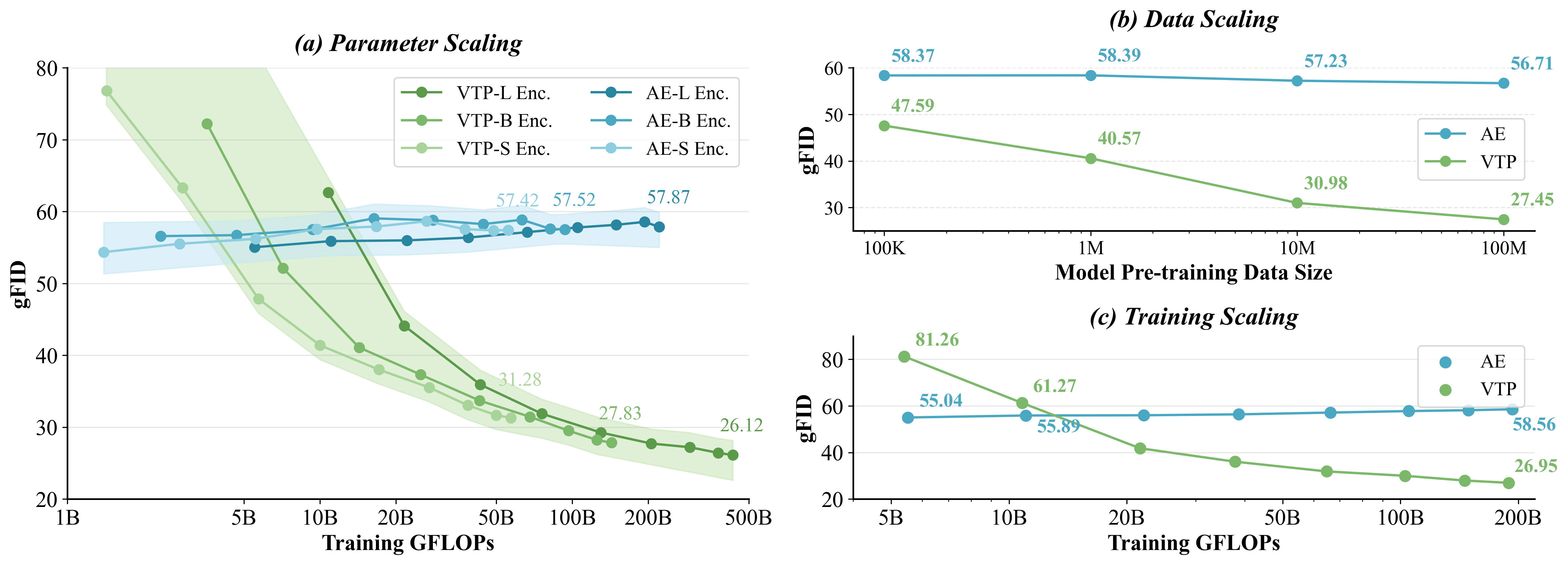
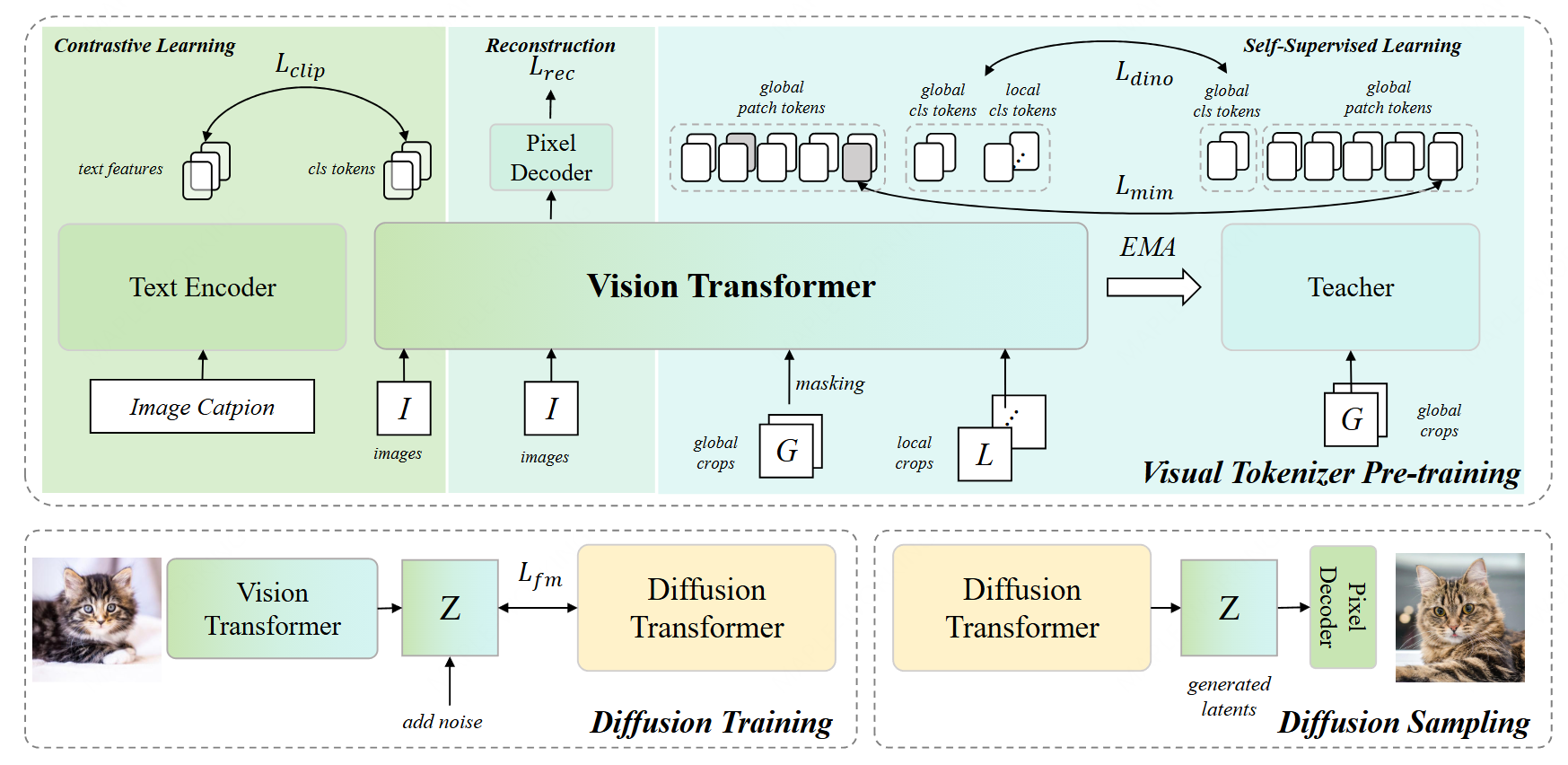
We identify this as the "pre-training scaling problem" and suggest a necessary shift: to be effective for generation, a latent space must concisely represent high-level semantics. We present visual tokenizer pre-training, VTP, a unified visual tokenizer pre-training framework, pioneering the joint optimization of image-text contrastive, self-supervised, and reconstruction losses. Our large-scale study reveals two principal findings: (1) understanding is a key driver of generation, and (2) much better scaling properties, where generative performance scales effectively with compute, parameters, and data allocated to the pretraining of the visual tokenizer. After large-scale pre-training, our tokenizer delivers a competitive profile (78.2 zero-shot accuracy, 0.36 rFID) and 3× faster convergence on generation compared to advanced distillation methods. More importantly, it scales effectively: without modifying standard DiT training specs, solely investing more FLOPS in pretraining VTP achieves 65.8% FID improvement in downstream generation, while conventional autoencoder stagnates very early at 1/10 FLOPS.
conda create -n vtp python=3.10
conda activate vtp
git submodule update --init --recursive
pip install -r requirements.txt
Modify the corresponding paths in scripts/test_zero_shot_hf.sh. Run:
bash scripts/test_zero_shot_hf.sh
Modify the corresponding paths in scripts/test_linear_probing_hf.sh. Run:
bash scripts/test_linear_probing_hf.sh
Modify the corresponding paths in scripts/test_reconstruction_hf.sh. Run:
bash scripts/test_reconstruction_hf.sh
We use LightningDiT codes to evaluate our generation performance.
Feature extraction:
bash generation/scripts/extract_features_vtp.sh generation/configs/train_vtp_l_dit_xl.yaml
LightningDiT training:
bash generation/scripts/train_lightningdit_vtp.sh generation/configs/train_vtp_l_dit_xl.yaml
LightningDiT sampling:
bash generation/scripts/inference_lightningdit_vtp.sh generation/configs/train_vtp_l_dit_xl.yaml
Our pre-training codes are built upon OpenCLIP and DINOv2. Our final model variant uses DINOv3 architecture.
We use LightningDiT for generation evaluation.
Thanks for their great codes.
@article{vtp,
title={Towards Scalable Pre-training of Visual Tokenizers for Generation},
author={Yao, Jingfeng and Song, Yuda and Zhou, Yucong and Wang, Xinggang},
journal={arXiv preprint arXiv:2512.13687},
year={2025}
}
Contact us at [email protected].