

Skywork-R1V
1. Introduction
We introduce Skywork-R1V, a multimodal reasoning model that extends the R1-series text models to visual modalities through a near-lossless transfer method. Using a lightweight visual projector, Skywork-R1V enables seamless multimodal adaptation without requiring retraining of either the base language model or vision encoder. To enhance visual-text alignment, we developed a hybrid optimization strategy combining Iterative Supervised Fine-Tuning (SFT) with Group Relative Policy Optimization (GRPO), significantly improving cross-modal integration. Additionally, we created an adaptive-length Chain-of-Thought distillation approach for generating reasoning data, which dynamically optimizes reasoning chain lengths to improve inference efficiency and prevent overthinking. The model achieves state-of-the-art performance on key multimodal reasoning benchmarks, scoring 68.1 on MMMU and 71.0 on MathVista, comparable to leading closed-source models like Gemini 2.0 and Kimi-k1.5. It also maintains strong textual reasoning capabilities, achieving impressive scores of 72.6 on AIME and 94.3 on MATH500.
2. Model Summary
Architecture: Skywork-R1V employs a modular architecture that efficiently combines vision and language capabilities:
- Vision Encoder: Uses Vision Transformer (ViT) as the visual backbone to process image inputs.
- Visual Projector: A lightweight MLP (multilayer perceptron) adapter that serves as the bridge between the vision and language components.
- Language Model: Utilizes R1-distilled-Qwen-32B as the reasoning-capable language model backbone.
The model follows a connection pattern of Vision Encoder → MLP Adapter → Language Model, where the MLP adapter aligns the output space of the vision encoder with the input space of the language model. This design allows for efficient transfer of reasoning capabilities from text to multimodal domains without requiring extensive retraining of either the vision encoder or language model.
Key Designs
- Advanced Multimodal Reasoning
Excels in complex reasoning across textual and visual modalities. - Iterative Training Strategies
Employs iterative supervision and grpo to refine model alignment and performance. - Adaptive length Chain-of-Thought
Dynamically adjusts reasoning length to enhance inference efficiency and accuracy. - Scalable Performance
Benchmarked to rival proprietary models across mathematics, coding, and multimodal tasks.
3. Evaluation
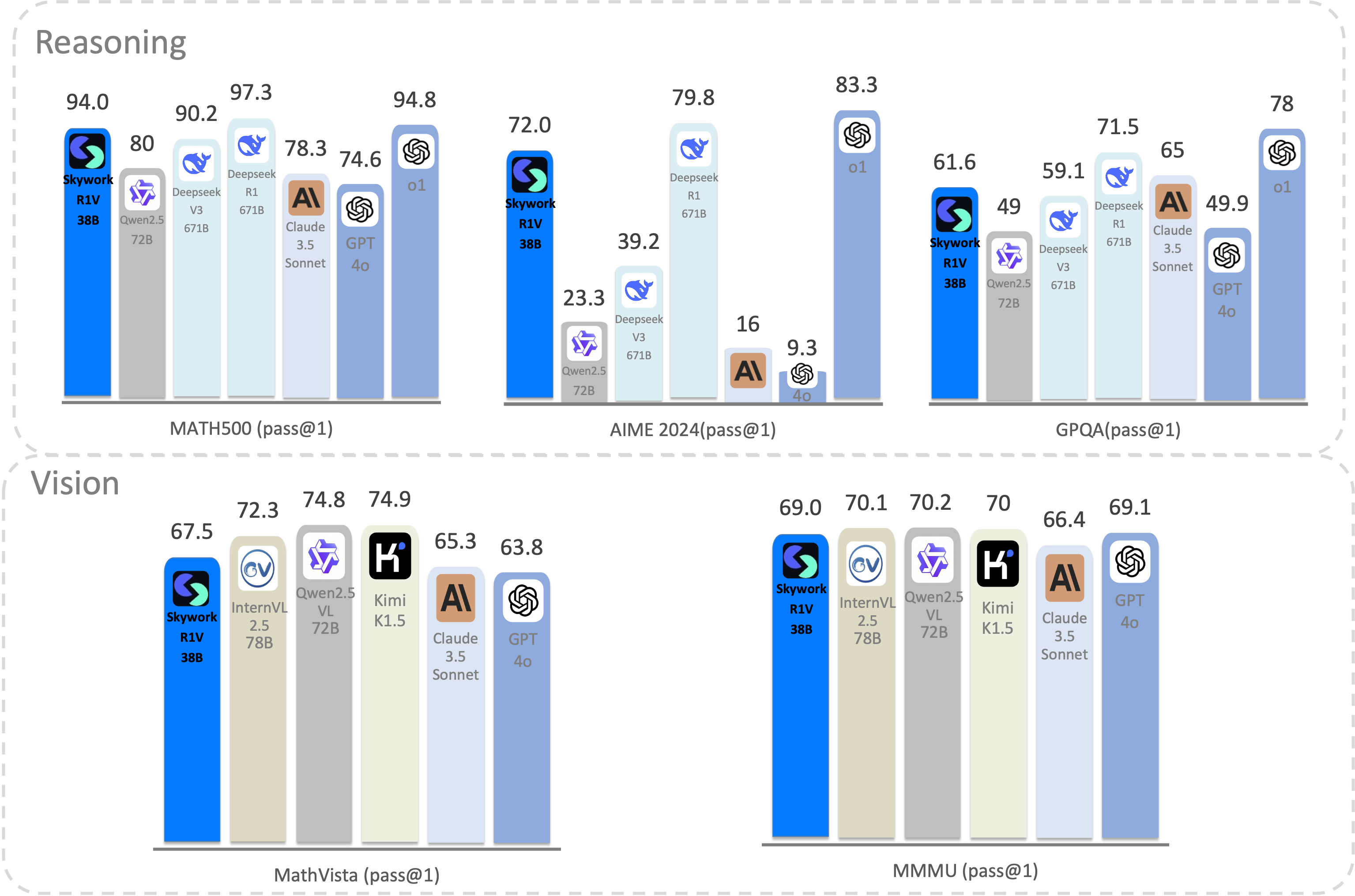
| Vision | Reasoning | Vision | |||||
|---|---|---|---|---|---|---|---|
| MATH-500 | AIME 2024 | GPQA | MathVista(mini) | MMMU(Val) | CSVQA | ||
| pass@1 | pass@1 | pass@1 | pass@1 | pass@1 | pass@1 | ||
| Qwen2.5-72B-Instruct | ❌ | 82.6 | 23.3 | 49.0 | - | - | - |
| Deepseek V3 | ❌ | 90.2 | 39.2 | 59.1 | - | - | - |
| Deepseek R1 | ❌ | 97.3 | 79.8 | 71.5 | - | - | - |
| Claude 3.5 Sonnet | ✅ | 78.3 | 16.0 | 65.0 | 67.7 | 68.3 | - |
| GPT-4o | ✅ | 76.6 | 9.3 | 53.6 | 63.8 | 69.1 | - |
| Kimi k1.5 | ✅ | 96.2 | 77.5 | - | 74.9 | 70.0 | - |
| Qwen2.5-VL-72B-Instruct | ✅ | - | - | - | 74.8 | 70.2 | - |
| LLaVA-Onevision-72B | ✅ | - | - | - | 67.5 | 56.8 | - |
| InternVL2-Llama3-76B | ✅ | - | - | - | 65.5 | 58.3 | - |
| InternVL2.5-78B | ✅ | - | - | - | 72.3 | 70.1 | - |
| Skywork-R1V-38B | ✅ | 94.0 | 72.0 | 61.6 | 71.0 | 68.1 | XXX |
| Benchmark | LLM | VLM | ||||
|---|---|---|---|---|---|---|
| QwQ-32B-Preview | InternVL-2.5-38B | VILA 1.5-40B | InternVL2-40B | Skywork-R1V-38B | ||
| Reasoning | MATH-500 | 90.6 | - | - | - | 94.0 |
| AIME 2024 | 50.0 | - | - | - | 72.0 | |
| GPQA | 65.2 | - | - | - | 61.6 | |
| Vision | MathVista(mini) | - | 71.9 | 49.5 | 63.7 | 71.0 |
| MMMU(Val) | - | 63.9 | 55.1 | 55.2 | 68.1 | |
| CSVQA | - | |||||
4. Skywork-R1V Family
| Model Name | Vision Encoder | Language Model | HF Link |
|---|---|---|---|
| Skywork-R1V-38B | InternViT-6B-448px-V2_5 | deepseek-ai/DeepSeek-R1-Distill-Qwen-32B | 🤗 Link |
| Skywork-R1V-38B-qwq | InternViT-6B-448px-V2_5 | Qwen/QwQ-32B | - |
5. Quick Start
This section describes how to quickly install, configure, and run the Skywork-R1V model.
Example Steps:
- Clone GitHub repository
git clone https://github.com/your-repo
- Install dependencies
cd your-repo
pip install -r requirements.txt
- Run example code
python demo.py
6. Additional Resources
7. Citation
If you use Skywork-R1V in your research, please cite:
@article{skywork2025r1v,
title = {Skywork-R1V: Bridging Vision and Language for Advanced Multimodal Reasoning},
author = {SkyworkVL Team},
year = {2025},
journal = {arXiv preprint arXiv:XXXX.XXXXX},
url = {https://github.com/skywork-ai/Skywork-R1V}
}
This project is released under an open-source license.