
video
video | label
class label 29
classes |
|---|---|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
0Apex_Legends
|
|
1Barony
|
|
1Barony
|
|
1Barony
|
|
1Barony
|
|
1Barony
|
|
1Barony
|
|
1Barony
|
|
1Barony
|
|
1Barony
|
|
1Barony
|
|
2Battlefield_6_Open_Beta
|
|
2Battlefield_6_Open_Beta
|
|
2Battlefield_6_Open_Beta
|
|
2Battlefield_6_Open_Beta
|
|
2Battlefield_6_Open_Beta
|
|
2Battlefield_6_Open_Beta
|
|
2Battlefield_6_Open_Beta
|
|
3Brotato
|
|
3Brotato
|
|
3Brotato
|
|
3Brotato
|
|
3Brotato
|
|
3Brotato
|
|
3Brotato
|
|
3Brotato
|
|
3Brotato
|
|
3Brotato
|
|
3Brotato
|
|
3Brotato
|
|
3Brotato
|
|
4Core_Keeper
|
|
4Core_Keeper
|
|
4Core_Keeper
|
|
4Core_Keeper
|
|
4Core_Keeper
|
|
4Core_Keeper
|
|
4Core_Keeper
|
|
5Counter-Strike_2
|
|
5Counter-Strike_2
|
|
5Counter-Strike_2
|
|
5Counter-Strike_2
|
|
5Counter-Strike_2
|
|
5Counter-Strike_2
|
|
5Counter-Strike_2
|
|
5Counter-Strike_2
|
|
5Counter-Strike_2
|
|
5Counter-Strike_2
|
|
6Cyberpunk_2077
|
|
6Cyberpunk_2077
|
|
6Cyberpunk_2077
|
|
6Cyberpunk_2077
|
|
6Cyberpunk_2077
|
|
6Cyberpunk_2077
|
|
6Cyberpunk_2077
|
|
7Dinkum
|
|
7Dinkum
|
|
7Dinkum
|
|
7Dinkum
|
|
7Dinkum
|
|
7Dinkum
|
|
7Dinkum
|
|
7Dinkum
|
|
7Dinkum
|
|
8Eternal_Return
|
D2E-480p
Project Page · Paper (arXiv) · GitHub · OWA Toolkit Documentation
This is the dataset for D2E: Scaling Vision-Action Pretraining on Desktop Data for Transfer to Embodied AI. 267 hours of synchronized video, audio, and input events from 29 PC games across diverse genres (FPS, open-world, sandbox, and more), for training vision-action models and game agents.
What's included:
- Video + Audio: H.264 encoded at 480p 60fps with game audio. Fixed 0.5s keyframe intervals and disabled B-frame for efficient random seek without sequential decoding.
- Input events: Keyboard (press/release + key state), mouse (clicks, screen coordinates, raw HID deltas, button state), and active window info—all with nanosecond timestamps synchronized to video frames.
- OWAMcap format: Built on MCAP (widely adopted in robotics). Indexed for fast random access, crash-safe writes, and standardized message schemas that work across different datasets without custom parsing.
Recommended for: Training game agents with vision-action trajectories, pretraining vision-action models for transfer to embodied AI (robotic manipulation, navigation), or world model / video generation training (use D2E-Original for HD/QHD).
⚠️ December 1, 2025: Dataset revised due to sync issues. Re-download if you obtained data before this date.
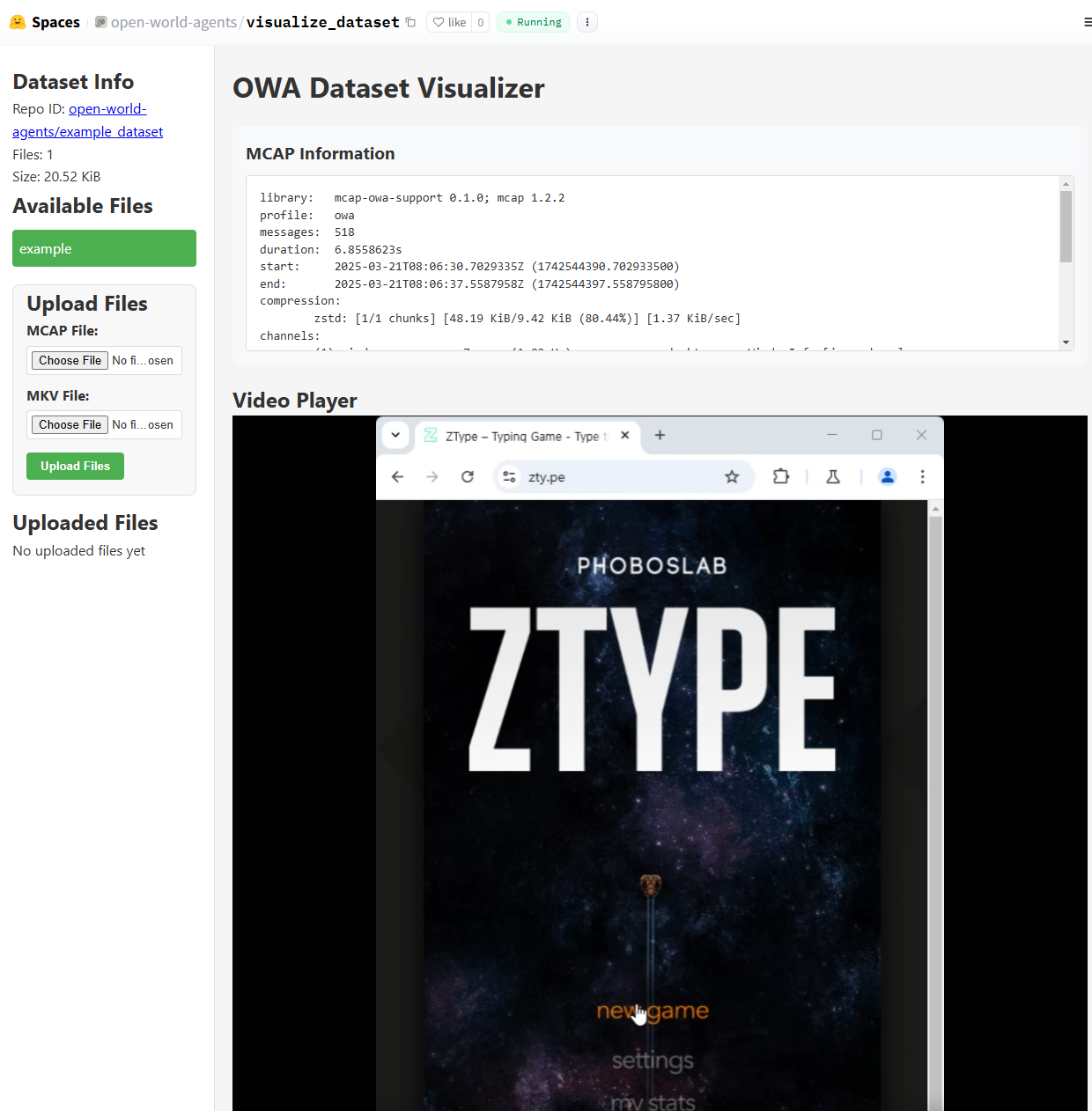
Visualize
Explore recordings directly in your browser with synchronized keyboard/mouse overlay: 👉 Open in Dataset Visualizer
Load the data
Install mcap-owa-support (OWAMcap reader), owa-msgs (message type definitions), and huggingface_hub:
pip install mcap-owa-support owa-msgs huggingface_hub
Then load and iterate through the data:
from huggingface_hub import hf_hub_download
from mcap_owa.highlevel import OWAMcapReader
mcap_file = hf_hub_download(
repo_id="open-world-agents/D2E-480p",
filename="Apex_Legends/0805_01.mcap",
repo_type="dataset"
)
with OWAMcapReader(mcap_file) as reader:
for msg in reader.iter_messages(topics=["screen"]):
screen = msg.decoded
screen.resolve_relative_path(mcap_file) # Resolve video path relative to mcap
frame = screen.load_frame_array() # numpy array (H, W, 3)
break
for msg in reader.iter_messages(topics=["keyboard"]):
print(msg.decoded) # KeyboardEvent(event_type='press', vk=87)
break
for msg in reader.iter_messages(topics=["mouse/raw"]):
print(msg.decoded) # RawMouseEvent(last_x=12, last_y=-3, button_flags=0)
break
Learn more: OWAMcap format guide
For training: We provide owa-data, a data pipeline that converts this dataset into HuggingFace Datasets ready for PyTorch DataLoader. It handles tokenization and sequence packing out of the box—so you can start training immediately without writing custom data loading code.
Structure
Each game folder contains paired .mcap + .mkv files:
Apex_Legends/
├── 0805_01.mcap # Timestamped events + frame references
├── 0805_01.mkv # Video + audio (480p 60fps, H.264)
├── 0805_02.mcap
├── 0805_02.mkv
└── ...
The .mcap file stores lightweight MediaRef pointers to video frames instead of raw pixels—frames are decoded on-demand from the .mkv when you call load_frame_array(). MCAP files contain timestamped messages on these topics:
| Topic | Message Type | Description |
|---|---|---|
screen |
desktop/ScreenCaptured |
Frame timestamp + MediaRef pointer to video |
keyboard |
desktop/KeyboardEvent |
Key press/release with virtual key code |
keyboard/state |
desktop/KeyboardState |
Currently pressed keys |
mouse |
desktop/MouseEvent |
Mouse clicks and screen coordinates |
mouse/raw |
desktop/RawMouseEvent |
Raw HID movement (→ why raw?) |
mouse/state |
desktop/MouseState |
Current position and button state |
window |
desktop/WindowInfo |
Active window title, rect, and handle |
Games
Genres: FPS (Apex Legends, PUBG), open-world (Cyberpunk 2077, GTA V), simulation (Euro Truck Simulator 2), sandbox (Minecraft), roguelike (Brotato, Vampire Survivors), and more. 29 games released (267h) from 31 games collected (335h) after privacy filtering.
| Game | Hours | Sessions |
|---|---|---|
| Apex Legends | 25.6 | 36 |
| Euro Truck Simulator 2 | 19.6 | 14 |
| Eternal Return | 17.1 | 31 |
| Stardew Valley | 14.6 | 10 |
| Cyberpunk 2077 | 14.2 | 7 |
| MapleStory Worlds | 14.1 | 8 |
| Rainbow Six | 13.7 | 11 |
| Grand Theft Auto V | 11.8 | 11 |
| Slime Rancher | 10.7 | 9 |
| Dinkum | 10.4 | 9 |
| Medieval Dynasty | 10.3 | 3 |
| Raft | 10.0 | 5 |
| Counter-Strike 2 | 9.9 | 10 |
| Satisfactory | 9.8 | 4 |
| Grounded | 9.7 | 4 |
| Ready Or Not | 9.6 | 11 |
| Barony | 9.3 | 10 |
| Core Keeper | 9.0 | 7 |
| Minecraft | 8.6 | 8 |
| Monster Hunter Wilds | 8.3 | 5 |
| Brotato | 6.0 | 13 |
| PUBG | 4.9 | 7 |
| Vampire Survivors | 2.8 | 2 |
| Battlefield 6 | 2.2 | 7 |
| Skul | 2.0 | 1 |
| PEAK | 1.8 | 2 |
| OguForest | 0.8 | 1 |
| Super Bunny Man | 0.7 | 2 |
| VALORANT | 0.3 | 1 |
For HD/QHD resolution, see D2E-Original.
Citation
@article{choi2025d2e,
title={D2E: Scaling Vision-Action Pretraining on Desktop Data for Transfer to Embodied AI},
author={Choi, Suwhan and Jung, Jaeyoon and Seong, Haebin and Kim, Minchan and Kim, Minyeong and Cho, Yongjun and Kim, Yoonshik and Park, Yubeen and Yu, Youngjae and Lee, Yunsung},
journal={arXiv preprint arXiv:2510.05684},
year={2025}
}
- Downloads last month
- 979